 2020-05-25
2020-05-25 1823
1823Оценка погрешности определения
К началу обработки результатов анализа методами математической статистики систематические погрешности должны быть выявлены и устранены или переведены в разряд случайных. Количественные определения, проводимые в учебных лабораториях студентами, должны использовать методики, прошедшие проверку на отсутствие систематических погрешностей. Поэтому в дальнейшем целесообразно говорить только о необходимости оценки повторяемости (сходимости), т.е. оценке случайных погрешностей.
Оценка повторяемости результатов определения (сходимости)
При оценке повторяемости, т.е выявлении случайных погрешностей исходят из представлений о бесконечно большом числе измерений. Это множество результатов называют генеральной совокупностью. На практике при проведении анализа одного и того же объекта имеют дело с ограниченным числом измерений (обычно 5-7). Это число составляет выборочную совокупность (выборка) из генеральной совокупности.
Многочисленными исследованиями показано, что данные большинства аналитических определений при наличии генеральной совокупности результатов химического анализа подчиняются закону нормального распределения (распределение Гаусса). Графическое изображение нормального распределения случайной величины показано на рис. 1. На оси абсцисс отложены значения определяемой величины (х), а на оси ординат – вероятность получения этих значений при анализе.
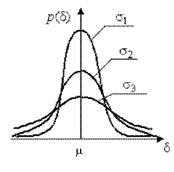 |
При большом числе измерений (неограниченный объем выборки) максимум кривой нормального распределения случайной величины (математическое ожидание - m) соответствует пределу, к которому стремится среднее значение определяемой величины (
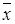 ) (см. рис. 1).
) (см. рис. 1). Рис.1
Воспроизводимость измерения характеризуется стандартным отклонением s или дисперсией s 2, характеризующим рассеяние случайной величины относительно математического ожидания (m). При отсутствии систематических погрешностей математическое ожидание равно истинному значению определяемой величины.
Вид колоколообразных кривых нормального распределения зависит от величины дисперсии и, следовательно, от стандартного отклонения. Чем больше стандартное отклонение, тем более пологой становится кривая нормального распределения случайной величины (см. рис.1).
При ограниченном числе измерений вместо m и s используют оценочные значения и s(х) (стандартное отклонение повторяемости).
представляет собой среднее арифметическое из всех полученных результатов определяемой величины и определяется по формуле
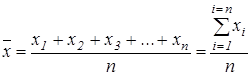 ,
,
где n – объем выборки (число повторных измерений).
Стандартное отклонение повторяемости (s(х)) рассчитывают по формуле
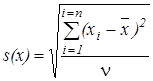 ,
,
где xi – значение определяемой величины, полученное вследствие единичного измерения;
- среднее арифметическое всех полученных результатов определяемой величины;
n - число степеней свободы. (n = n - m, где n – сумма всех определений, равная произведению числа проб на число измерений каждой пробы; m – число проб).
Число степеней свободы показывает число контрольных измерений, воспроизводящих первый результат. Если анализируется одна проба, то число степеней свободы n = n - 1, где n – объем выборки (число повторных измерений).
В случае, когда для анализа взята одна проба, стандартное отклонение повторяемости (s(х)) рассчитывают по формуле
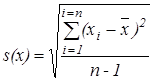 ,
,
При оценке повторяемости результатов многократного химического анализа принято приводить два статистических параметра – относительное стандартное отклонение результата определения (sr(х,%)) и ширину доверительного интервала, внутри которого могут лежать результаты определенных анализов с указанием доверительной вероятности того, что они попадают в этот интервал (± С(х)).
Относительное стандартное отклонение результата определения в процентах рассчитывают по формуле
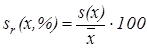
Доверительный интервал результата определения в условиях повторяемости зависит от числа степеней свободы (n, n = n – 1)) и уровня доверительной вероятности (Р) и рассчитывается по формуле:
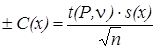 ,
,
где s(x) - стандартное отклонение повторяемости;
n – число параллельных определений;
t(P,n) – критерий Стьюдента, который находят по таблице в зависимости от числа степеней свободы (n) и уровня доверительной вероятности (Р). Значения коэффициентов Стьюдента приведены в таблице 1.
Доверительный интервал показывает пределы области среднего значения определяемой величины (), внутри которой при отсутствии систематических погрешностей может находиться истинное значение (m) с заданной степенью доверительной вероятности.
Таблица 1








