 2014-02-02
2014-02-02 3477
3477Определим еще некоторый класс языков — регулярных множеств. Соотношение его с классом А-языков определим позднее.
Пусть VT конечный алфавит. Регулярные множества в алфавите VT определяются рекурсивно:
1) Æ - регулярное множество;
2) {l} - регулярное множество;
3) {a} регулярное множество для любого aÎVT;
4) если P и Q - регулярные множества, то таковы также и множества: PÈQ, PQ, P*;
5) никаких других регулярных множеств нет.
По-другому можно определить регулярное множество как такое, которое можно получить из Æ, {l}, {a} и множеств, полученных на предыдущих шагах, путем конечного числа применений операций " È ", " × " и "*".
Определим теперь специальную нотацию для задания регулярных множеств.
Регулярные выражения в алфавите VT и регулярные множества, которые они обозначают, определяются рекурсивно:
1) 0 - регулярное выражение, обозначающее регулярное множество Æ.
2)1 - регулярное выражение, обозначающее регулярное множество {l},
3) если aÎ VT; то a - регулярное выражение, обозначающее регулярное множество {a};
4) если p и q - регулярные выражения, обозначающие регулярные множества P и Q то:
a) (p+q) - регулярное выражение, обозначающее регулярное множество PÈQ,
б) (pq) - регулярное выражение, обозначающее регулярное множество PQ,
в) (p*) - регулярное выражение, обозначающее регулярное множество P*;
5) никаких других регулярных выражений нет.
Как обычно, когда можно опустить лишние скобки без потери однозначности чтения, мы будем это делать. Так, 0+110* обозначает (0+((11)(0)*)). Мы будем придерживаться соглашения, что * обладает наивысшим приоритетом, затем • и, наконец, +.
Очевидно, что для каждого регулярного множества можно найти регулярное выражение, его обозначающее, и наоборот. К сожалению, как мы увидим дальше, одному и тому же регулярному множеству может соответствовать бесконечно много регулярных выражений.
Будем говорить, что регулярные выражения равны (обозначается значком =), если они обозначают одно и то же регулярное множество.
Запишем основные алгебраические тождества для регулярных выражений. Часть из них мы уже знаем, остальные легко доказываются. Если a, b, g - регулярные выражения, то:
1. a+a=a;
2. a+b=b+a;
3. a(bg)=(ab)g;
4. a+(b+g)=(a+b)+g;
5. a1=1a=a;
6. a0=0a=0;
7. (a+b)g=ag+bg;
8. a(b+g)=ab+ag;
9. a*=a+a*;
10. (a*)*=a*;
11. a*a* = a*
12. a*a =aa*
13. a+0=a
14. 1*=1
15. 0*=1;
16. (ab)*a=a(ba)*;
17. (a*b)*a*=(a+b)*=(a* +b*)*;
18. (a*b)*=(a+b)*b+1;
19. (ab*)*=a(a+b)* +1;
20. Если a = b*g, то a=b*a+g;
21. Если 1Ïb и a=ba+g, то a=b*g.
Последнее тождество является основным при решении уравнений.
Теорема (Клини). Каждому А-языку над V соответствует регулярное выражение над V. Каждому регулярному выражению над V соответствует А-язык.
Идея доказательства:
L – регулярное множество Þ L – А-язык.
- регулярное множество (грамматика с пустым множеством правил);
l - регулярное множество (S®l);
аÎ VT - регулярное множество (S®а);
если P, Q регулярные множества, то PÈQ, P Q, P* - так же регулярные множества (легко показать через соединение двухполюсников, порождающих языки, соответствующие P и Q.
L - А-язык Þ L – регулярное множество.
Пусть есть А-грамматика G=< VT,VN, S, R>,
Ai ® a1½ a2½… ak½ b1Aj1½ b2Aj2½ …½ bmAjm
где as, bqÎVT, AjsÎVN. Обозначим Xi - язык, порождаемый грамматикой Gi в которой в качестве начального символа выбран символ Аi. Тогда указанные правила эквивалентны следующему уравнению:
Xi = a1 + a2 + …+ ak + b1Xj1 + b2 Xj2 + … + bm Xjm.
Действительно, если Xi обозначает язык, порождаемый грамматикой Gi, когда Ai - начальный символ, то, так как возможны выводы Ai ® a1, Ai ® a2, Ai ® ak, можем написать, что a1, a2,…, akÎ Xi и, следовательно, Xi = a1 + a2 +…+ ak +… С другой стороны, пусть AjkÞxjk, т.е. xjkÎXjk, тогда возможен вывод Ai Þ+ bkAjk Þ+ bkxjk. Следовательно, bkxjkÎXi и это верно для любой цепочки xjkÎXjk. Поэтому, дополняя предыдущую запись Xi, можем написать:
Xi = a1 + a2 + …+ ak + b1Xj1 + b2 Xj2 + … + bm Xjm.
Полное доказательство проводится индукцией по числу правил грамматики.
Как по регулярному выражению построить А-грамматику?
Конкатенация моделируется последовательным соединением двухполюсников, + - параллельным соединением, * - l- замыканием. Т.о., последовательно выполняя операции, получим двухполюсники, соответствующие регулярному выражению. Построенные двухполюсники можно затем упростить.
Например, регулярным выражениям (a+b)c, (a+b)*c, (ab+bc)*(ab+c) будут соответствовать диаграммы, представленные на рис. 21 а, б, в соответственно.
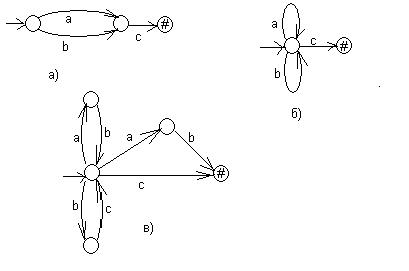
Рис.21
Обратная задача:
есть А-грамматика. Надо найти язык, порождаемый этой грамматикой, записанный в виде регулярного выражения.
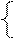 Например, имеется А-грамматика G12 с правилами:
Например, имеется А-грамматика G12 с правилами:
A® a A½bB
B ® b B ½ c
Обозначим язык, порождаемый грамматикой с начальным символом A - Xa, и язык, порождаемый грамматикой с начальным символом B – Xb.
Тогда соответствующие уравнения примут вид:
Xa = a Xa + b Xb
Xb = b Xb + c
Система уравнений может иметь бесконечно много решений, нас интересует минимальное по мощности решение.
Систему уравнений с регулярными коэффициентами назовем стандартной над множествомнеизвестных D={X1,X2,...Xn}, если она имеет вид
 X1 = a10 + a11 X1 + a12 X2 +... + a1n Xn;
X1 = a10 + a11 X1 + a12 X2 +... + a1n Xn;
X2 = a20 + a21 X1 + a22 X2 +... + a2n Xn;
…
Xn = a n0 + an1 X1 + an2 X2 +... + ann Xn;
где все a i j - регулярные выражения. Если какое-либо i-оеуравнение не содержит переменную Xj, то достаточно положить соответствующий коэффициент a i j = 0, если a i j =1, то его можно не писать.
В общем случае система уравнений имеет вид:
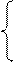 x1= f1(x1, x2,…,xn)
x1= f1(x1, x2,…,xn)
x2= f2(x1, x2,…,xn)
….
xn= fn(x1, x2,…,xn)
Где fi - конечная функция, xj – конечное множество строк над VT, на множестве x1, x2,…,xn определены операции объединения и конкатенации. Обозначим x1, x2,…,xn как Х, а систему X =F(X). Решение системы S =(S1,S2,…Sn) – совокупность подмножеств VT, такая, что S =F(S).
Определим S Í T = Df S1ÍT1, S2 ÍT2, …, Sn Í Tn.
Теорема. Система уравнений X =F(X) имеет решение S =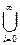 Fi(Æ). Если S1 – другое решение, то SÍS1.
Fi(Æ). Если S1 – другое решение, то SÍS1.
Определение: Говорим, что функция F: P(A)´P(A)® P(A) монотонно возрастает, если из A1ÍB1 и A2 ÍB2 следует, что F(A1,A2) Í F(B1,B2).
Лемма: Операция конкатенации – монотонно возрастающая функция.
Очевидно, что операция объединения так же является монотонно возрастающей функцией.
Т.к. Æ = (Æ,Æ, …,Æ), то Æ ÍF(Æ). Легко показать, что если A Í B, то F(A) Í F(B). Поэтому F(Æ)ÍF(F(Æ)) и т.д. Получаем возрастающую последовательность: Æ Í F(Æ) Í F2(Æ) Í F3(Æ) Í…
Пусть S =Fi(Æ). Тогда S =F(S). Если T - некоторое другое решение, то T = F(T), но Æ Í T, значит, F(Æ)Í F(T)= T. Очевидно, что по индукции можно доказать, что Fi(Æ)Í T для всех i, следовательно, Fi(Æ)Í T.
Пример: Рассмотрим систему
Xa = a Xa + b Xb
Xb = b Xb + c
Для удобства работы обозначим Xa – x, Xb – y.
f1(x,y)= ax + y;
f2(x,y)=by+c;
| f1(Æ,Æ)=Æ; f2(Æ,Æ)=c; | f1(Æ,c)=bc; f2(Æ,c)=bc+c; | f1(bc,bc+c)= abc+b(b+l)c f2(bc,bc+c)=(b2+b+l)c |
f1(abc+b(b+l)c, (b2+b+l)c) =(a+l)ab(bc+c)+b(b+l)2c
f2(abc+b(b+l)c, (b2+b+l)c) = (b3+b2+b+l)c
f1((a+l)ab(bc+c)+b(b+l)2c, (b3+b2+b+l)c)= (a+l)3ab(bc+c)+b(b3+b2+b+l)c
Откуда получаем
y=b*c
x=a*bb*c
Тем не менее основным способом решения стандартной системы уравнений - метод последовательного исключения неизвестных, подобным методу Гаусса. Покажем это на этом же примере.
Xa = a Xa + b Xb
Xb = b Xb + c
Из тождества 21 получаем
Xb=b*c
Xa = a Xa + b b*c= a*bb*c
Таким образом, существуют следующие основные способы задания А-языков:
А-грамматика.
Конечные лингвистические автоматы.
Стандартная система уравнений.
Регулярное выражение.

