 2014-02-02
2014-02-02 976
976Нотации для задания КС-грамматик.
Разрешимые проблемы для А-грамматик
Теорема:
Если L – А-язык, и ZÎL имеет длину, ³ числа состояний детерминированного автомата, то Z=WXY, где½X½³1и W Xi Y ÎL для всех i³0.
Доказательство: Пусть есть некоторый А-язык, и автомат ML, порождающий этот язык.
Q-{ q0,.q1,q2,…qn-1} – множество состояний автомата ML, n - число состояний автомата, q0 – начальное состояние автомата.
F(q0,Z)ÎK т.к. ZÎL. ½Z½³n, поэтому $qjÎQ, что Z=WXY, ½X½³ 1, F(q0,W)= qj, F(qj,X)= qj, F(qj, Y)ÎK. Но тогда F(q0,W XiY)ÎK для всех i³0, что требовалось доказать.
Теорема:
Проблема не пустоты для А-грамматик разрешима, т.е, если задана А-грамматика G, то существует алгоритм, позволяющий ответить на вопрос: L(G)= Æ?
Например, Из предыдущей теоремы, если L(G)¹Æ, то существует цепочка длины<n, где n – число состояний детерминированного автомата (хотя это и не оптимальное решение).
Теорема:
Проблема равносильности А-грамматик разрешима. т.е., если G1 и G2 – А-грамматики, то существует алгоритм, позволяющий определить, L(G1)=L(G2)?
Док-во: В случае равенства языков минимизированные детерминированные автоматы, построенные по этим грамматикам, будут совпадать с точностью до обозначений состояний.
Теорема:
Проблема конечности языка, порождаемого А-грамматикой, разрешима.
Обозначим множество состояний, достижимых из состояния Ai =H(Ai). Тогда, если
$ Ai, такое, что AiÎ H(q0)& Ai ÎH(Ai)&$ Aj Î H(Ai)& AjÎK, то язык, порождаемый автоматом, бесконечен.
Интересно отметить, что подобная теорема существует для КС-грамматик:
1. Математическая нотация (которую рассматривали до сих пор) – чистый синтаксис.
2. БНФ (Бекусова нормальная форма, или форма Бекуса — Наура) есть способ записи грамматики, который широко используется для описания синтаксиса языков программирования. В БНФ
2.1 нетерминальные символы записываются как имена, заключенные в угловые скобки < >.
2.2 Знак ® записывается как:: = (читается "заменяется на").
2.3 Альтернативы замены, соответствующие одному и тому же нетерминалу в левой части, отделяются друг от друга вертикальной чертой ½ (читается "или").
2.4 l не обозначается, для того, чтобы не пропыстить эту альтернативуЮ она обычно записывается первой в конструкции выбора.
Используя БНФ, описание идентификатора как произвольной последовательности букв и цифр, начинающейся с буквы, можно, например, записать:
<идентификатор> :: = <буква> | <буква> <продолжение>
<продолжение>::= < символ> | < символ> <продолжение>
<символ> ::= < буква> | <цифра>
<буква> :: = А | В | С|….| Z
<цифра> ::= 0 | 1 |... | 9
Или:
<идентификатор>::= <буква> <продолжение>
<продолжение>::= | < символ> <продолжение>
<символ> ::= < буква> | <цифра>
<буква> :: = А | В | С|….| Z
<цифра> ::= 0 | 1 |... | 9
При записи в виде грамматики G13 семантику увидеть сложнее(запись полностью соответствует последнему варианту БНФ):
S ® A B
B ® A B ½l
A ® C½D
C ® А | В | С|….| Z
D ® 0 | 1 |... | 9
Нетерминал БНФ может интерпретироваться как язык, который выводится, если рассматривать данный символ как начальный символ грамматики. БНФ может использоваться для описания синтаксиса любого языка, не только искусственного, например:
<Существительное > :: = <основа > <окончание>
<окончание >::= <окончание множественного числа>½< окончание единственного числа>…
Или:
<формула исчисления высказываний>::= <элементарная формула>½(<формула исчисления высказываний><бинарная операция> <формула исчисления высказываний>) ½(<отрицание
><формула исчисления высказываний>)
<элементарная формула>::= <константа>½<пропозициональная переменная>
<константа>::= 0½1
<пропозициональная переменная >::=a½b½…½z
<отрицание>::= N
<бинарная операция>::= &½Ú½Þ½Û
3. Часто применяется так называемая расширенная БНФ -РБНФ в которой используются также метасимволы (,); [,]; {,}. Ведение метасимволов позволяет сделать запись более лаконичной. Синтаксис РБНФ следующий
3.1 Нетерминалы записываются как последовательность символов.
3.2 Терминалы(последовательности символов) заключаются в кавычки.
3.3 Знак ®, используемый в математической записи грамматик, обозначается как =.
3.4 Альтернативы, как и в математической записи грамматик, разделяются знаком ½.
3.5 Конструкция, заключенная в [, ], является необязательной.
3.6 Конструкция, заключенная в {, } может повторяться произвольное число раз, от 0 (эквивалент * в регулярных выражениях).
3.7 () служат для факторизации, т.е. конструкция jy½gy может быть представлена в виде (j½g)y. Это позволяет использовать конструкцию выбора на более глубоком уровне.
Например, идентификатор в РБНФ будет описан как:
Идентификатор = буква {(буква½ цифра)}
буква = 'А’ | ‘В’ | ‘С’ |….| ‘Z’
цифра = ‘0’ | ‘1’ |... | ‘9’
Существительное описывается как
существительное = основа (окончание единственного числа½ окончание множественного числа)
Фактически, в правой части правил в РБНФ записывается некоторое регулярное выражение, в котором могут использоваться нетерминалы (т.е. расширение возможностей относительно выразительной мощности обычных регулярных выражений, т.к. обычные регулярные выражения позволяют описывать А-языки, а РБНФ – КС-языки.
4. Синтаксическая диаграмма. Синтаксическая диаграмма – графическая форма представления РБНФ. Для каждого нетерминала рисуется своя диаграмма. Приняты следующие обозначения:
4.1 Нетерминалы заключаются в прямоугольники.
4.2 Терминалы заключаются в овалы.
4.3 Образы нетерминалов и терминалов соединяются линиями (со стрелками или без, мы будем использовать стрелки для указания направления движения) т.о., чтобы множество путей соответствовало множеству цепочек из терминалов и нетерминалов, задаваемому РБНФ - правилами, для которых строится диаграмма.
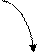
Диаграммы для конструкции выбора и итерации представлены на рис. 22, а и б, соответственно. Скругленный прямоугольник может быть заменен как прямоугольником (в случае нетерминала), так и овалом (в случае терминала).
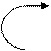
Набор диаграмм для идентификатора на рис. 23.
|


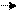



|

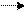
|
|
|
|
|
|
|
|
|
















а
б
Рис.22
Рис.23
В большинстве случаев существует не единственная форма представления для одних и тех же объектов.
Легко показать, что выразительная мощность РБНФ и БНФ совпадает:
| Условная запись РБНФ | Условная запись БНФ для данной РБНФ |
| А=j (y1½y2) | <А>::=<j>< y1>½<j ><y2> |
| А= [j ] y | <А>::=<j>< y>½< y> |
| А= {j } y | <А>::= <B ><y> <B>::= ½<j> < B> |
Цепочка – последовательность лексем(терминалов). Структура цепочки – способ задания семантики (смысла) правильной последовательности лексем (т.е. принадлежащей формальному языку).
Структура может выражать непосредственно семантические связи слов (для естественного языка), или, например, порядок вычислений (для арифметических выражений), вложенность конструкций (для языков программирования).
Например, для цепочки a´d2+c структура будет выражать порядок действий.
 |
Рис.24
Структура этой же цепочки может быть представлена в виде скобочной записи: (((a) ´ ((d)(2)))+ (c)).
Нас обычно интересует структура цепочки, построенной в некоторой конкретной грамматике G14.
Пусть дана грамматика G с множеством правил:
 S® T + S½T
S® T + S½T
T® M * T ½ M
M® (S) ½ i
Пусть анализируемая цепочка Х = i + i * i. Для неё можно построить несколько выводов, различающихся порядком замены нетерминалов, например: S ÞT +S Þ T + TÞ T+ M * TÞT + M * MÞ M + M * M Þi + M * MÞi + M * iÞi + i * i, или S ÞT +S Þ M + S Þ i + TÞi + M * TÞ i + i * T Þi + i * TÞi + i * MÞi + i * i.
Легко заметить, что по существу эти выводы различаются незначительно. Для придания единообразия процессу построения вывода определим:
Вывод, в котором на каждом шаге правило применяется к самому правому (левому) нетерминалу, назувается правым (левым) выводом. Второй из приведенных выводов для цепочки i + i * i является левым выводом, т.к. на каждом шаге правило применяется к самому левому нетерминалу.
Одна из форм представления вывода – синтаксические дерево.
Правила построения синтаксического дерева.
1. Каждому правилу вывода A®a1a2…anÎR, где ai - некоторые лексемы, сопоставляется куст.
|   A A | |||||
| a1 | a2 | … | an |

2. Строим дерево с корнем, растущее вниз. Корню дерева приписываем начальный символ.
3. Для каждого применяемого правила в выводе приклеиваем соответствующий куст к вершине построенного дерева.
4. Повторяем шаг 3 де тех пор, пока всем висячим вершинам будут сопоставлены терминалы.
Для грамматики G14 синтаксическое дерево для цепочки i + i * i представлено на рис. 25
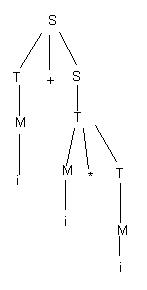
Рис.25
Теорема. Каждому выводу некоторой терминальной цепочки соответствует единственное синтаксическое дерево. Каждому синтаксическому дереву соответствует единственный правый (левый) вывод.
Доказательство:
- Для построенного вывода дерево единственно по построению.
- Пусть для данной цепочки имеется некоторое синтаксическое дерево. Построим левый вывод, соответствующий этому дереву. Для этого в дереве на каждом шаге применяем соответствующее правило к самому левому нетерминалу. Предположим, что одному дереву соответствует более одного правого (левого) вывода. Если существует 2 вывода, соответствующих этому дереву, то существует нетерминал, к которому применяются разные правила Þ соответствующие деревья будут различными. Поэтому каждому дереву соответствует единственный правый (левый) вывод.
Соответствие дерево – вывод не является взаимно-однозначным, т.к. порядок применения правил не задан и одному дереву может соответствовать более одного вывода, например, правый и левый.
Цепочка xÎL(G) называется неоднозначной в G, если для неё существует более одного синтаксического дерева в G. Грамматика G называется неоднозначной, если L(G) содержит неоднозначные в G цепочки.
Язык L называется неоднозначным, если для него не существует однозначной грамматики.
Например, L={anbncm, anbmcm, n,m ³1} – неоднозначный язык.
Регулярные выражения всегда задают однозначный язык (т.к. можно построить детерминированный автомат, и каждой цепочке – однозначному проходу по диаграмме – соответствует единственное синтаксическое дерево, т.к. это однозначный порядок применения правил).
Неоднозначные грамматики часто проще однозначных, но они пригодны только для построения цепочек, а не для их анализа, т.е. задания семантики.
Для задания структуры цепочек часто используются СУ-схемы, т.е. схемы синтаксически управляемого перевода. СУ- схема T=< Vвх,Vвых, VN, I, R>, где Vвх – входной алфавит, Vвых – выходной алфавит, VN – множество нетерминалов, I – начальный нетерминал, R={ A®j1,j2}, гдеAÎ VN, j1Î(VвхÈ VN)*, j2Î(VвыхÈ VN)*, а «,» - метасимвол, разделяющий j1 и j2. При этом количество и состав нетерминалов вj1 и j2 совпадают. Если в j1 более одного вхождения некоторого нетерминала А, то устанавливается соответствие между всеми вхождениями А в j1 и j2: А(1), А(2)…А(n).
СУ-схема называется простой, если порядок вхождений нетерминалов в j1 и j2 совпадают.
Вывод в СУ-схеме строится из пары начальных символов <I, I>. Определение выводимости в СУ-схеме подобно определению выводимости (выводимость за один шаг обозначаем Þ)для обычных грамматик:
<w1,d1>Þ <w2,d2> (из <w1,d1> непосредственно выводима <w2,d2>) Ûw1=q1 А q2, w2=q1 j1 q2,,d1=a1 А a2,,d2 =a1 j2 a2, и А®j1,j2 ÎR, при этом вхождения А в w1 и d1 –соответствующие.
Выводимость является рефлексивным и транзитивным замыканием непосредственной выводимости.
СУ-схема применяется к цепочке следующим образом: правила применяются одновременно к двум входным символам таким образом, чтобы до запятой получилась исходная цепочка, в этом случае после запятой получается перевод этой цепочки.
Перевод, порождаемый СУ-схемой Т:
t(T) = (<x,y>/ <I, I> Þ+ <x,y> & xÎVвх*, yÎVвых*}.
Из СУ—схемы T можно извлечь две грамматики Gвх=<Vвх, VN, I, Rвх> Rвх={A® j1/ A®j1,j2Î R} и
Gвых=<Vвых, VN, I, Rвых> Rвых={A® j2/ A®j1,j2Î R}.
СУ-схемы позволяют задавать структуры на уровне описания языка, где
t(T) = {<x,y>/ x – входная цепочка, y – выходная цепочка}.
Например, СУ-схема Т, описывающая перевод арифметического выражения, составленного с использованием символов сложения, умножения и скобок, в скобочную запись, отражающую порядок построения формулы (а следовательно, и порядок проведения вычислений), выглядит следующим образом.
S® T+S, (T+S)
S® T,T
T®M*T, (M*T)
T®M,M
M®(S),(S)
M®i,(i)
Применение данной СУ- схемы к цепочке i+i*i проиллюстрируем выводом(приводится левый вывод):
<S,S>Þ<T+S, (T+S)> Þ <M+S, (M+S)> Þ <i+ S, ((i)+S)> Þ <i+ T, ((i)+T)>Þ <i+ M*T, ((i)+ (M*T))> Þ <i+ i*T, ((i)+ ((i)*T))> Þ <i+ i*M, ((i)+ ((i)*M))> Þ <i+ i*i,((i)+ ((i)*(i)))>
В результате получается перевод цепочки, отражающий порядок её построения.
Можно построить СУ-схему для других преобразований цепочки, например, для построения по цепочке её обратной польской записи, например, соответствующая СУ-схема для построения обратной польской записи для цепочек, использующих только знаки умножения и сложения, выглядит следующим образом:
S® T+S, +TS
S® T,T
T®M*T, *MT
T®M,M
M®(S),S
M®i,i
Применение этой схемы к той же цепочке выглядит следующим образом:
<S,S>Þ<Т+S,+TS>Þ<M+S,+MS>Þ<i+S,+iS>Þ<i+T,+iT>Þ<i+ M*T,+i * M T >Þ<i+ i*M,+ * i i M >Þ<i+ i*i,+ * i i i >.
Следует обратить внимание, что в обоих случаях применяемые СУ-схемы были простыми.








