 2014-02-02
2014-02-02 4845
4845НОРМЫ
УСЛОВНЫЕ ЧАСТОТЫ
Простые частоты являются не самой подходящей оценкой текстов. Проблемы с ними могут возникнуть в том случае, если мы захотим сравнить разные по длине тексты. Например, пусть в некотором тексте t1 длиной в 1000 слов категория НЕГАТИВ встречается с частотой 20, а в тексте t2 длиной в 10000 слов — с частотой 100. Является ли пятикратная разница частот достаточным основанием для утверждения, что текст t2 окрашен более негативно, чем текст t1? Очевидно, что нет. Для вынесения такого утверждения необходимо сравнивать не простые частоты, а условные, т. е. доли, которые составляет категория НЕГАТИВ в первом и втором тексте.
Условную частоту характеристики c в тексте t обозначим посредством pr(c,t). Вычисляется она по формуле:
pr(c,t) = f(c,t) / L(t), где L(t) – длина текста t.
В зависимости от того, что принято за элементы содержания, в качестве длины текста может быть взято общее количество в нем слов, предложений, абзацев и т. д. Если характеристика — это отдельное слово или категория слов, то и в качестве длины текста берется количество слов в нем.
В нашем примере pr(НЕГАТИВ, t1) = 20 / 1000 = 0,02 больше, чем pr(НЕГАТИВ, t2) = 100 / 10000 = 0,01. То есть более негативно окрашенным является не второй, а первый текст.
Иногда вместо условных частот удобнее использовать оценку процентного содержания. Для этого просто умножают условную частоту на 100 и тем самым получают процентное содержание.
Переход от использования простых частот к условным значительно расширяет сферу применимости методов контент-анализа. Если раньше все наши примеры имели дело с текстами одинаковой длины, то теперь это ограничение снято. Теперь мы можем сравнивать разные по длине статьи, разные по объему издания и пр.
До сих пор для того, чтобы делать какие-то выводы, нам требовалось оценить как минимум два текста. Затем эти оценки либо сопоставлялись между собой, либо соотносились с некоторыми событиями в реальном мире и на основании этого делались определенные выводы.
Представим, что перед нами поставлена задача классификации текстов по медицинской и немедицинской тематике. Причем требуется, чтобы это делал не человек, а компьютер. Решение довольно очевидно. Текст должен быть отнесен к медицинским в том случае, если частота встречаемости медицинских терминов в нем существенно выше, чем в обычной речи. Для этого следует сформировать категорию медицинских терминов Km и сопоставить ей условную частоту встречаемости в обычной речи pr(Km, речь), которую назовем нормой для категории Km. При анализе конкретного текста t подсчитывается условная частота pr(Km, t). Если она существенно больше нормы pr(Km, речь), то текст t относят к медицинской тематике. Аналогичная процедура может быть применена для дальнейшей классификации текстов по различным разделам медицины. Достаточно лишь сформировать соответствующие категории и сопоставить им нормы, но уже на основании не обычной речи, а анализа представительной выборки различных медицинских текстов. Задача по формированию норм облегчается тем, что в настоящее время существует довольно много частотных словарей, относящихся к различным сферам человеческой деятельности, и нормы можно извлекать из них. Нормы можно вычислять и для отдельных людей. Они могут оказаться весьма полезными, например, для определения душевного состояния человека. Так, превышение в речи относительно личной нормы частоты категории НЕГАТИВ может свидетельствовать о том, что человек находится в дурном настроении.
Важно подчеркнуть, что понятие нормы всегда относительно. Для сугубо гражданского человека норма частоты употребления агрессивно окрашенной лексики одна, для профессионального военного — другая. Нормы могут меняться не только от одной профессионально определенной группы людей к другой, но и со временем. Причиной тому служат исторические изменения в жизни общества, отмирание старых идей и появление новых, заимствования из других языков, влияние на лексический состав языка таких факторов, как общественная мораль и пр.
Более строго понятие нормы можно определить следующим образом. Имеется некоторое множество текстов T, которые объединены вместе по определенному признаку. Нас интересует норма характеристики с для T. Так как множество текстов Т может быть слишком велико или недоступно целиком, то из него берется представительная конечная выборка  и уже для нее вычисляется условная частота pr(c, V). Это и будет принято в качестве нормы характеристики с для Т, которую мы обозначим посредством nr(с, Т). Норма характеристики с для множества текстов Т — это ожидаемая условная частота ее встречаемости в произвольном тексте, принадлежащем данному множеству. Для представления того, как сильно отличается от ожидаемой частота встречаемости характеристики с в конкретном тексте
и уже для нее вычисляется условная частота pr(c, V). Это и будет принято в качестве нормы характеристики с для Т, которую мы обозначим посредством nr(с, Т). Норма характеристики с для множества текстов Т — это ожидаемая условная частота ее встречаемости в произвольном тексте, принадлежащем данному множеству. Для представления того, как сильно отличается от ожидаемой частота встречаемости характеристики с в конкретном тексте 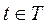 , используются следующие оценки:
, используются следующие оценки:
pn(c, t, T) = pr(c, t) / nr(c, T) — во сколько раз отличается pr(c, t) от nr(с, Т);
pd(c, t, T) = [[pr(c, t) — nr(c, T)] / nr(c, T)] * 100 — на сколько процентов отличается pr(c, t) от nr(с, Т).
Аналитика в первую очередь интересуют те тексты, для которых оценка pn(c, t, T) существенно отличается от 1 или же оценка pd(c, t, T) существенно отличается от 0. При этом дополнительного уточнения требует термин существенно отличаться. На помощь приходит аппарат математической статистики. Обычно считают, что характеристика с имеет в тексте t биномиальное распределение с вероятностью nr(с, Т). Пусть реально в тексте t характеристика с встретилась pr(c, t) * L(t) раз, в то время как ожидалось nr(c, T) * L(t). Исходя из свойств биномиального распределения легко подсчитать, насколько мала вероятность того, что для произвольного текста ti абсолютная величина abs(pr(c, ti) — nr(c, T)) * L(ti)  abs(pr(c, t) — nr(c, T)) * L(t). Если вычисленная таким образом вероятность не превышает порога 0,05 (или 0,01), считается, что отклонение реальной частоты от ожидаемой существенно, т. е. не является случайным.
abs(pr(c, t) — nr(c, T)) * L(t). Если вычисленная таким образом вероятность не превышает порога 0,05 (или 0,01), считается, что отклонение реальной частоты от ожидаемой существенно, т. е. не является случайным.
На практике гораздо чаще используют оценку, вычисляемую по формуле:
z(c, t, T) = [pr(c, t) - nr(c, T)] / SQRT[pr(c, t) * (l - pr(c, t)) / L(t)]
Это разница двух условных частот, нормированная по стандартному отклонению. Ее имеет смысл использовать лишь в том случае, если pr(c, t) * (l—pr(c, t)) * L(t) 25. Эта оценка хорошо известна психологам и социологам. Именно с ее помощью обосновываются методы вычисления баллов многих психологических тестов. Если abs(z(c, t, T)) l,96, то мы сразу можем сказать, что вероятность данного события не превышает 0,05. Если же abc(z(c, t, T)) 2,58, то вероятность этого события еще меньше и не превышает 0,01. Из формулы видно, что данная оценка прямо пропорциональна корню квадратному из длины текста t. Именно поэтому ее можно использовать для определения того, что данное событие не является случайным, но не для оценки того, насколько велико отклонение реальной частоты от ожидаемой. К сожалению, многие психологи и социологи не различают этого и потому их выводы очень далеки от научности. В применении к методам психологического тестирования замечательную критику по этому вопросу дал А.Г. Шмелев (1).
Основная идея контекстного анализа заключается в том, что анализу подвергается не весь текст, а лишь некоторая выборка из него, являющаяся контекстом употребления характеристики с. Есть много способов задать контекст. Например, для слова (характеристики) w в качестве его контекста мы можем взять все предложения (абзацы, статьи, книги), в которых оно встречается. Вместо предложений мы можем считать контекстом по одному или более слов слева и справа от каждого вхождения w в текст.
Если текст t рассматривать как множество предложений, а предложение s рассматривать как множество слов, то контекст категории C в тексте t можно определить как
ctx(C, t) = {s - {w} | w 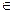 С, ws, st}.
С, ws, st}.
Выделенный контекст может анализироваться как самостоятельно, так и относительно основного текста. Во втором случае основной текст служит источником норм, которые затем используются при анализе контекста, т.е. для произвольной категории K мы интересуемся условной частотой pr(K, ctx(C, t)) и сравниваем ее с нормой nr(K, t), вычисляемой как: pr(K,t — {С}), где t — {C} = {s - {w} | wC, st}.
Дополнительно к этому мы можем выделить множество слов col(C, t) = {w | pr(w, ctx(C, t)) существенно больше pr(w, t - {С})}.
В англоязычной литературе по контент-анализу такое множество называется collocation категории С. Отношение существенно больше валидизируется с помощью аппарата математической статистики по аналогии с тем, как это описывалось выше. Множество col(C, t) содержит много полезной информации о категории С. Например, col({змея}, речь) будет включать в себя такие слова, как яд, кусать, ползать, пресмыкающееся,..., а в col({Путин}, СМИ) войдут слова Владимир, президент, Кремль, Россия, …

