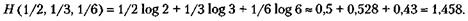2014-02-02
2014-02-02 1190
1190Основание логарифма может быть взято произвольно, но удобнее всего логарифмировать по основанию 2, в этом случае единица информации называется битом.
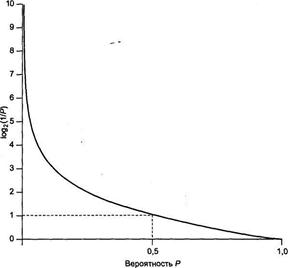 |
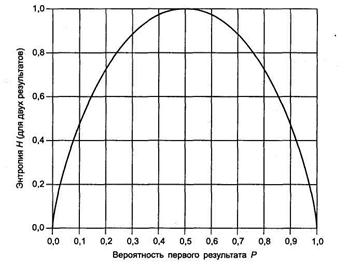
На рисунке показан график зависимости количества информации единичного события от вероятности этого события. Когда вероятность события приближается к единице (событие происходит почти наверняка), количество информации, содержащееся в данном событии, приближается к нулю. И наоборот, когда вероятность события приближается к нулю (событие практически невероятно), количество информации, содержащееся в данном событии, приближается к бесконечности.
Другая важная концепция теории информации — энтропия. Эта концепция была предложена в 1948 г. основателем теории информации Шенноном (Shannon). Шеннон определил энтропию как среднее количество информации, получаемое от значения случайной переменной. Предположим, что имеется случайная переменная X, способная принимать значения х1 х2,..., xN, и что соответствующие вероятности каждого исхода равны P(x1), P(x2),..., P(xN). В последовательности из К переменных X результат Xj в среднем будет выбран KP(Xj) раз. Таким образом, среднее количество информации, получаемое от К событий, равно (будем использовать обозначение Pj для P(xj)):
KPi log (1/P1) +... + KPNlog (1/PN).
Если разделить это выражение на К, то мы получим среднее количество информации для одного результата случайной переменной, называемое энтропией X и обозначаемое как Н(Х):
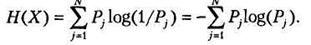
Функция Н часто выражается как перечень вероятностей возможных результатов: H(P1, Р2,..., Pn).
Для примера рассмотрим случайную переменную X, принимающую два возможных значения с соответствующими вероятностями Р и 1 - Р. В этом случае ассоциированная с X энтропия будет равна:
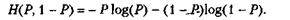
На рисунке ниже, показан график H(X) для данного случая как функция от Р. По этому графику можно отметить несколько важных особенностей энтропии. Во-первых, если одно из двух событий является достоверным (Р= 1 или Р=0), тогда энтропия равна нулю. Одно из двух событий должно произойти, и никакой информации о том, что одно из них произошло, не содержится. Во-вторых, максимального значения функция H(X) достигает, когда два результата равновероятны. Это также обоснованно: когда два результата равновероятны, неуверенность в результате максимальна. Этот результат можно обобщить для случайной переменной с N результатами. Энтропия случайной переменной будет максимальна, когда все результаты равновероятны:
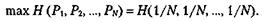
Например,
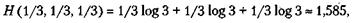
тогда как