 2014-02-02
2014-02-02 696
696Предположим, что у нас есть источник, генерирующий символы из алфавита X, состоящего всего из двух символов А и В, встречающихся с вероятностью 0,8 и 0,2. Энтропия при такой схеме составляет 0,8 log(l,25) + 0,2 log(5) = 0,722. Но лучшее, что можно сделать в данном случае, — это использовать по одному биту для каждого кодового слова (например, А = 0, В = 1). Если определить эффективность кода как отношение энтропии источника (среднее число битов информации в символе) к средней длине кодового слова (среднее число битов, используемых для кодирования одного символа), тогда эффективность этого кода будет равна 0,722.
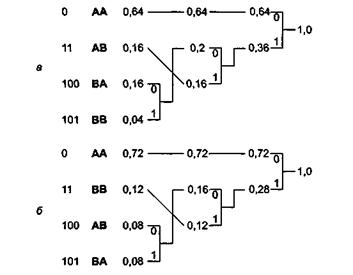
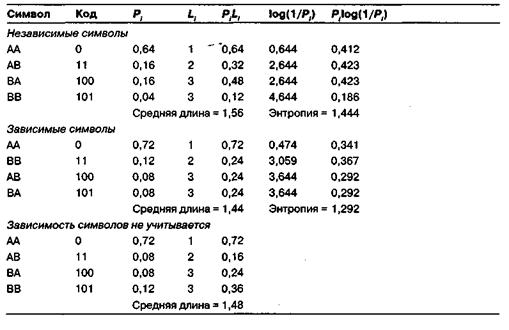
Эффективность кода можно повысить, если объединить символы в блоки и кодировать эти блоки символов. Например, если мы будем кодировать по два символа одновременно, тогда можно рассматривать полученные в результате блоки символов как новый алфавит Y, состоящий из четырех символов (АА, АВ, ВА, ВВ). Если символы алфавита X следуют в сообщениях независимо друг от друга, тогда вероятности, с которыми в них встречаются символы алфавита Y, будут равны: Раа = 0,64; РАв = 0,16; Рва = 0,16; РВв = 0,04. На рисунке показан код Хаффмана для такого варианта объединения символов в блоки, а в верхней части таблицы ниже статистика этого кода. В результате мы получаем код со средней длиной 1,56 при энтропии, равной 1,444, таким образом, эффективность кода составляет 0,926, что значительно лучше, чем при кодировании исходных символов без группировки. Обратите внимание на то, что информация источника не изменилась. Энтропия случайной переменной X равна 0,722, а энтропия К равна 0,722 • 2 = 1,444, то есть все также по 0,722 бита на символ. Еще лучших результатов можно достичь, объединив символы по три. В данном случае эффективность кода составит 2,167/2,128 = 0,992. Энтропия все также будет составлять 0,722 бит на символ (2,167/3).
Можно показать, что эффективность оптимального кода для независимых последовательностей символов может быть повышена путем объединения символов, как это было показано ранее. Для блока из К символов мы получим следующее соотношение:
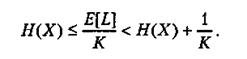
Таким образом, среднее количество битов на одно значение случайной переменной X можно сделать сколь угодно близким к энтропии, выбирая все большие размеры блоков.








