2014-02-02
2014-02-02 2474
2474Кодирование
Одно из важных приложений концепции энтропии заключается в том, что эта концепция помогает понять принциды работы алгоритмов сжатия данных. Энтропия случайной переменной или источника сообщений определяет количество битов, требуемых для представления результатов случайной переменной или альтернативных сообщений без потери информации. Таким образом, при разработке алгоритма сжатия данных энтропия представляет собой меру максимально возможного.
Рассмотрим случайную переменную X, принимающую одно из восьми возможных значений (х1,x2, …, х8) со следующими вероятностями:
P1 = 0,512, Р5 = 0,032,
Р2 = 0,128, Р6 = 0,032,
Р3 = 0,128, Р7 = 0,032,
Р4 = 0,128, Р8 = 0,008.
Здесь Pi представляет собой вероятность выпадения результата хi. Предположим, что сообщение состоит из реализаций случайной переменной X, и мы хотели бы закодировать сообщение в двоичном виде. Один очевидный вариант решения заключается в том, чтобы использовать 3-битовый код фиксированной длины, в котором каждое из восьми возможных значений случайной переменной X кодируется одним 3-битовым числом. Лучшая стратегия заключается в использовании кода переменной длины, в котором более длинные кодовые слова назначаются менее вероятным значениям X, а более вероятные значения X кодируются короткими кодовыми словами. Такой технический прием применяется в азбуке Морзе и коде Хаффмана. Предположим, что сообщения должны передаваться при помощи алфавита из N символов. Каждый символ должен уникальным образом кодироваться двоичной последовательностью. Нас интересует способ построения оптимального кода, то есть кода, дающего в результате минимальную среднюю длину кодируемого сообщения. Важно отметить, что мы не ищем минимальную длину кода для какого-либо конкретного сообщения или для всех сообщений (последнее найти невозможно), но минимальную длину кода, усредненную по всем возможным сообщениям.
Другой способ взглянуть на данные требования состоит в том, что мы получаем сообщение, уже закодированное путем назначения символам двоичных слов фиксированной длины. Таким образом, если символов 8, каждый символ кодируется тремя битами. Если число символов в алфавите от 9 до 16, то каждый символ кодируется четырьмя битами и т. д. Такое кодирование не является оптимальным, если символы встречаются в сообщениях с разной вероятностью. В этом случае требование может быть сформулировано следующим образом. Требуется разработать оптимальную схему кодирования с использованием кода переменной длины, позволяющую получить кодированное сообщение минимальной средней длины.
Рассмотрим двоичный код с кодовыми длинами L1, L2 …LN, поставленный в соответствие алфавиту из N символов с вероятностями Р1, Р2,..., РN. Для удобства предположим, что символы организованы в порядке убывания вероятности (P1 >= Р2>=... >= Pn). Можно показать, что оптимальный код должен удовлетворять следующим требованиям:
· Никакие два разных сообщения не должны состоять из одинаковых после
довательностей битов.
· Никакое кодовое слово не должно совпадать с префиксом другого кодового
слова.
· Символы, встречающиеся с большей вероятностью, должны кодироваться более короткими кодовыми словами. То есть L1<=L2<=... <=Ln.
· Два кодовых слова для символов с наименьшей вероятностью должны иметь
одинаковую длину (LN = Ln-1) и различаться только последней цифрой.
Первое требование гарантирует уникальность кодирования любого сообщения. Второе требование определяет так называемый мгновенный код. Это требование не является строго обязательным, но оно требуется, чтобы гарантировать, что сообщение может быть декодировано шаг за шагом. При продвижении слева направо, как только последовательность битов совпадает с данным кодовым словом, декодирующий алгоритм может произвести соответствующее назначение. Вот пример кода, нарушающего первые два требования:
x1 0
х2 010
х3 01
x4 10
Двоичная последовательность 010 может соответствовать одному из трех сообщений:
x 2, x3x1, x1x4
Назначение третьего требования легко понять, если отметить, что при нарушении данного условия, поменяв два кода, вы сможете получить меньшее значение средней длины. Чтобы понять суть последнего требования, предположим, что Ln > Ln-1 По второму требованию кодовое слово N - 1 не может быть префиксом кодового слова N. Поэтому первые N- 1 цифры кодового слова N составляют уникальное кодовое слово, а остальные цифры можно отбросить. Если эти два кодовых слова различаются в каком-либо бите, кроме последнего, мы можем отбросить последний бит у каждого слова, получая таким образом лучший код.
На основании этих методов можно построить код, называемый кодом Хаффман. Начнем с упорядочивания всех символов по убыванию вероятности, так что мы получим символы (а1, а2,..., aN) с вероятностями P(a1) >=Р(а2) >=... >=P(аN). Затем объединим два последних символа в эквивалентный символ с вероятностью Р(аN-1) + Р(аN). Коды этих двух символов будут одинаковыми, кроме последних двух цифр. Теперь у нас есть новый набор из N- 1 символов. При необходи
мости поменяем порядок следования символов таким образом, чтобы получить
символы (b1, b2,... b N-1) с вероятностями P(b1) >= P(b2)>=... >= Р(bN-1). Теперь мы мо
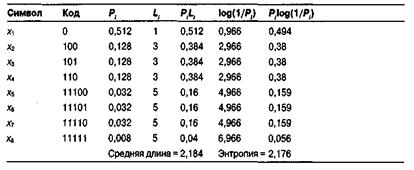
жем повторять этот процесс до тех пор, пока не останется всего два символа. Рисунок ниже иллюстрирует этот процесс для набора символов, заданного в начале раздела. Будем считать каждый символ листовым узлом создаваемого дерева. Объединим два узла с минимальной вероятностью в узел, вероятность которого равна сумме двух соответствующих вероятностей. На каждом шаге будем повторять этот процесс до тех пор, пока не останется только один узел. В результате мы получим дерево, в котором у каждого узла, кроме корневого, одна ветвь отходит направо и две налево. На каждом узле пометим две левые ветви символами 0 и 1 соответственно. Для каждого символа кодовое слово представляет собой строку меток от корневого узла к исходному символу. Все получившиеся в результате кодовые слова показаны в левой части рисунка. Для примера процесс построения кодового слова для символа x 7 обозначен жирной линией.
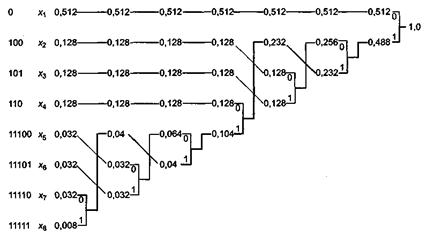
В таблице ниже приведены свойства кода Хаффмана для данного примера. Средняя длина кодового слова представляет собой вычисляемую следующим образом ожидаемую величину:
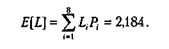
Здесь Li представляет собой длину i-го кодового слова. Таким образом, например, для сообщений, состоящих из 1000 символов, средняя длина кодированного сообщения равна 2184 бит. При простом кодировании каждого символа тремя битами длина этого сообщения будет составлять 3000 бит.