 2014-02-02
2014-02-02 1630
1630Алгоритм обратного распространения ошибки определяет стратегию подбора весов многослойной сети с применением градиентных методов оптимизации. В настоящее время считается одним из наиболее эффективных алгоритмов обучения многослойной сети. При обучении ставится задача минимизации целевой функции, формируемой, как правило, в виде квадратичной суммы разностей между фактическими и ожидаемыми значениями выходных сигналов, которая для P обучающих выборок определяется по формуле:
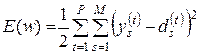 (3.10)
(3.10)
В случае единичной обучающей выборки (x,d) целевая функция имеет вид:
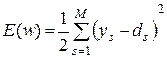 (3.11)
(3.11)
Уточнение весов может проводиться после предъявления каждой обучающей выборки (так называемый режим «онлайн»), при этом используется целевая функция вида (3.9), либо однократно после предъявления всех обучающих выборок (режим «оффлайн»), при этом используется целевая функция вида (3.10). В последующем изложении используется целевая функция вида (3.11).
Для упрощения можно считать, что цель обучения состоит в таком определении значений весов нейронов каждого слоя сети, чтобы при заданном входном векторе получить на выходе значения сигналов 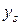 , совпадающие с требуемой точностью с ожидаемыми значениями
, совпадающие с требуемой точностью с ожидаемыми значениями 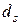 при s= 1, 2,…,M.
при s= 1, 2,…,M.
Обучение сети с использованием алгоритма обратного распространения ошибки проводится в несколько этапов.
На первом из них предъявляется обучающая выборка x и рассчитываются значения сигналов соответствующих нейронов сети. При заданном векторе x определяются вначале значения выходных сигналов vi скрытого слоя, а затем значения ys выходного слоя. Для расчета применяются формулы (3.1) и (3.2). После получения значений выходных сигналов становится возможным рассчитать фактическое значение целевой функции ошибки E(w).
На втором этапе минимизируется значение этой функции.
Так как целевая функция непрерывна, то наиболее эффективными методами обучения оказываются градиентные алгоритмы, согласно которым уточнение вектора весов (обучение) производится по формуле:
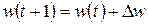 , (3.12)
, (3.12)
где 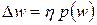 , (3.13)
, (3.13)
h - коэффициент обучения, а p(w) – направление в многомерном пространстве w. В алгоритме обратного распространения ошибки p(w) определяется как частная производная 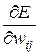 , взятая со знаком минус.
, взятая со знаком минус.
Обучение многослойной сети с применением градиентных методов требует определения вектора градиента относительно весов всех слоев сети, что необходимо для правильного выбора направления p(w). Эта задача имеет очевидное решение только для весов выходного слоя. Для других слоев используется алгоритм обратного распространения ошибки, который определяется следующим образом [4]:
1. Подать на вход сети вектор x и рассчитать значения выходных сигналов нейронов скрытых слоев и выходного слоя, а также соответствующие производные 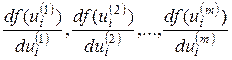 функций активации каждого слоя (m – количество слоев).
функций активации каждого слоя (m – количество слоев).
2. Создать сеть обратного распространения ошибок путем изменения направления передачи сигналов, замены функций активации их производными и подачи на бывший выход сети в качестве входного сигнала разности между фактическими и ожидаемыми значениями.
3. Уточнить веса по формулам (3.12) и (3.13) на основе результатов, полученных в п.1 и п.2 для исходной сети и для сети обратного распространения ошибки.
4. Пункты 1, 2, 3 повторить для всех обучающих выборок, вплоть до выполнения условия остановки: норма градиента станет меньше заданного значения e, характеризующего точность обучения.
Рассмотрим основные расчетные формулы для сети с одним скрытым слоем, представленной на рисунке 3.2. Используется сигмоидальная функция активации, при этом в случае гиперболического тангенса производная функции активации равна
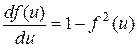 (3.14)
(3.14)
В случае логистической функции производная равна
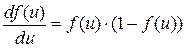 (3.15)
(3.15)
В формулах (3.14) и (3.15) под переменной u будем понимать выходные сигналы сумматоров нейронов скрытого или выходного слоя, представленных формулами (3.16) и (3.17).
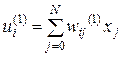 (3.16)
(3.16)
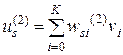 (3.17)
(3.17)
Уточнение весовых коэффициентов будем проводить после предъявления каждой обучающей выборки. Минимизация ведется методом градиентного спуска, что означает подстройку весовых коэффициентов следующим образом:
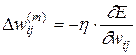 (3.18)
(3.18)
Здесь 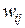 – весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя m-1 с j -ым нейроном слоя m, h – коэффициент обучения, 0<h<1.
– весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя m-1 с j -ым нейроном слоя m, h – коэффициент обучения, 0<h<1.
С учетом принятых на рисунке 3.2 обозначений целевая функция для выходного слоя нейронов определяется следующим образом:
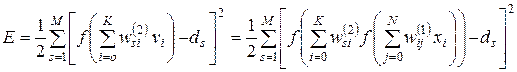 (3.19)
(3.19)
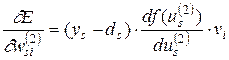 (3.20)
(3.20)
Здесь под , как и раньше, подразумевается выход s –го нейрона.
Если ввести обозначение 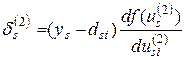 , то соотношение (3.20) можно представить в виде:
, то соотношение (3.20) можно представить в виде:
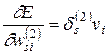 (3.21)
(3.21)
Компоненты градиента относительно нейронов скрытого слоя описываются более сложной зависимостью:
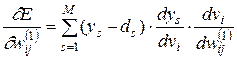 (3.22)
(3.22)
В другом виде эта зависимость может быть выражена формулой:
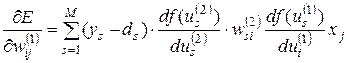 (3.23)
(3.23)
Если ввести обозначение
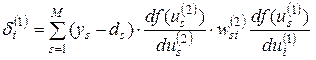 , (3.24)
, (3.24)
то получим выражение, определяющее компоненты градиента относительно весов нейронов скрытого слоя в виде:
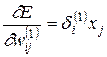 (3.25)
(3.25)








