 2014-02-02
2014-02-02 812
812Градиентные методы обучения многослойного персептрона
Задачу обучения нейронной сети будем рассматривать, как требование минимизировать априори определенную целевую функцию E(w). При таком подходе можно применять для обучения алгоритмы, которые в теории оптимизации считаются наиболее эффективными. К ним, без сомнения, относятся градиентные алгоритмы, чью основу составляет выявление градиента целевой функции. Они связаны с разложением целевой функции E(w) в ряд Тейлора в ближайшей окрестности точки имеющегося решения w. В случае целевой функции от многих переменных (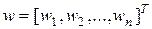 ) такое представление связывается с окрестностью ранее определенной точки (в частности, при старте алгоритма это исходная точка
) такое представление связывается с окрестностью ранее определенной точки (в частности, при старте алгоритма это исходная точка 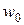 ) в направлении p. Подобное разложение описывается универсальной формулой вида
) в направлении p. Подобное разложение описывается универсальной формулой вида
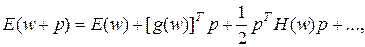 (3.3)
(3.3)
где 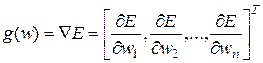 - это вектор градиента, а симметричная квадратная матрица
- это вектор градиента, а симметричная квадратная матрица
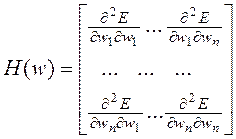
является матрицей производных второго порядка, называемой гессианом.
В выражении (3.3) p играет роль направляющего вектора, зависящего от фактических значений вектора w. На практике чаще всего рассчитываются три первых члена ряда (3.3), а последующие члены ряда просто игнорируются. При этом зависимость (3.3) может считаться квадратичным приближением целевой функции E(w) в ближайшей окрестности найденной точки w с точностью, равной локальной погрешности отсеченной части 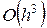 , где h= ||p||. Для упрощения описания значения переменных, полученных в t -ом цикле, будем записывать с нижним индексом t. Точкой решения
, где h= ||p||. Для упрощения описания значения переменных, полученных в t -ом цикле, будем записывать с нижним индексом t. Точкой решения 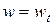 будем считать точку, в которой достигается минимум целевой функции E(w) и
будем считать точку, в которой достигается минимум целевой функции E(w) и 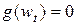 , а гессиан
, а гессиан 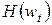 ) является положительно определенным.
) является положительно определенным.
В процессе поиска минимального значения целевой функции направление поиска p и шаг h подбираются таким образом, чтобы для каждой очередной точки 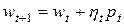 выполнялось условие
выполнялось условие 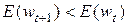 . Поиск минимума продолжается, пока норма градиента не упадет ниже априори заданного значения допустимой погрешности либо пока не будет превышено максимальное время вычислений (количество итераций).
. Поиск минимума продолжается, пока норма градиента не упадет ниже априори заданного значения допустимой погрешности либо пока не будет превышено максимальное время вычислений (количество итераций).
Универсальный оптимизационный алгоритм обучения нейронной сети можно представить в следующем виде (будем считать, что начальное значение оптимизируемого вектора известно и составляет 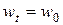 ) [4]:
) [4]:
1. Проверка сходимости и оптимальности текущего решения 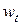 . Если точка отвечает градиентным условиям остановки процесса – завершение вычислений. В противном случае перейти к п.2.
. Если точка отвечает градиентным условиям остановки процесса – завершение вычислений. В противном случае перейти к п.2.
2. Определение вектора направления оптимизации 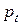 для точки .
для точки .
3. Выбор величины шага 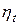 в направлении , при котором выполняется условие
в направлении , при котором выполняется условие 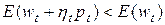 .
.
4. Определение нового решения , а также соответствующих ему значений 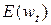 и
и 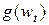 , а если требуется – то и
, а если требуется – то и 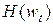 , и возврат к п.1.
, и возврат к п.1.








