 2014-02-02
2014-02-02 1073
1073СУБД
К основным функциям СУБД относятся:
- непосредственность управления данными во внешней и оперативной памяти;
- поддержание целостности данных и управление транзакциями;
- обеспечение безопасности данных;
- обеспечение параллельного доступа к данным нескольких пользователей.
Состав СУБД:
- ядро, которое отвечает за управление данными во внешней и оперативной
памяти;
- процессор языка базы данных, обеспечивающий оптимизацию запросов и
создания машинно-независимого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует
программы манипуляции данными, создающие пользовательский интерфейс;
- сервисные программы (внешние утилиты), обеспечивающие дополнительные
возможности по обслуживанию информационной системы.
По технологии решения задач, решаемых СУБД, БД подразделяют на два вида:
- централизованная БД хранится целиком на ВЗУ одной вычислительной системы; если система входит в состав сети, то возможен доступ к этой БД других систем;
- распределенная БД состоит из нескольких, иногда пересекающихся или дублирующих друг друга БД, хранящихся на ВЗУ разных узлов сети.
СУБД предоставляет доступ к данным БД двумя способами:
- локальный доступ предполагает, что СУБД обрабатывает БД, которая хранится на ВЗУ той же ЭВМ;
- удаленный доступ – это обращение к БД, которая хранится на одном из узлов сети; удаленный доступ может быть выполнен по технологии файл-сервер или клиент-сервер.
Технология файл-сервер предполагает выделение одной из вычислительных систем, называемой сервером, для хранения БД. Все остальные компьютеры сети (клиенты) исполняют роль рабочих станций, которые копируют требуемую часть централизованной БД в свою память, где и происходит обработка.
Технология клиент-сервер предполагает, что сервер, выделенный для хранения централизованной БД, дополнительно производит обработку запросов клиентских рабочих станций. Клиент посылает запрос серверу. Сервер пересылает клиенту данные, являющиеся результатом поиска в БД по ее запросу.
Классификация СУБД по типу модели данных:
Дореляционные
Инвертированные списки (файлы)
Иерархические
Сетевые
Реляционные
Постреляционные
Объектно-реляционные
Объектно-ориентированные
Многомерные
Прочие (NoSQL)
Рассмотрим реляционную модель данных, в которой данные хранятся в виде двумерных таблиц.
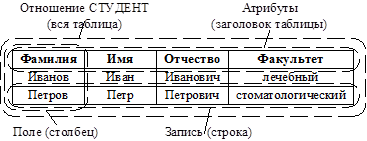
Структура данных реляционной модели данных
Таблицы обладают следующими свойствами:
- каждая ячейка таблицы является одним элементом данных;
- каждый столбец содержит данные одного типа (числа, текст и т. п.);
- каждый столбец имеет уникальное имя;
- таблицы организуются так, чтобы одинаковые строки отсутствовали;
- порядок следования строк и столбцов произвольный.
Каждая таблица представляет собой отношение, описываемое атрибутами:
СТУДЕНТ = (ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО, ФАКУЛЬТЕТ).
Для идентификации записей выделяют следующие виды ключей – полей, определяющих запись:
- первичный: однозначно определяет запись;
- вторичный: выполняет роль поисковых и группировочных признаков и позволяет найти несколько записей.
Ключ может быть простым, если он включает одно поле, или составным, если включает два и более полей. Если в отношении СТУДЕНТ нет однофамильцев, то первичным будет простой ключ – поле ФАМИЛИЯ. Иначе первичным будет составной ключ ФАМИЛИЯ + ИМЯ + ОТЧЕСТВО.
Первичный ключ должен обладать следующими свойствами:
- уникальность: не должно существовать двух или более записей, имеющих одинаковые значения полей, входящих в первичный ключ;
- не избыточность: первичный ключ не должен содержать поля, удаление которых из ключа не нарушит его уникальность.

