 2014-02-02
2014-02-02 6253
6253Сравнение нормализованных и ненормализованных моделей
Анализ критериев для нормализованных и ненормализованных моделей данных
Соберем воедино результаты анализа критериев, по которым мы хотели оценить влияние логического моделирования данных на качество физических моделей данных и производительность базы данных:
| Критерий | Отношения слабо нормализованы (1НФ, 2НФ) | Отношения сильно нормализованы (3НФ) |
| Адекватность базы данных предметной области | ХУЖЕ (-) | ЛУЧШЕ (+) |
| Легкость разработки и сопровождения базы данных | СЛОЖНЕЕ (-) | ЛЕГЧЕ (+) |
| Скорость выполнения вставки, обновления, удаления | МЕДЛЕННЕЕ (-) | БЫСТРЕЕ (+) |
| Скорость выполнения выборки данных | БЫСТРЕЕ (+) | МЕДЛЕННЕЕ (-) |
Как видно из таблицы, более сильно нормализованные отношения оказываются лучше спроектированы (три плюса, один минус). Они больше соответствуют предметной области, легче в разработке, для них быстрее выполняются операции модификации базы данных. Правда, это достигается ценой некоторого замедления выполнения операций выборки данных.
У слабо нормализованных отношений единственное преимущество – если к базе данных обращаться только с запросами на выборку данных, то для слабо нормализованных отношений такие запросы выполняются быстрее. Это связано с тем, что в таких отношениях уже как бы произведено соединение отношений и на это не тратится время при выборке данных.
Таким образом, выбор степени нормализации отношений зависит от характера запросов, с которыми чаще всего обращаются к базе данных.
Можно выделить некоторые классы систем, для которых больше подходят сильно или слабо нормализованные модели данных.
Сильно нормализованные модели данных хорошо подходят для так называемых OLTP-приложений (On-Line Transaction Processing (OLTP) – оперативная обработка транзакций). Типичными примерами OLTP-приложений являются системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег, и т. п. Основная функция подобных систем заключается в выполнении большого количества коротких транзакций. Сами транзакции выглядят относительно просто, например, «снять сумму денег со счета А, добавить эту сумму на счет В». Проблема заключается в том, что, во-первых, транзакций очень много, во-вторых, выполняются они одновременно (к системе может быть подключено несколько тысяч одновременно работающих пользователей), в-третьих, при возникновении ошибки, транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета А, но не поступили на счет В). Практически все запросы к базе данных в OLTP-приложениях состоят из команд вставки, обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Большая часть запросов, таким образом, известна заранее еще на этапе проектирования системы. Таким образом, критическим для OLTP-приложений является скорость и надежность выполнения коротких операций обновления данных. Чем выше уровень нормализации данных в OLTP-приложении, тем оно, как правило, быстрее и надежнее. Отступления от этого правила могут происходить тогда, когда уже на этапе разработки известны некоторые часто возникающие запросы, требующие соединения отношений и от скорости выполнения которых существенно зависит работа приложений. В этом случае можно пожертвовать нормализацией для ускорения выполнения подобных запросов.
Другим типом приложений являются так называемые OLAP-приложения (On-Line Analitical Processing (OLAP) – оперативная аналитическая обработка данных). Это обобщенный термин, характеризующий принципы построения систем поддержки принятия решений (Decision Support System – DSS), хранилищ данных (Data Warehouse), систем интеллектуального анализа данных (Data Mining). Такие системы предназначены для нахождения зависимостей между данными (например, можно попытаться определить, как связан объем продаж товаров с характеристиками потенциальных покупателей), для проведения анализа «что если…». OLAP-приложения оперируют с большими массивами данных, уже накопленными в OLTP-приложениях, взятыми их электронных таблиц или из других источников данных. Такие системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками (например, раз в квартал загружаются данные по итогам квартальных продаж из OLTP-приложения).
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры «очистки», связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны.
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного в результате предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Данные OLAP-приложений обычно представлены в виде одного или нескольких гиперкубов, измерения которого представляют собой справочные данные, а в ячейках самого гиперкуба хранятся собственно данные. Например, можно построить гиперкуб, измерениями которого являются: время (в кварталах, годах), тип товара и отделения компании, а в ячейках хранятся объемы продаж. Такой гиперкуб будет содержать данных о продажах различных типов товаров по кварталам и подразделениям. Основываясь на этих данных, можно отвечать на вопросы вроде «у какого подразделения самые лучшие объемы продаж в текущем году?», или «каковы тенденции продаж отделений Юго-Западного региона в текущем году по сравнению с предыдущим годом»?
Физически гиперкуб может быть построен на основе специальной многомерной модели данных (MOLAP – Multidimensional OLAP) или построен средствами реляционной модели данных (ROLAP – Relational OLAP).
Возвращаясь к проблеме нормализации данных, можно сказать, что в системах OLAP, использующих реляционную модель данных (ROLAP), данные целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных. При этом происходит как добавление новых данных, так и пересчет итогов.
Корректность процедуры нормализации – декомпозиция без потерь. Теорема Хеза
Как было показано выше, алгоритм нормализации состоит в выявлении функциональных зависимостей предметной области и соответствующей декомпозиции отношений. Предположим, что мы уже имеем работающую систему, в которой накоплены данные. Пусть данных корректны в текущий момент, т.е. факты предметной области правильно отражаются текущим состоянием базы данных. Если в предметной области обнаружена новая функциональная зависимость (либо она была пропущена на этапе моделирования предметной области, либо просто изменилась предметная область), то возникает необходимость заново нормализовать данные. При этом некоторые отношения придется декомпозировать в соответствии с алгоритмом нормализации. Возникают естественные вопросы – что произойдет с уже накопленными данными? Не будут ли данные потеряны в ходе декомпозиции? Можно ли вернуться обратно к исходным отношениям, если будет принято решение отказаться от декомпозиции, восстановятся ли при этом данные?
Для ответов на эти вопросы нужно ответить на вопрос – что же представляет собой декомпозиция отношений с точки зрения операций реляционной алгебры? При декомпозиции мы из одного отношения получаем два или более отношений, каждое из которых содержит часть атрибутов исходного отношения. В полученных новых отношениях необходимо удалить дубликаты строк, если таковые возникли. Это в точности означает, что декомпозиция отношения есть не что иное, как взятие одной или нескольких проекций исходного отношения так, чтобы эти проекции в совокупности содержали (возможно, с повторениями) все атрибуты исходного отношения. Т.е., при декомпозиции не должны теряться атрибуты отношений. Но при декомпозиции также не должны потеряться и сами данные. Данные можно считать не потерянными в том случае, если возможна обратная операция – по декомпозированным отношениям можно восстановить исходное отношение в точности в прежнем виде. Операцией, обратной операции проекции, является операция соединения отношений. Имеется большое количество видов операции соединения (см. гл. 4). Т.к. при восстановлении исходного отношения путем соединения проекций не должны появиться новые атрибуты, то необходимо использовать естественное соединение.
Определение 6. Проекция R[X] отношения R на множество атрибутов X называется собственной, если множество атрибутов X является собственным подмножеством множества атрибутов отношения R (т.е. множество атрибутов X не совпадает с множеством всех атрибутов отношения R).
Определение 7. Собственные проекции R1 и R2 отношения R называются декомпозицией без потерь, если отношение R точно восстанавливается из них при помощи естественного соединения для любого состояния отношения R: 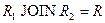 .
.
Рассмотрим пример, показывающий, что декомпозиция без потерь происходит не всегда.
Пример 2. Пусть дано отношение R:
| Таблица 7 Отношение R | |||||||||
|
Рассмотрим первый вариант декомпозиции отношения R на два отношения:
| Таблица 8 Отношение R1 | ||||||
| ||||||
| Таблица 9 Отношение R2 | ||||||
|
Естественное соединение этих проекций, имеющих общий атрибут «ЗАРПЛАТА», очевидно, будет следующим (каждая строка одной проекции соединится с каждой строкой другой проекции):
Таблица 10 Отношение 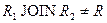 | |||||||||||||||
|
Итак, данная декомпозиция не является декомпозицией без потерь, т.к. исходное отношение не восстанавливается в точном виде по проекциям.
Рассмотрим другой вариант декомпозиции:
| Таблица 11 Отношение R1 | ||||||
| ||||||
| Таблица 12 Отношение R2 | ||||||
|
По данным проекциям, имеющие общий атрибут «НОМЕР», исходное отношение восстанавливается в точном виде. Тем не менее, нельзя сказать, что данная декомпозиция является декомпозицией без потерь, т.к. мы рассмотрели только одно конкретное состояние отношения R, и не можем сказать, будет ли и в других состояниях отношение R восстанавливаться точно. Например, предположим, что отношение R перешло в состояние:
| Таблица 13 Отношение R | ||||||||||||
|
Кажется, что этого не может быть, т.к. значения в атрибуте «НОМЕР» повторяются. Но мы же ничего не говорили о ключе этого отношения! Сейчас проекции будут иметь вид:
| Таблица 14 Отношение R1 | ||||||||
| ||||||||
| Таблица 15 Отношение R2 | ||||||||
|
Естественное соединение этих проекций будет содержать лишние кортежи:
Таблица 16 Отношение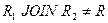 | ||||||||||||||||||
|
Вывод. Таким образом, без дополнительных ограничений на отношение R нельзя говорить о декомпозиции без потерь.
Такими дополнительными ограничениями и являются функциональные зависимости. Имеет место следующая теорема Хеза [54]:
Теорема (Хеза). Пусть  является отношением, и
является отношением, и 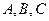 – атрибуты или множества атрибутов этого отношения. Если имеется функциональная зависимость
– атрибуты или множества атрибутов этого отношения. Если имеется функциональная зависимость 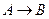 , то проекции
, то проекции 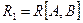 и
и 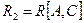 образуют декомпозицию без потерь.
образуют декомпозицию без потерь.
Доказательство. Необходимо доказать, что для любого состояния отношения R. В левой и правой части равенства стоят множества кортежей, поэтому для доказательства достаточно доказать два включения для двух множеств кортежей: 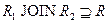 и
и 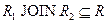 .
.
Докажем первое включение. Возьмем произвольный кортеж 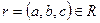 . Докажем, что он включается также и в
. Докажем, что он включается также и в 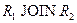 . По определению проекции, кортежи
. По определению проекции, кортежи 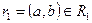 и
и 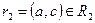 . По определению естественного соединения кортежи r1 и r2, имеющие одинаковое значение a общего атрибута A, будут соединены в процессе естественного соединения в кортеж
. По определению естественного соединения кортежи r1 и r2, имеющие одинаковое значение a общего атрибута A, будут соединены в процессе естественного соединения в кортеж 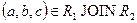 . Таким образом, включение доказано.
. Таким образом, включение доказано.
Докажем обратное включение. Возьмем произвольный кортеж  . Докажем, что он включается также и в R. По определению естественного соединения получим, что имеются кортежи и . Т.к. , то существует некоторое значение c1, такое что кортеж
. Докажем, что он включается также и в R. По определению естественного соединения получим, что имеются кортежи и . Т.к. , то существует некоторое значение c1, такое что кортеж 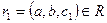 . Аналогично, существует некоторое значение b1, такое что кортеж
. Аналогично, существует некоторое значение b1, такое что кортеж 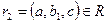 . Кортежи r1 и r2 имеют одинаковое значение атрибута A, равное a. Из этого, в силу функциональной зависимости , следует, что
. Кортежи r1 и r2 имеют одинаковое значение атрибута A, равное a. Из этого, в силу функциональной зависимости , следует, что 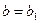 . Таким образом, кортеж
. Таким образом, кортеж 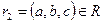 . Обратное включение доказано.
. Обратное включение доказано.
Теорема доказана.
Замечание. В доказательстве теоремы Хеза наличие функциональной зависимости не использовалось при доказательстве включения . Это означает, что при выполнении декомпозиции и последующем восстановлении отношения при помощи естественного соединения, кортежи исходного отношения не будут потеряны. Основной смысл теоремы Хеза заключается в доказательстве того, что при этом не появятся новые кортежи, отсутствовавшие в исходном отношении.
Т.к. алгоритм нормализации (приведения отношений к 3НФ) основан на имеющихся в отношениях функциональных зависимостях, то теорема Хеза показывает, что алгоритм нормализации является корректным, т.е. в ходе нормализации не происходит потери информации.








