 2014-02-02
2014-02-02 329
329ПРИМЕР 10
МЕТОДЫ РЕГРЕССИОННОГО И КОРРЕЛЯЦИОННОГО АНАЛИЗОВ
Модели причинного прогнозирования обычно содержат ряд переменных, которые имеют отношение к предсказываемой переменной. Как только эти переменные будут найдены, строится статистическая модель, которая используется для прогноза интересующей нас переменной. Этот подход является более мощным, чем методы временных серий, которые используют прошлые значения для прогнозируемой переменной.
Многие факторы могли бы рассматриваться в причинном анализе. Например, продажи товара могут быть связаны с расходами фирмы на рекламу, с назначаемой ценой, с делами конкурентов и стратегиями продвижения товаров или даже с экономическими условиями и безработицей. В этом случае продажи будут называться зависимой переменной, а другие переменные будут называться независимыми переменными. Работа менеджеров заключается в установлении наилучшей статистической зависимости между продажами и независимыми переменными. Наиболее общей количественной моделью причинного прогнозирования является модель линейного регрессионного анализа.
Использование регрессионного анализа для прогнозирования. Мы можем использовать такие математические модели, которые применяли как метод наименьших квадратов в трендовом проектировании, преобразовав их к моделям линейной регрессии. Зависимая переменная, которую мы хотим спрогнозировать, будет обозначаться у. Но теперь независимая переменная х – это не время.
у = а + bх,
где у – значение зависимой переменной, здесь – объем продаж;
a – отрезок, отсекаемый на оси у;
b – наклон линии регрессии;
х – независимая переменная.
Строительная компания реконструирует старые дома. По истечении времени компания нашла, что ее объем работ по реконструкции связан с уровнем местной заработной платы. Таблица ниже содержит данные о годовых доходах и суммах денежных доходов в 1987 – 1992 годах.
2.0 1
3.0 3
2.5 4
2.0 2
2.0 1
3.5 7
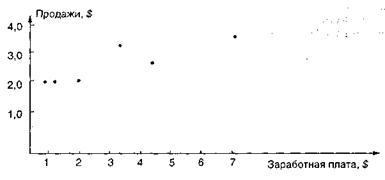
 Служба менеджмента компании хочет представить математическую взаимосвязь, которая будет помогать ей предсказывать продажи. Первое, что необходимо определить, имеет ли место линейная связь между заработной платой и продажами; для этого наносятся известные данные на диаграмму рассеивания.
Служба менеджмента компании хочет представить математическую взаимосвязь, которая будет помогать ей предсказывать продажи. Первое, что необходимо определить, имеет ли место линейная связь между заработной платой и продажами; для этого наносятся известные данные на диаграмму рассеивания.
|
На диаграмме показано шесть точек данных, которые отражают положительную зависимость между независимой переменной, заработной платой и зависимой переменной, продажами. Когда зарплата возрастает, продажи компании имеют тенденцию к повышению.
Мы можем найти математическое уравнение регрессии, используя метод наименьших квадратов.
| Продажи, у | Зарплата, х | х2 | ху |
| 2.0 | 2.0 | ||
| 3.0 | 9.0 | ||
| 2.5 | 10.0 | ||
| 2.0 | 4.0 | ||
| 2.0 | 2.0 | ||
| 3.5 | 24.5 | ||
| Σх = 15.0 | Σу = 18 | Σх2 = 80 | Σху = 51.5 |
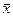 = Σ х / 6 = 18 / 6 = 3;.
= Σ х / 6 = 18 / 6 = 3;. 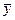 = Σ у / 6 = 15 / 6 = 2,5,
= Σ у / 6 = 15 / 6 = 2,5,
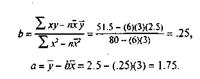
|
Уравнение регрессии, следовательно, будет:
у = 1.75 +.25 х,
или:
Продажи = 1,75 +.25 Зарплата.
Если местная коммерческая служба определит, что зарплата в регионе будет $ 600000000 в следующем году, мы можем прогнозировать продажи строительной компании по уравнению регрессии:
Продажи (в млн. $) = 1.75 – 1.25 (6)
или:
Продажи = $325000.
Заключительная часть примера 10 иллюстрирует главную слабость методов прогнозирования на базе регрессии. Даже когда мы рассчитали уравнение, необходимо проводить прогноз независимой переменной х (в этом случае заработной платы), прежде чем определять зависимую переменную у для следующего периода времени. Хотя это – проблема не для всех прогнозов, следует представлять себе сложности в определении будущих значений таких общих независимых переменных, как уровень безработицы, валовой национальный продукт, индексы цен и т. д.
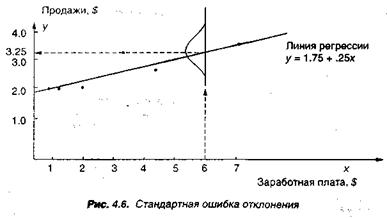
 Прогноз продаж $325000 в примере 10 называется точкой оценки для у. Точка оценки является реальным значением, или ожидаемой величиной, возможных объемов продаж дистрибьютеров. Рис. 4.6 иллюстрирует этот подход.
Прогноз продаж $325000 в примере 10 называется точкой оценки для у. Точка оценки является реальным значением, или ожидаемой величиной, возможных объемов продаж дистрибьютеров. Рис. 4.6 иллюстрирует этот подход.
|
Измеряя точность регрессионных оценок, нам необходимо рассчитать стандартную ошибку прогноза Sy,x. Ее называют стандартным отклонением уравнения регрессии. Уравнение (4.11) мы находим в большинстве книг по статистике для расчета стандартного отклонения арифметических значений:
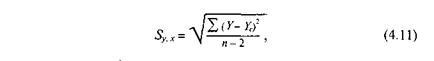
|
где Y – значение У для каждой точки данных;
YC – расчетное значение зависимой переменной из уравнения регрессии;
п – число точек данных.
Уравнение (4.12) может показаться более общим, но это только версия уравнения (4.11). Та и другая формулы требуют общих данных и могут быть использованы на прогнозируемых интервалах вокруг оцениваемой точки.
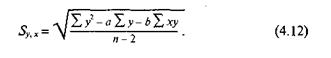
|








