 2014-02-03
2014-02-03 8062
8062Проверка статистических гипотез
Статистическая гипотеза – это предположение (суждение) о генеральной совокупности – ее распределении или параметрах, подвергаемое проверке по выборке, в результате которой она принимается или отвергается. Формулировка гипотезы должна исходит из возможности использования известных законов распределения.
Сущность проверки статистических гипотез заключается в том, чтобы установит, согласуются или нет данные наблюдений и выдвинутая гипотеза. Можно ли расхождение между гипотезой и результатами выборочных наблюдений отнести за счет случайной погрешности, обусловленной механизмом случайного отбора.?
Выдвигаемая гипотеза называется нулевой и обозначается 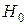 , а противоречащая ей называется альтернативной гипотезой и обозначается
, а противоречащая ей называется альтернативной гипотезой и обозначается 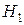 .
.
Методика доказательства статистических гипотез разрабатывается в теории проверки статистических гипотез, основные принципы которой сформулированы известными математиками Е. Нейманом и Э. Пирсоном. В основе методики (схемы) доказательства лежит расчет некоторых статистических величин, которые называются критериями проверки статистических гипотез. Таким образом, при проверке статистических гипотез мы используем готовые схемы проверки гипотез или приводим задачу к виду, позволяющему воспользоваться готовой схемой.
Критерии проверки статистических гипотез – это показатели, вычисляемые на основании фактических наблюдений, позволяющие сделать вывод о принятии или опровержении проверяемой гипотезы. Значение критерия является случайной величиной, та как вычисляется на основе результатов выборочного наблюдения. Это например, t - критерий Стьюдента, F – критерий Фишера, хи – квадрат Пирсона (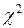 ) и другие.
) и другие.
Решение о принятии или отклонении нулевой гипотезы формулируется на основе выборки и зависит от значения статистического критерия. Множество возможных значений статистического критерия можно разделить на два непересекающихся подмножества 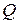 и
и 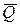 ,
, 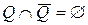 . Проверяемая нулевая гипотеза должна быть отвергнута, если фактическое значение критерия
. Проверяемая нулевая гипотеза должна быть отвергнута, если фактическое значение критерия 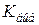 (рассчитанное по данным выборки) принадлежит подмножеству . Подмножество называется критической областью. Подмножество называется областью принятия гипотезы. Критическая область может быть двухсторонней или односторонней (левосторонней или правосторонней) рис. 6.1 – рис.6.3. Точки
(рассчитанное по данным выборки) принадлежит подмножеству . Подмножество называется критической областью. Подмножество называется областью принятия гипотезы. Критическая область может быть двухсторонней или односторонней (левосторонней или правосторонней) рис. 6.1 – рис.6.3. Точки  , разделяющие две области, называются критическими точками.
, разделяющие две области, называются критическими точками.
Проверка статистической гипотезы не является исчерпывающим доказательством ее верности или неверности. Ее принятие означает лишь ее непротиворечивость имеющимся фактическим (выборочным) данным. Степень уверенности в принятии гипотезы может быть определена через вероятности совершения ошибок. Ошибки, возникающие при проверке статистических гипотез, могут быть двух видов: ошибки первого рода и ошибки второго рода.
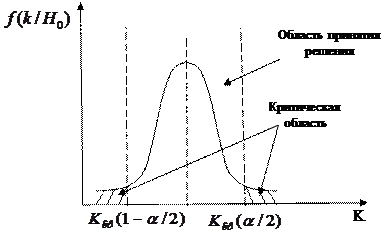
Рис. 6.1. Двухсторонняя критическая область
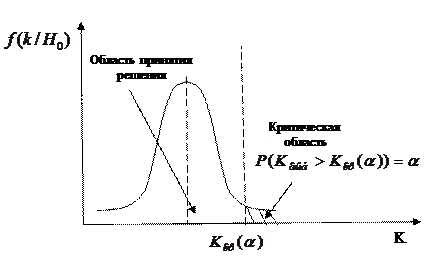
Рис. 6.2. Правосторонняя критическая область

Рис. 6.3. Левостороняя критическая область
6.2. Сглаживание эмпирических данных теоретической функцией плотности ( )
Часто выборочный частотный ряд оказывается очень близким к какому-либо известному теоретическому закону распределения. Кроме того, отдельные методы анализа данных требуют того, чтобы данные подчинялись определенному закону распределения. В этих случаях возникает необходимость решения задачи проверки согласованности данных с теоретическим законом распределения. Критерии проверки статистических гипотез о согласованности данных с теоретическим законом распределения называются критериями согласия. Одним из самых распространенных критериев согласия является критерий согласия К. Пирсона (или - “хи квадрат”). В качестве меры расхождения теоретического и выборочного законов распределения в критерии принята взвешенная сумма квадратов отклонений соответствующих частотных рядов:
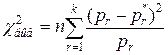 , (6.1)
, (6.1)
где 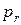 - теоретические вероятности попадания случайной величины в заданные интервалы
- теоретические вероятности попадания случайной величины в заданные интервалы 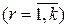 ;
;
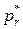 - частоты выборочного частотного ряда ;
- частоты выборочного частотного ряда ;
k – количество интервалов частотного ряда;
n – объем выборки.
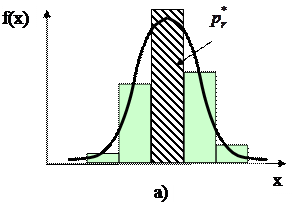
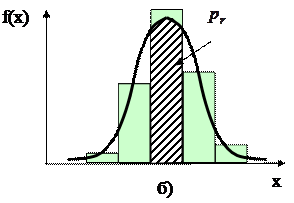
Рис. 6.4. Соотношение выборочного и теоретического частотных рядов: а) выборочная частота; б) – теоретическая частота
В теории доказывается, что если частотные ряды отличаются не значимо, то статистика (6.1) распределена по закону с 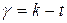 степенями свободы, где k – количество интервалов, t – число связей (параметров, рассчитанных по выборке). Функция плотности имеет вид рис. 6.5. Проверка статистической гипотезы производится для правосторонней критической области. Уровень значимости
степенями свободы, где k – количество интервалов, t – число связей (параметров, рассчитанных по выборке). Функция плотности имеет вид рис. 6.5. Проверка статистической гипотезы производится для правосторонней критической области. Уровень значимости 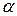 обычно выбирают равным 0, 05.
обычно выбирают равным 0, 05.

Рис. 6.5. Функция плотности распределения
Рассмотрим примеры проверки статистических гипотез о согласованности данных теоретическим законам распределения. Для этого будем использовать данные и результаты расчетов, приведенные в параграфе 3.2. Скопируем данные и таблицы выборочных частотных рядов на новый лист EXCEL (рис. 6.6 и рис. 6.7).
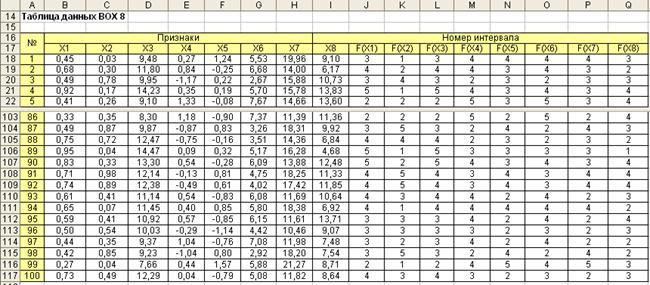
Рис. 6.6. Таблица данных
Рис. 6.7. Результаты предварительного анализа данных
Данные, приведенные в таблице данных на рис. 6.6 были получены путем моделирования. Признаки  моделировались, как выборки из равномерных распределений, а признаки
моделировались, как выборки из равномерных распределений, а признаки 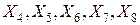 , как выборки из нормальных распределений. Проверим статистические гипотезы о том действительно ли модельные данные согласуются с теоретическими законами распределения (равномерным и нормальным), то есть, правильно ли мы решили задачу моделирования.
, как выборки из нормальных распределений. Проверим статистические гипотезы о том действительно ли модельные данные согласуются с теоретическими законами распределения (равномерным и нормальным), то есть, правильно ли мы решили задачу моделирования.
Рассчитаем теоретические частоты для равномерного распределения. Частоты теоретического частотного ряда по всем пяти интервалам 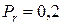 (рис. 6.8).
(рис. 6.8).
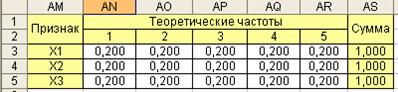
Рис. 6.8. Теоретические вероятности равномерного распределения
Расчеты выборочных значений критерия для признаков приведены на рис. 6.9. В последнем столбце таблицы на рис. 6.9 содержатся критические значения критерия при степенях свободы 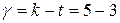 .
.
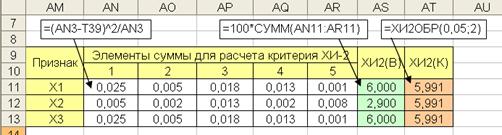
Рис. 6.9. Расчет выборочных значений критерия для равномерных распределений
По результатам сравнения выборочных и критических значений критерия , приведенных на рис. 6.9 можно сделать вывод, что признаки 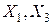 не согласуются с гипотезой о равномерном распределении, а выборочные данные признака
не согласуются с гипотезой о равномерном распределении, а выборочные данные признака 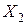 согласуются с гипотезой о равномерном распределении. Гистограммы, построенные по данным выборок признаков , так же подтверждают сделанный вывод. Совпадение результатов расчетов выборочных значений критерия для признаков не случайно. Признак
согласуются с гипотезой о равномерном распределении. Гистограммы, построенные по данным выборок признаков , так же подтверждают сделанный вывод. Совпадение результатов расчетов выборочных значений критерия для признаков не случайно. Признак 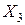 был получен путем линейного преобразования признака
был получен путем линейного преобразования признака 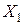 .
.
Рассмотрим расчеты, произведенные для проверки гипотезы нормальности выборок признаков . Расчет теоретических частот приведем на примере признака 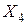 . Теоретические частоты для нормального распределения производятся с помощью функции EXCEL НОРМРАСП. Функция НОРМРАСП позволяет рассчитать интеграл нормального распределения Рис. 6.10. Интерфейс функции НОРМРАСП приведен на рис. 6.11.
. Теоретические частоты для нормального распределения производятся с помощью функции EXCEL НОРМРАСП. Функция НОРМРАСП позволяет рассчитать интеграл нормального распределения Рис. 6.10. Интерфейс функции НОРМРАСП приведен на рис. 6.11.
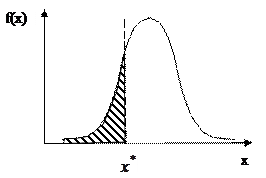
Рис. 6.10. Интегральная функция НОРМРАСП
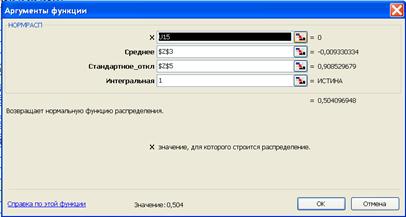
Рис. 6.11. Ввод параметров функции НОРМРАСП
Расчет теоретических частот нормального распределения по интервалам производится в два шага. На первом шаге рассчитываются интегральные функции по правым границам интервалов. Последняя граница берется равной бесконечности и соответственно интеграл равен 1 (рис. 6.12). В числе параметров функции НОРМРАСП вводятся средние значения и среднеквадратичные значения, рассчитываемы по выборочным данным (рис. 6.7).
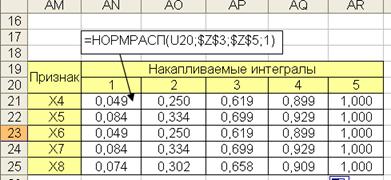
Рис. 6.12. Таблица накапливаемых частот нормальных функций распределения
На втором шаге рассчитываются вероятности попадания нормальных случайных величин с заданными параметрами на интервалы, построенные для частотных рядов выборочных данных. Вероятности рассчитываются как разности двух последовательных накапливаемых интегралов (рис.6.13).
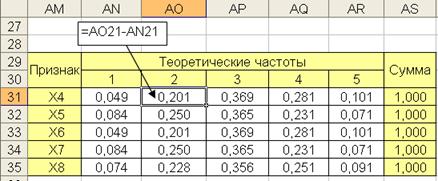
Рис. 6.13. Таблица накапливаемых частот нормальных функций распределения
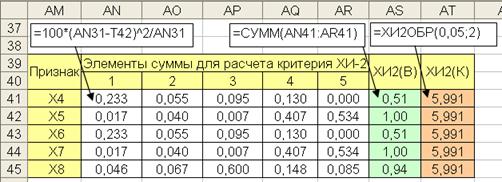
Рис. 6.14. Расчет выборочных значений критерия для нормальных распределений
6.3. Непараметрический критерий оценки зависимости признаков ()
Критерий нашел еще одно важное применение. Он используется для оценки зависимости признаков. В отличие от коэффициента корреляции с помощью критерия может быть выявлена и нелинейная связь. Логику применения критерия рассмотрим на простом примере.
Предположим, что в период предвыборной компании, оргкомитет одного из кандидатов производит опрос электората, с целью выявления влияния пола на предпочтения, отдаваемые кандидатам. В ходе опроса хотят выяснить, влияет ли пол на выбор кандидата. Если влияет, избирательному штабу необходимо скорректировать организацию рекламной компании.
Поскольку мы не имеем реальных данных, мы можем легко смоделировать ситуацию. Для демонстрации расчетов по оценки зависимости признаков будем использовать таблицу данных (рис. 6.15). Столбцы данных X1 Y1 - это выборка из двухмерного нормального распределения с параметрами 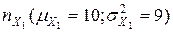 ,
,  ,
, 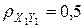 (копия данных практического занятия №6 – класс 2). Признаки X2 Y2 получены путем копирования столбцов F(X1)и F(x2) из таблицы данных практического занятия № 2. Признак “Пол” смоделируем путем преобразования признака X1. Преобразование состоит в сравниваем значения признака с его средним значением. При этом увеличим долю женщин в выборке, введением коэффициента 0,92. Таким образом, количество женщин в выборке составит 59 человек, мужчин 41 человек.
(копия данных практического занятия №6 – класс 2). Признаки X2 Y2 получены путем копирования столбцов F(X1)и F(x2) из таблицы данных практического занятия № 2. Признак “Пол” смоделируем путем преобразования признака X1. Преобразование состоит в сравниваем значения признака с его средним значением. При этом увеличим долю женщин в выборке, введением коэффициента 0,92. Таким образом, количество женщин в выборке составит 59 человек, мужчин 41 человек.
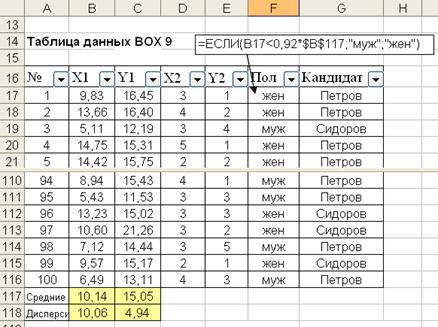
Рис 6.15 Таблица данных
Признак “Кандидат” сформируем путем последовательного выполнения операции фильтровать - копировать. При копировании будем копировать три фамилии ”Иванов” “Петров” “Сидоров”. При выполнении операции копирования фамилий мы умышленно несколько завысили у мужчин долю предпочтения кандидата Сидоров.
Выдвигается нулевая гипотеза о том, что признаки независимы. В нашем примере это означает, что пол не влияет на выбор кандидата. Проверка статистической гипотезы зависимости двух признаков производится в несколько шагов.
Шаг первый. Рассчитаем таблицу сопряженности признаков ”пол” “Кандидат”. Для этого будем использовать программу EXCEL “Сводная таблица”. Эта программы выбирается в меню “Данные” рис. 6.16. Макет сводной таблицы формируется перетаскиванием полей по макету таблицы (рис. 6.17). В поле данные необходимо установить способ расчета ячеек сводной таблицы (рис. 6.18). В нашем случае необходимо выбрать “Количество”.
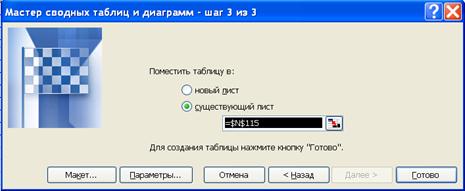
Рис. 6.16. Мастер сводных таблиц
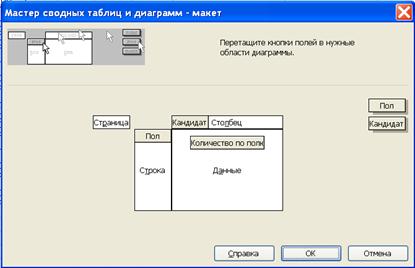
Рис. 6.17. Разработка макета сводной таблицы
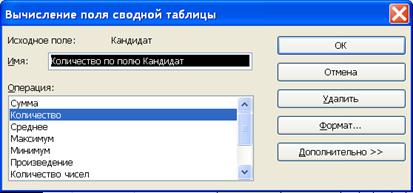
Рис. 6.18. Способ расчета сводной таблицы
Для того чтобы производить расчеты со сводной таблицей ее необходимо скопировать с использованием команд “Вставка” – “Спецвставка” – “Значения”. В результате получим таблицу сопряженности признаков или таблицу выборочных частот (рис.6.19). Элементы таблицы выборочных частот обозначим 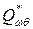 (
(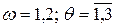 ).
).
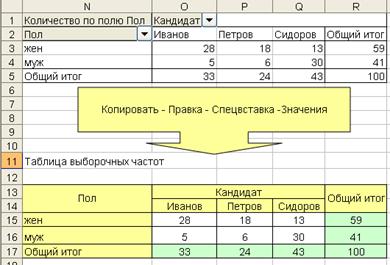
Рис. 6.19. Таблица выборочных частот
Второй шаг. Вначале произведем логические рассуждения. Предположим, что предпочтение тем или иным кандидатам не зависит от пола. Тогда 33% избирателей предпочли бы кандидата Иванова, 24% кандидата Петрова и 43% кандидата Сидорова. Теперь определим сколь бы собрали голосов кандидаты при условии независимости от пола, если бы число опрашиваемых было бы 59 (по числу женщин). Тогда Иванова бы предпочло 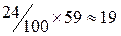 человек. Аналогично можно рассчитать все ячейки новой таблицы сопряженности признаков. Напомним, что таблица рассчитывается исходя из условия независимости двух признаков. Каждый элемент таблицы рассчитывается по формуле (6.2):
человек. Аналогично можно рассчитать все ячейки новой таблицы сопряженности признаков. Напомним, что таблица рассчитывается исходя из условия независимости двух признаков. Каждый элемент таблицы рассчитывается по формуле (6.2):
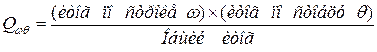 (6.2)
(6.2)
Результаты расчета сведем в таблицу, которая называется таблицей теоретических частот (рис. 6.20). Теперь мы можем сравнить две таблицы частот и записать критерий для этого случая (6.3):
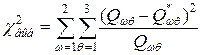 (6.3)
(6.3)
Количество степеней свободы для распределения в этом случае исчисляется по формуле 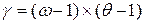 . Для нашего примера
. Для нашего примера 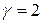 . Расчет выборочного значения критерия произведен в таблице (рис. 6.20). Критическое значение критерия определено с помощью функции ХИ2ОБР. Поскольку выборочное значения критерия
. Расчет выборочного значения критерия произведен в таблице (рис. 6.20). Критическое значение критерия определено с помощью функции ХИ2ОБР. Поскольку выборочное значения критерия 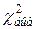 =26,37 больше критического значения
=26,37 больше критического значения 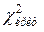 =5,99, то мы должны отвергнуть гипотезу независимости признаков. То есть, в нашем примере мы должны признать, что пол влияет на предпочтение кандидата, что должно быть учтено при организации предвыборной компании.
=5,99, то мы должны отвергнуть гипотезу независимости признаков. То есть, в нашем примере мы должны признать, что пол влияет на предпочтение кандидата, что должно быть учтено при организации предвыборной компании.

Рис.6.20. Расчет критерия для признаков ”пол” “Кандидат”
Заметим, что мы проверяли зависимость признаков, выраженных в номинальной шкале измерения. Рассмотрим пример проверки гипотезы зависимости признаков, выраженных в ранговой шкале. Для расчетов мы будем использовать данные, размещенные в столбцах X2 Y2. Результаты выполнения расчетов в EXCEL приведены на рис. 6.21.
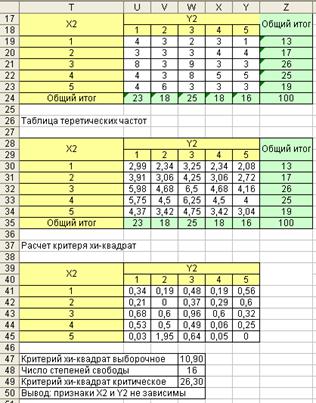
Рис.6.21. Расчет критерия для признаков X2 Y2
Во втором примере гипотеза независимости признаков подтверждается. Так и должно быть, поскольку мы брали для проверки заведомо независимые признаки. С помощью критерия можно оценить и зависимость признаков, измеренных в непрерывной шкале отношений. Для этого сначала необходимо преобразовать данные путем выполнения операции дискретизации.

