 2015-10-16
2015-10-16 41946
41946Автор: научный сотрудник, А. Д. Наследов, Научный сотрудник, Издательство «Речь». Тип материала: Научная статья
В главе 4 мы рассмотрели основные одномерные описательные статистики — меры центральной тенденции и изменчивости, которые применяются для описания одной переменной. В этой главе мы рассмотрим основные коэффициенты корреляции.
Коэффициент корреляции — двумерная описательная статистика, количественная мера взаимосвязи (совместной изменчивости) двух переменных.
История разработки и применения коэффициентов корреляции для исследования взаимосвязей фактически началась одновременно с возникновением измерительного подхода к исследованию индивидуальных различий — в 1870—1880 гг. Пионером в измерении способностей человека, как и автором самого термина «коэффициент корреляции», был Френсис Гальтон, а самые популярные коэффициенты корреляции были разработаны его последователем Карлом Пирсоном. С тех пор изучение взаимосвязей с использованием коэффициентов корреляции является одним из наиболее популярных в психологии занятием.
К настоящему времени разработано великое множество различных коэффициентов корреляции, проблеме измерения взаимосвязи с их помощью посвящены сотни книг. Поэтому, не претендуя на полноту изложения, мы рассмотрим лишь самые важные, действительно незаменимые в исследованиях меры связи — /--Пирсона, r-Спирмена и т-Кендалла'. Их общей особенностью является то, что они отражают взаимосвязь двух признаков, измеренных в количественной шкале — ранговой или метрической.
Вообще говоря, любое эмпирическое исследование сосредоточено на изучении взаимосвязей двух или более переменных.
ПРИМЕРЫ
Приведем два примера исследования влияния демонстрации сцен насилия по ТВ на агрессивность подростков. 1. Изучается взаимосвязь двух переменных, измеренных в количественной (ранговой или метрической) шкале: 1)«время просмотра телепередач с насилием»; 2) «агрессивность».
Читается как тау-Кендалла.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
2. Изучается различие в агрессивности 2-х или более групп подростков, отличающихся длительностью просмотра телепередач с демонстрацией сцен насилия.
Во втором примере изучение различий может быть представлено как исследование взаимосвязи 2-х переменных, одна из которых — номинативная (длительность просмотра телепередач). И для этой ситуации также разработаны свои коэффициенты корреляции.
Любое исследование можно свести к изучению корреляций, благо изобретены самые различные коэффициенты корреляции для практически любой исследовательской ситуации. Но в дальнейшем изложении мы будем различать два класса задач:
исследование корреляций — когда две переменные представлены в числовой шкале;
исследование различий — когда хотя бы одна из двух переменных представлена в номинативной шкале.
Такое деление соответствует и логике построения популярных компьютерных статистических программ, в которых в меню Корреляции предлагаются три коэффициента (/--Пирсона, r-Спирмена и х-Кендалла), а для решения других исследовательских задач предлагаются методы сравнения групп.
ПОНЯТИЕ КОРРЕЛЯЦИИ
Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически изображаются в виде линий. На рис. 6.1 изображено несколько графиков функций. Если изменение одной переменной на одну единицу всегда приводит к изменению другой переменной на одну и ту же величину, функция является линейной (график ее представляет прямую линию); любая другая связь — нелинейная. Если увеличение одной переменной связано с увеличением другой, то связь — положительная (прямая); если увеличение одной переменной связано с уменьшением другой, то связь — отрицательная (обратная). Если направление изменения одной переменной не меняется с возрастанием (убыванием) другой переменной, то такая функция — монотонная; в противном случае функцию называют немонотонной.
Функциональные связи, подобные изображенным на рис. 6.1, являются иде-ализациями. Их особенность заключается в том, что одному значению одной переменной соответствует строго определенное значение другой переменной. Например, такова взаимосвязь двух физических переменных — веса и длины тела (линейная положительная). Однако даже в физических экспериментах эмпирическая взаимосвязь будет отличаться от функциональной связи в силу неучтенных или неизвестных причин: колебаний состава материала, погрешностей измерения и пр.
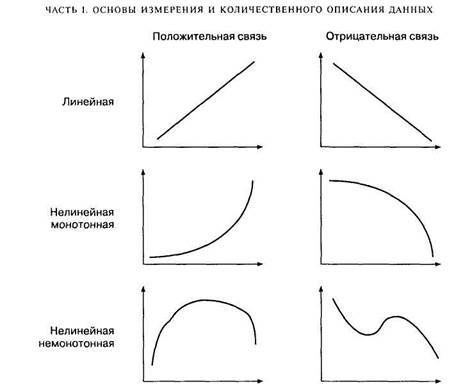
Рис. 6.1. Примеры графиков часто встречающихся функций
В психологии, как и во многих других науках, при изучении взаимосвязи признаков из поля зрения исследователя неизбежно выпадает множество возможных причин изменчивости этих признаков. Результатом является то, что даже существующая в реальности функциональная связь между переменными выступает эмпирически как вероятностная (стохастическая): одному и тому же значению одной переменной соответствует распределение различных значений другой переменной (и наоборот). Простейшим примером является соотношение роста и веса людей. Эмпирические результаты исследования этих двух признаков покажут, конечно, положительную их взаимосвязь. Но несложно догадаться, что она будет отличаться от строгой, линейной, положительной — идеальной математической функции, даже при всех ухищрениях исследователя по учету стройности или полноты испытуемых. (Вряд ли на этом основании кому-то придет в голову отрицать факт наличия строгой функциональной связи между длиной и весом тела.)
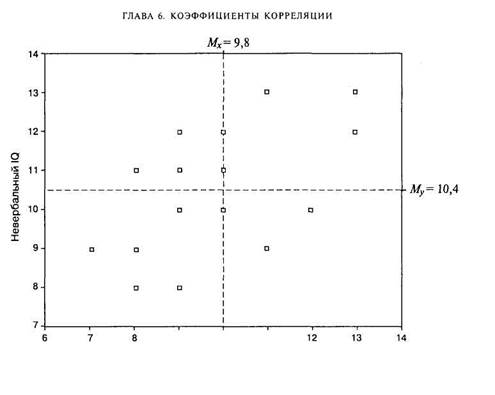
Итак, в психологии, как и во многих других науках, функциональная взаимосвязь явлений эмпирически может быть выявлена только как вероятностная связь соответствующих признаков. Наглядное представление о характере вероятностной связи дает диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а каждый испытуемый представляет собой точку (рис. 6.2). В качестве числовой характеристики вероятностной связи используются коэффициенты корреляции.
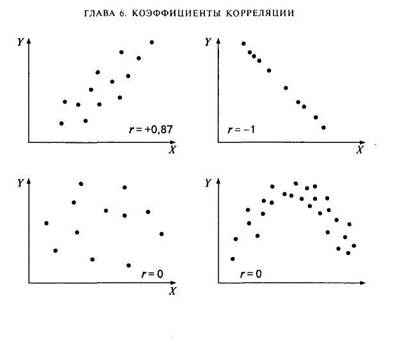 |
Рис. 6.2. Примеры диаграмм рассеивания и соответствующих коэффициентов корреляции
Коэффициент корреляции — это количественная мера силы и направления вероятностной взаимосвязи двух переменных; принимает значения в диапазоне от-1 до +1.
Сила связи достигает максимума при условии взаимно однозначного соответствия: когда каждому значению одной переменной соответствует только одно значение другой переменной (и наоборот), эмпирическая взаимосвязь при этом совпадает с функциональной линейной связью. Показателем силы связи является абсолютная (без учета знака) величина коэффициента корреляции.
Направление связи определяется прямым или обратным соотношением значений двух переменных: если возрастанию значений одной переменной соответствует возрастание значений другой переменной, то взаимосвязь называется прямой (положительной); если возрастанию значений одной переменной соответствует убывание значений другой переменной, то взаимосвязь является обратной (отрицательной). Показателем направления связи является знак коэффициента корреляции.
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ г-ПИРСОНА
r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух метрических переменных, измеренных на одной и той же выборке. Существует множество ситуаций, в которых уместно его применение. Влияет ли интеллект на успеваемость на старших курсах университета? Связан ли размер заработной платы работника с его доброжелательностью к коллегам? Влияет ли настроение школьника на успешность решения сложной арифметической задачи? Для ответа на подобные вопросы исследователь должен измерить два интересующих его показателя у каждого члена выборки. Данные для изучения взаимосвязи затем сводятся в таблицу, как в приведенном ниже примере.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ.
ПРИМЕР 6.1
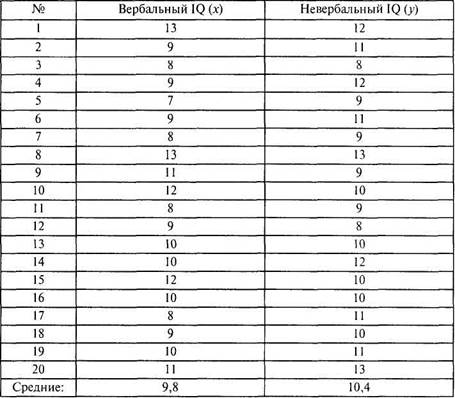
В таблице приведен пример исходных данных измерения двух показателей интеллекта (вербального и невербального) у 20 учащихся 8-го класса.
 |
Прежде чем дать формулу коэффициента корреляции, попробуем проследить логику ее возникновения, используя данные примера 6.1. Положение каждой /-точки (испытуемого с номером /) на диаграмме рассеивания относительно остальных точек (рис. 6.3) может быть задано величинами и знаками отклонений соответствующих значений переменных от своих средних величин: (xj — MJ и (у, —Му). Если знаки этих отклонений совпадают, то это свидетельствует в пользу положительной взаимосвязи (большим значениям по х соответствуют большие значения по у или меньшим значениям по х соответствуют меньшие значения по у). Связь между этими переменными можно изобразить при помощи диаграммы рассеивания (см. рис. 6.3). Диаграмма показывает, что существует некоторая взаимосвязь измеренных показателей: чем больше значения вербального интеллекта, тем (преимущественно) больше значения невербального интеллекта.
 |
9 10 11
Вербальный IQ
Рис. 6.3. Диаграмма рассеивания для данных примера 6.1
ПРИМЕР
Для испытуемого № 1 отклонение от среднего по х и по у положительное, а для испытуемого № 3 и то и другое отклонения отрицательные. Следовательно, данные того и другого свидетельствуют о положительной взаимосвязи изучаемых признаков. Напротив, если знаки отклонений от средних по х и по у различаются, то это будет свидетельствовать об отрицательной взаимосвязи между признаками. Так, для испытуемого № 4 отклонение от среднего по х является отрицательным, по у — положительным, а для испытуемого № 9 — наоборот.
Таким образом, если произведение отклонений (х,— Мх) х (у, — Му) положительное, то данные /-испытуемого свидетельствуют о прямой (положительной) взаимосвязи, а если отрицательное — то об обратной (отрицательной) взаимосвязи. Соответственно, если х w у ъ основном связаны прямо пропорционально, то большинство произведений отклонений будет положительным, а если они связаны обратным соотношением, то большинство произведений будет отрицательным. Следовательно, общим показателем для силы и направления взаимосвязи может служить сумма всех произведений отклонений для данной выборки:
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
При прямо пропорциональной связи между переменными эта величина является большой и положительной — для большинства испытуемых отклонения совпадают по знаку (большим значениям одной переменной соответствуют большие значения другой переменной и наоборот). Если же х и у имеют обратную связь, то для большинства испытуемых большим значениям одной переменной будут соответствовать меньшие значения другой переменной, т. е. знаки произведений будут отрицательными, а сумма произведений в целом будет тоже большой по абсолютной величине, но отрицательной по знаку. Если систематической связи между переменными не будет наблюдаться, то положительные слагаемые (произведения отклонений) уравновесятся отрицательными слагаемыми, и сумма всех произведений отклонений будет близка к нулю.
Чтобы сумма произведений не зависела от объема выборки, достаточно ее усреднить. Но мера взаимосвязи нас интересует не как генеральный параметр, а как вычисляемая его оценка — статистика. Поэтому, как и для формулы дисперсии, в этом случае поступим также, делим сумму произведений отклонений не на N, а на TV— 1. Получается мера связи, широко применяемая в физике и технических науках, которая называется ковариацией (Covahance):
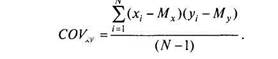 |
13 психологии, в отличие от физики, большинство переменных измеряются в произвольных шкалах, так как психологов интересует не абсолютное значение признака, а взаимное расположение испытуемых в группе. К тому же ковариация весьма чувствительна к масштабу шкалы (дисперсии), в которой измерены признаки. Чтобы сделать меру связи независимой от единиц измерения того и другого признака, достаточно разделить ковариацию на соответствующие стандартные отклонения. Таким образом и была получена формула коэффициента корреляции К. Пирсона:
 |
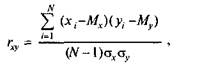 (6.1) или, после подстановки выражений для ох и gv:
(6.1) или, после подстановки выражений для ох и gv:
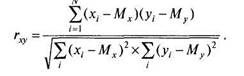 |
Уравнение (6.1) является основной формулой коэффициента корреляции Пирсона. Эта формула вполне осмысленна, но не очень удобна для вычислений «вручную» или на калькуляторе. Поэтому существуют производные формулы — более громоздкие по виду, менее доступные осмыслению, но упрощающие расчеты. Мы не будем их здесь приводить, так как один раз в жизни можно в учебных целях посчитать корреляцию Пирсона и по исходной формуле «вручную», а в дальнейшем для обработки реальных данных все равно придется воспользоваться компьютерными программами.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
ПРИМЕР 6.2
Для расчета коэффициента корреляции воспользуемся данными примера 6.1 о вербальном и невербальном IQ, измеренном у 20 учащихся 8-го класса. К двум столбцам с исходными данными добавляются еще 5 столбцов для дополнительных расчетов, и внизу — строка сумм.
| № | X | Y | {х,-Мх) | (х, - A/V)(.y, - Му) | |||
| 3,2 | 1,6 | 10,24 | 2,56 | 5,12 | |||
| -0,8 | 0,6 | 0,64 | 0,36 | -0,48 | |||
| -1,8 | -2,4 | 3,24 | 5,76 | 4,32 | |||
| -0,8 | 1,6 | 0,64 | 2,56 | -1,28 | |||
| -2,8 | -1,4 | 7,84 | 1,96 | 3,92 | |||
| -0,8 | 0,6 | 0,64 | 0,36 | -0,48 | |||
| -1,8 | -1,4 | 3,24 | 1,96 | 2,52 | |||
| 3,2 | 2,6 | 10,24 | 6,76 | 8,32 | |||
| 1,2 | -1,4 | 1,44 | 1,96 | -1,68 | |||
| 2,2 | -0,4 | 4,84 | 0,16 | -0,88 | |||
| -1,8 | -1,4 | 3,24 | 1,96 | 2,52 | |||
| -0,8 | -2,4 | 0,64 | 5,76 | 1,92 | |||
| 0,2 | -0,4 | 0,04 | 0,16 | -0,08 | |||
| 0,2 | 1,6 | 0,04 | 2,56 | 0,32 | |||
| 2,2 | -0,4 | 4,84 | 0,16 | -0,88 | |||
| 0,2 | -0,4 | 0,04 | 0,16 | -0,08 | |||
| -1,8 | 0,6 | 3,24 | 0,36 | -1,08 | |||
| -0,8 | -0,4 | 0,64 | 0,16 | 0,32 | |||
| 0,2 | 0,6 | 0,04 | 0,36 | 0,12 | |||
| 1,2 | 2,6 | 1,44 | 6,76 | 3,12 | |||
| X | 0,00 | 0,00 | 57,2 | 42,8 | 25,6 |
На первом шаге подсчитываются суммы всех значений одного, затем — другого признака для вычисления соответствующих средних значений Мх и Му: Мх = 9,8; Л/, = 10,4.
Далее для каждого испытуемого вычисляются отклонения от среднего: для Х\\ для Y. Каждое отклонение от среднего возводится в квадрат. В последнем столбике записывается результат перемножения двух отклонений от среднего для каждого испытуемого.
Суммы отклонений от среднего для каждой переменной должны быть равны нулю (с точностью до погрешности вычислений). Сумма квадратов отклонений необходима для вычисления стандартных отклонений по известной формуле (4.7):
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
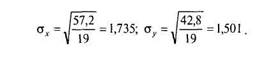
Сумма произведений отклонений дает нам значение числителя, а произведение стандартных отклонений и (./V— 1) — значение знаменателя формулы коэффициента корреляции:
- - 25'6 - = 0,517.
" 1,735 1,501 19
Если значения той и другой переменной были преобразованы в г-значения по формуле:
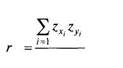 |
то формула коэффициента 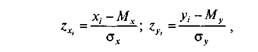 корреляции r-Пирсона выглядит проще:
корреляции r-Пирсона выглядит проще:
N
39 N-l '
Отметим еще раз: на величину коэффициента корреляции не влияет то, в каких единицах измерения представлены признаки. Следовательно, любые линейные преобразования признаков (умножение на константу, прибавление константы: у; = хр + а) не меняют значения коэффициента корреляции. Исключением является умножение одного из признаков на отрицательную константу: коэффициент корреляции меняет свой знак на противоположный.
На рис. 6.2 приведены примеры диаграмм рассеивания для различных значений коэффициента корреляции. Обратите внимание: на последнем рисунке визуально наблюдается нелинейная взаимосвязь между переменными, однако коэффициент корреляции равен нулю. Таким образом, коэффициент корреляции Пирсона есть мера прямолинейной взаимосвязи; он не чувствителен к криволинейным связям.
КОРРЕЛЯЦИЯ, РЕГРЕССИЯ И КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ
Корреляция Пирсона есть мера линейной связи между двумя переменными. Она позволяет определить, насколько пропорциональна изменчивость двух переменных. Если переменные пропорциональны друг другу, то графически связь между ними можно представить в виде прямой линии с положительным (прямая пропорция) или отрицательным (обратная пропорция) наклоном. Кроме того, если известна пропорция между переменными, заданная уравнением графика прямой линии: то по известным значениям переменной ЛГ можно точно предсказать значения переменной Y.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
На практике связь между двумя переменными, если она есть, является вероятностной и графически выглядит как облако рассеивания эллипсоидной формы. Этот эллипсоид, однако, можно представить (аппроксимировать) в виде прямой линии, или линии регрессии. Линия регрессии (Regression Line) — это прямая, построенная методом наименьших квадратов: сумма квадратов расстояний (вычисленных по оси У) от каждой точки графика рассеивания до прямой является минимальной:
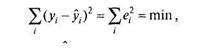 |
 |
где у, — истинное /-значение Y, у, — оценка /-значения Кпри помощи линии (уравнения) регрессии, е, =.у,— yt— ошибка оценки (см. рис. 6.4). Уравнение регрессии имеет вид:
 |
у-, = bXj+а, (6.2)
где b — коэффициент регрессии (Regression Coefficient), задающий угол наклона прямой; а — свободный член, определяющий точку пересечения прямой оси Y. Если известны средние, стандартные отклонения и корреляция гху, то сумма квадратов ошибок минимальна, если:
 |
о
b = r —^-,а = М„—ЬМг (f, i.\
у *. (6.3)
Таким образом, если на некоторой выборке измерены две переменные, которые коррелируют друг с другом, то, вычислив коэффициенты регрессии, мы получаем принципиальную возможность предсказания неизвестных значений одной переменной (У— «зависимая переменная») по известным значениям другой переменной (X — «независимая переменная»). Например, предсказываемой «зависимой переменной» может быть успешность обучения, а предиктором, «независимой переменной» — результаты вступительного теста.
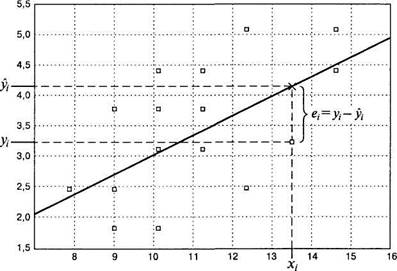
Рис. 6.4. Диаграмма рассеивания и линия регрессии (е,- — ошибка оценки для одного из объектов)
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
С какой степенью точности возможно такое предсказание?
Понятно, что наиболее точным предсказание будет, если \гху\ = 1. Тогда каждому значению Сбудет соответствовать только одно значение У, а все ошибки оценки будут равны 0 (все точки на графике рассеивания будут лежать на прямой регрессии). Если же гху — О, то b = О и у, = Му, т. е. при любом X оценка переменной Убудет равна ее среднему значению и предсказательная ценность регрессии ничтожна.
Особое значение для оценки точности предсказания имеет дисперсия оценок зависимой переменной. Отметим, что дисперсия оценок равна нулю, если гху = 0 — все оценки равны среднему значению, прямая регрессии параллельна оси X. А если \гху\ = 1, то дисперсия оценок равна истинной дисперсии переменной У, достигая своего максимума:
 |
0 < о) < а].
По сути, дисперсия оценок зависимой переменной У— это та часть ее полной дисперсии, которая обусловлена влиянием независимой переменной X.
Неизвестную дисперсию оценок У можно выразить через другие, известные статистики, зная рассмотренные ранее свойства дисперсии:
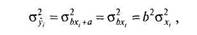
так как прибавление константы а к каждому значению переменной не меняет дисперсию, а умножение на константу b — увеличивает дисперсию в />2раз. Подставляя в формулу выражение для b из (6.2) получаем:
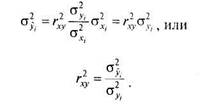 |
(6.4)
Иначе говоря, отношение дисперсии оценок зависимой переменной к ее истинной дисперсии равно квадрату коэффициента корреляции.
Выражение (6.4) дает еще один вариант интерпретации корреляции. Квадрат коэффициента корреляции (R Square) зависимой и независимой переменных представляет долю дисперсии зависимой переменной, обусловленной влиянием независимой переменной, и называется коэффициентом детерминации. Коэффициент детерминации гху, таким образом, показывает, в какой степени изменчивость одной переменной обусловлена (детерминирована) влиянием другой переменной.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
ПРИМЕР
В большинстве исследований взаимосвязи IQ и успеваемости в школе корреляции этих показателей не превышают 0,5—0,7, т. е. коэффициент детерминации достигает величин 0,25—0,49. Иными словами, индивидуальная изменчивость (дисперсия) среднего балла успеваемости может быть предсказана по результатам тестирования IQ не более чем на 25—49%. Означает ли это, что успешность обучения не более чем на 25—49% зависит от интеллекта? Ответ зависит от того, в какой мере средний балл отметок отражает успешность обучения, а тест IQ — интеллектуальные способности учащегося. Во всяком случае, этот пример демонстрирует явно не высокую эффективность двумерной регрессии в деле практического предсказания1.
Коэффициент детерминации обладает важным преимуществом по сравнению с коэффициентом корреляции. Корреляция не является линейной функцией связи между двумя переменными. Поэтому, в частности, среднее арифметическое коэффициентов корреляции для нескольких выборок не совпадает с корреляцией, вычисленной сразу для всех испытуемых из этих выборок (т. е. коэффициент корреляции не аддитивен). Напротив, коэффициент детерминации отражает связь линейно и поэтому является аддитивным: допускается его усреднение для нескольких выборок.
Дополнительную информацию о силе связи дает значение коэффициента корреляции в квадрате — коэффициент детерминации г2: это часть дисперсии одной переменной, которая может быть объяснена влиянием другой переменной. В отличие от коэффициента корреляции г2 линейно возрастает с увеличением силы связи. На этом основании можно ввести три градации величин корреляции по силе связи:
г < 0,3 — слабая связь (менее 10% от общей доли дисперсии);
0,3 < г < 0,7 — умеренная связь (от 10 до 50% от общей доли дисперсии);
г > 0,7 — сильная связь (50% и более от общей доли дисперсии).
ЧАСТНАЯ КОРРЕЛЯЦИЯ
Очень часто две переменные коррелируют друг с другом только за счет того, что обе они согласованно меняются под влиянием некоторой третьей переменной. Иными словами, на самом деле связь между соответствующими свойствами отсутствует, но проявляется в статистической взаимосвязи (корреляции) под влиянием общей причины.
ПРИМЕР
Общей причиной изменчивости двух переменных («третьей переменной») может являться возраст при изучении взаимосвязи различных психологических особенностей в группе детей разного возраста. Предположим, что изучается взаимосвязь между зрелостью моральных суждений — Хп скоростью чтения — К. Но в распоряжении 1 С более совершенными методами предсказания книга знакомит вас в части 3: «Многомерные методы...»
1 С более совершенными методами предсказания книга знакомит вас в части 3: «Многомерные методы...»
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
исследователя имеется лишь выборка из 45 детей разного возраста — от 8 до 14 лет (переменная Z— возраст). Если будет получена существенная положительная корреляция между Хи Y, например гху = 0,54, то о чем это будет свидетельствовать? Осторожный исследователь вряд ли сделает однозначный вывод о том, что зрелость моральных суждений непосредственно связана со скоростью чтения. Скорее всего, дело втом, что и зрелость моральных суждений, и скорость чтения повышаются с возрастом. Иными словами, возраст является причиной согласованной (прямо пропорциональной) изменчивости и зрелости моральных суждений, и скорости чтения.
Для численного определения степени взаимосвязи двух переменных при условии исключения влияния третьей применяют коэффициент частной корреляции {Partial Correlation). Для вычисления частной корреляции достаточно знать три коэффициента корреляции г-Пирсона между переменными X, Yu Zfr^, rxz и ryz):
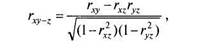 |
(6.5)
где rxy^z — частная корреляция Хи Упри постоянном Z(kiih с учетом Z).
Частная корреляция rxy_z равна гху при любом фиксированном значении Z (в том случае, если Zлинeйнo коррелирует с Хтл У). Например, если значение частной корреляции скорости чтения Хи зрелости моральных суждений К с учетом возраста ZpaBHO 0,2 {rxy__z = 0,2) и возраст линейно коррелирует и с Хи с У, то с любой группе детей одного и того же возраста гху будет тоже равно 0,2.
ПРИМЕР 6.3
 |
Один исследователь решил сопоставить антропометрические и психологические данные исследования довольно большой группы детей. Каково же было его изумление, когда обнаружилась существенная положительная корреляция между скоростью решения арифметических задач и размером стопы: гху = 0,42. Оказалось, однако, что дети были разного возраста. Корреляция размера стопы с возрастом составила rxy = QJ, а корреляция скорости решения арифметических задач с возрастом гу, = 0,6. Эти данные позволяют выяснить, взаимосвязаны ли размер стопы и скорость решения арифметических задач с учетом возраста (при условии, что возраст остается неизменным). Для этого необходимо вычислить частный коэффициент корреляции между размером стопы Хи скоростью решения арифметических задач К(при фиксированном возрасте Z):
 |
0,42-0,7-0,6
rxy-z = I = "
V(l-0,72)(l-0,62)
Таким образом, размер стопы и скорость решения арифметических задач коррелируют исключительно за счет согласованности возрастной изменчивости этих показателей: частная корреляция между ними (с учетом возраста) равна нулю. И если мы возьмем группу детей одного и того же возраста, то корреляция размера стопы и скорости решения арифметических задач будет равна нулю.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
Следует быть особенно осторожным, пытаясь дать интерпретацию частной корреляции с позиций причинности. Например, если Zкоррелирует и с 1и с Y, а частная корреляция rxy_z близка к нулю, из этого не обязательно следует, что именно Zявляeтcя общей причиной для Хн Y.
РАНГОВЫЕ КОРРЕЛЯЦИИ
Если обе переменные, между которыми изучается связь, представлены в порядковой шкале, или одна из них — в порядковой, а другая — в метрической, то применяются ранговые коэффициенты корреляции: r-Спирмена или т-Кенделла. И тот, и другой коэффициент требует для своего применения предварительного ранжирования обеих переменных.
Коэффициент корреляции г-Спирмена
Если члены группы численностью /Убыли ранжированы сначала по переменной X, затем — по переменной Y, то корреляцию между переменными Хм Кможно получить, просто вычислив коэффициент r-Пирсона для двух рядов рангов. При условии отсутствия связей в рангах (т. е. отсутствия повторяющихся рангов) по той и другой переменной, формула для r-Пирсона может быть существенно упрощена в вычислительном отношении и преобразована в формулу, известную как г-Спирмена:
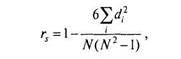 |
(6.6)
где с/, — разность рангов для испытуемого с номером /.
Коэффициент корреляции r-Спирмена (Spearman's rho) равен коэффициенту корреляции /--Пирсона, вычисленному для двух предварительно ранжированных переменных.
ПРИМЕР 6.4
Предположим, для каждого из 12 учащихся одного класса известно время решения тестовой арифметической задачи в секундах (X) и средний балл отметок по математике за последнюю четверть (Y).
| № | X | Y | Ранги X | Ранги Y | d, | d] |
| 4,7 | 2 | |||||
| 4,5 | ||||||
| 4,4 | ||||||
| 3,8 | -4 |
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
| № | X | Y | Ранги X | Ранги У | d, | d] |
| 3,7 | _4 | |||||
| 4,6 | ||||||
| 4,0 | -5 | |||||
| 4,2 | -5 | |||||
| 4,1 | ||||||
| 3,6 | _7 | |||||
| 3,5 | -10 | |||||
| 4,8 | ||||||
| S | - | - |
Для расчета корреляции г-Спирмена сначала необходимо ранжировать учащихся по той и другой переменной. После ранжирования можно проверить его правильность: сумма рангов должна быть равна N(N+ l)/2. Затем для каждого испытуемого надо вычислить разность рангов (сумма разностей рангов должна быть равна 0). После этого для каждого испытуемого вычисляется квадрат разности рангов — результат приведен в последнем столбце таблицы. Сумма квадратов разностей рангов равна 474. Подставляем известные значения в формулу 6.6:
 |
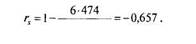 |
12(144-1)
Получена умеренная отрицательная связь между успеваемостью по математике и временем решения арифметической задачи.
Отметим: то же значение корреляции было бы получено при использовании формулы r-Пирсона непосредственно к рангам Хи Y. Применяя же формулу г-Пирсо-на к исходным значениям Хи Y, мы получим гху = —0,692.
Коэффициент корреляции т-Кендалла
Альтернативу корреляции Спирмена для рангов представляет корреляция т-Кендалла. В основе корреляции, предложенной М. Кендаллом, лежит идея о том, что о направлении связи можно судить, попарно сравнивая между собой испытуемых: если у пары испытуемых изменение по X совпадает по направлению с изменением по У, то это свидетельствует о положительной связи, если не совпадает — то об отрицательной связи.
В примере 6.3 данные испытуемых 1 и 2 свидетельствуют об отрицательной связи — мы видим инверсию: по переменной Ху второго испытуемого ранг больше, а по переменной У— меньше. Данные испытуемых 2 и 3, напротив, демонстрируют совпадение направления изменения переменных.
Корреляция т-Кендалла есть разность относительных частот совпадений и инверсий при переборе всех пар испытуемых в выборке:
x = P(p)-P(q),
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
где Р(р) и P(q) — относительные частоты, соответственно, совпадений и инверсий. Всего в выборке численностью УУ существует N(N— l)/2 всех возможных пар испытуемых. Следовательно,
P-Q
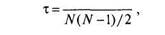
(6.7)
где Р — число совпадений, Q — число инверсий, а (Р+ Q) = N(N— l)/2. Формулу 6.7 можно представить и в ином виде:
 |
т = ^-^- = 1---- I^_ = _Zi----- 1. (6,8)
P + Q N(N-l) N(N-l)
При подсчете т-Кендалла «вручную» данные сначала упорядочиваются по переменной X. Затем для каждого испытуемого подсчитывается, сколько раз его ранг по доказывается меньше, чем ранг испытуемых, находящихся ниже. Результат записывается в столбец «Совпадения». Сумма всех значений столбца «Совпадения» и есть Р — общее число совпадений, подставляется в формулу 6.8. для вычисления т-Кендалла.
ПРИМЕР 6.5
Вычислим т-Кендалла для данных из примера 6.4. Сначала предварительно упорядочиваем испытуемых по переменной X. Затем подсчитываем число совпадений и инверсий для каждого испытуемого, сравнивая по Y его ранг с рангами испытуемых, находящихся под ним. Так, для первого испытуемого ранг по Кравен6,и 6 испытуемых, находящихся ниже него, имеют по Y более высокий ранг: в столбец «Совпадения» записываем 6. Для третьего по счету испытуемого ранг по Y равен 8, трое испытуемых ниже него имеют более высокий ранг, значит, в столбец «Совпадения» записываем 3, и т. д.
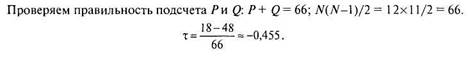 |
| № | Ранги X | Ранги Y | Совпадения | Инверсии |
| Р= 18 | 0 = 48 |
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Для более полной интерпретации полезны соотношения между величиной х-Кендалла и вероятностью отдельно совпадений и инверсий:
 |
Так, т = 0,5 значит, что вероятность совпадений равна 0,75, а вероятность инверсий — 0,25, то есть при сравнении объектов друг с другом прямо пропорциональное соотношение (например, роста и веса) встречается в 3 раза чаще, чем обратно пропорциональное соотношение. Такая интерпретация кажется более понятной, чем, например, интерпретация корреляции Пирсона г= 0,5: «25% изменчивости в весе могут быть объяснены различиями в росте».
т-Кендалла кажется более простым в вычислительном отношении. Однако при возрастании численности выборки, в отличие от л-Спирмена, объем вычислений х-Кендалла возрастает не пропорционально, а в геометрической прогрессии. Так, при N=12 необходимо перебрать 66 пар испытуемых, а при N = 48 — уже 1128 пар, т. е. объем вычислений вбзрастает более, чем в 17 раз.
Отметим важную особенность ранговых коэффициентов корреляции. Для метрической корреляции r-Пирсона значениям +1 или —1 соответствует прямая или обратная пропорция между переменными, что графически представляет собой прямую линию. Максимальным по модулю ранговым корреляциям (+1, —1) вовсе не обязательно соответствуют строгие прямо или обратно пропорциональные связи между исходными переменными Хи Y: достаточна лишь монотонная функциональная связь между ними. Иными словами, ранговые корреляции достигают своего максимального по модулю значения, если большему значению одной переменной всегда соответствует большее значение другой переменной (+1) или большему значению одной переменной всегда соответствует меньшее значение другой переменной и наоборот (—1).
Проблема связанных (одинаковых) рангов
В измерениях часто встречаются одинаковые значения. При их ранжировании возникает проблема связанных рангов (Tied Ranks). В этом случае действует особое правило ранжирования: объектам с одинаковыми значениями
 |
приписывается один и тот же, средний ранг. Например, когда эксперт не может установить различие между двумя лучшими образцами товара, им приписывается одинаковый ранг: (1 + 2)/2 = 1,5. Это сохраняет неизменной сумму рангов для выборки объемом N: N(N + l)/2.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
При наличии одинаковых (связанных) рангов формулы ранговой корреляции Спирмена (6.6) и Кендама (6.7и 6.8) не подходят. Хотя сумма рангов и не меняется, но изменчивость данных становится меньше. Соответственно, уменьшается возможность оценить степень связи между измеренными свойствами. При использовании корреляции Спирмена в случае связанных рангов возможны два подхода:
- если связей немного (менее 10% для каждой переменной), то вычислить r-Спирмена приближенно по формуле 6.6;
- при большем количестве связей применить к ранжированным данным классическую формулу /"-Пирсона 6.1 — это всегда позволит определить ранговую корреляцию независимо от наличия связей в рангах.
При использовании корреляции х-Кендалла в случае наличия связанных рангов в формулу вносятся поправки, и тогда получается общая формула для вычисления т. коэффициента корреляции хь-Кендалла (Kendall's tau-b) независимо от наличия или отсутствия связей в рангах:
 |
P-Q
'-l)/2]-Kxyj[N(N-l)/2]-Ky ' (6'9)
где х = (1/2)У/?(/?-1) (' — количество групп связей по X,ft — численность каждой группы); х = (1/2)У/(/)-1) (/ — количество групп связей по У,/ — численность каждой группы).

