 2014-02-17
2014-02-17 665
665Таблица 1. Возможности протоколов шифрования, используемых в беспроводных сетях
Таблица 2. Применимость различных способов обеспечения безопасности в зависимости от типа сети
| Тип сети | Корпоративная сеть | Сеть Hot-Spot | Мостовое соединение |
| Использование WPA2 | + | – | – |
| WPA | + | – | – |
| 802.1x | + | – | – |
| WEP | + | + | + |
| VPN | – | – | + |
| Вынос точки доступа за брандмауэр | + | + | + |
| Использование IDS | + | + | + |
| Аутентификация на пограничном ресурсе | + | + | – |
| Фильтрация по MAC-адресам | + | – | + |
| Отключение рассылки SSID | + | – | + |
Каким образом надежно защитить беспроводную сеть и можно ли это сделать в принципе? Ответ однозначный – да, можно, а каким именно образом, зависит от типа сети.
Если это небольшая сеть типа точка–точка – использовать WPA2. Если же корпоративная сеть, которая работает в режиме инфраструктуры, то рекомендуется применять все возможные средства защиты: скрытие SSID, списки доступа на основе MAC-адресов и, конечно же, WPA2-EAP. Каким образом корпоративную сеть защитить от чужих точек доступа? Вариант, когда точка доступа не подключена в локальную сеть компании, не страшен, так как для реализации такой атаки сначала понадобится взломать WPA2. А от варианта с подключением можно защититься разными способами:
· отключить неиспользуемые порты на коммутаторе;
· задействовать в локальной сети аутентификацию IEEE 802.1x;
· применять функцию Port Security (указать на коммутаторе, к каким портам какие MAC-адреса могут быть подключены);
· вынести точки беспроводного доступа за межсетевой экран или в отдельную виртуальную сеть и настроить правила контроля и ограничения трафика между этой сетью и остальными;
· использовать системы обнаружения вторжений (недавно появилась версия бесплатной популярной системы обнаружения вторжений Snort, предназначенная для беспроводных сетей), специальные беспроводные коммутаторы или точки доступа, позволяющие обнаруживать «чужие» устройства в сети.
Если это мостовое соединение, то следует создать туннель с помощью протоколов более высокого уровня, например IPsec между точками доступа. Последние являются устройствами канального уровня, и они, как правило, не умеют терминировать туннели. В данном случае за ними необходимо установить программные или аппаратные устройства, умеющие работать с IPsec.
Наиболее проблематичными в отношении безопасности являются сети публичного доступа («хот-споты»). В силу своей специфики в них нельзя применить ни WPA, ни WPA2, ни шифрование посредством IPsec, так как клиенты работают под разными ОС с разными сервис-паками и заплатками, соответственно, поддерживают различные механизмы аутентификации или не поддерживают никаких. В результате возможно применение только WEP-шифрования, которое не очень надежно. Кроме того, злоумышленник может получить WEP-ключ легальным путем, став пользователем сети публичного доступа. В этой ситуации для обеспечения безопасности, как правило, применяют повторную аутентификацию клиентов на каком-нибудь пограничном ресурсе, установленном за точкой доступа с помощью широко применяемых протоколов, в частности HTTP или HTTPS. При использовании HTTPS единственным уязвимым местом такой системы остается подверженность атакам с ложной точкой доступа, когда взломщик применяет свою точку для получения чужих идентификаторов и паролей. В данном случае пользователям хот-спотов нужно помнить, что их информация может попасть к другим, и при доступе к конфиденциальным ресурсам необходимо применять дополнительные методы защиты – например тот же IPsec. А оператору хот-спота стоит прибегнуть к единственному в данном случае способу защиты – системам обнаружения вторжения, специальным беспроводным коммутаторам и точкам доступа, позволяющим обнаружить чужака.
В заключение в качестве справочной информации приведем две сводные таблицы по возможностям протоколов шифрования и применимости различных способов обеспечения безопасности в зависимости от типа сети.
| Протокол | Open System | Shared Key | WPA-PSK | WPA-EAP | WPA2-PSK | WPA2-EAP |
| Алгоритм шифрования | RC4 | RC4 | RC4 | RC4 | AES (CTR) | AES (CTR) |
| Аутентификация | Отсутств. | Preshared Key | Preshared Key | IEEE 802.1x | Preshared Key | IEEE 802.1x |
| Длина ключа, бит | 64 или 128 | 64 или 128 | 128 (шифров.), 64 (аутент.) | 128 (шифров.), 64 (аутент.) | ||
| Повторяемость ключа | 24-битовый IV | 24-битовый IV | 48-битовый TSC | 48-битовый TSC | 48-битовый PN | 48-битовый PN |
| Целостность данных | CRC-32 | CRC-32 | Michael | Michael | AES (CBC-MAC) | AES (CBC-MAC) |
| Целостность заголовка | Отсутств. | Отсутств. | Michael | Michael | AES (CBC-MAC) | AES (CBC-MAC) |
| Управление ключами | Статические для всей сети | На основе EAP | Статич. для всей сети | На основе EAP |
Приложение к главе 2.
2.1. Протоколы интернета
2.1.1. Семейство протоколов TCP/IP
Термином TCP/IP называется целое семейство протоколов различного уровня. Сначала перечислим протоколы семейства.
· IP (Internet Protocol) – межсетевой протокол, давший название всему семейству;
· TCP (Transmission Control Protocol) - базовый транспортный протокол,
· UDP (User Datagram Protocol) - второй транспортный протокол, отличающийся от TCP;
· ARP (Address Resolution Protocol) - используется для определения соответствия IP-адресов и Ethernet-адресов;
· SLIP (Serial Line Internet Protocol) - протокол передачи данных по телефонным линиям;
· PPP (Point to Point Protocol) - протокол обмена данными "от точки к точке";
· FTP (File Transfer Protocol) - протокол обмена файлами;
· TELNET - протокол эмуляции виртуального терминала;
· RPC (Remote Process Control) - протокол управления удаленными процессами;
· TFTP (Trivial File Transfer Protocol) - тривиальный протокол передачи файлов;
· DNS (Domain Name System) - система доменных имен;
· RIP (Routing Information Protocol) - протокол маршрутизации;
· NFS (Network File System) - распределенная файловая система и система сетевой печати;
· SNMP (Simple Network ManagementProtocol) - простой протокол управления сетью.
К канальному уровню относятся стандарты SLIP и PPP. К сетевому (межсетевому) уровню относятся протоколы IP, ARP, ICMP. Транспортный уровень представлен протоколами TCP и UDP. Протоколы сервисов интернета (FTP, TELNET, HTTP, GOPHER и т.п.) относятся к высшему, прикладному уровню.
В терминологии TCP/IP кадром называется блок данных, который принимается или отправляется сетевым адаптером. IP-пакетом называется блок данных, которым обменивается IP-модуль с сетевым интерфейсом. UDP-датаграмма – это блок данных, которым обменивается IP-модуль с UDP-модулем. TCP-сегмент – это блок данных, которым обменивается IP-модуль с TCP-модулем. Наконец, прикладное сообщение – это блок данных, которым обмениваются программы сетевых приложений с протоколами транспортного уровня.
Инкапсуляциией называется способ упаковки сообщения в формате одного протокола в сообщение в формате другого протокола более низкого уровня (например, упаковка IP-пакета в кадр Ethernet или упаковка TCP-сегмента в IP-пакет). В рамках межсетевого обмена понятие инкапсуляции имеет расширенный смысл. Если в случае инкапсуляции IP-пакета речь идет действительно об упаковке IP-пакета внутри кадра Ethernet, то при передаче данных по коммутируемым каналам происходит дальнейшая разбиение пакетов на SLIP-пакеты или фреймы PPP.
Пусть прикладная программа сформировала сообщение, которое предназначено для отправки на другой компьютер. Это сообщение передается на вход одного из сетевых модулей. Сетевой модуль обрабатывает сообщение, если надо, разделяет его на пакеты, присоединяет заголовки и, в зависимости от результатов обработки, передает полученные пакеты тому или иному модулю. Следующий модуль проделывает аналогичную процедуру и т.д. Заканчивается процесс тогда, когда очередной пакет поступает на вход модуля сетевой системы (например, модуля ENET системы Ethernet).
Пакеты вседа передаются от модуля высшего уровня к модулю низшего уровня. Модуль выполняет операцию одного из уровней и использует при этом определенный протокол. В результате можно изобразить структуру модулей (и соответственно, структуру протоколов) в форме схемы, изображенной на рис 2.1.
При работе с некоторыми программами прикладного уровня (такими, как FTP или telnet) используется модуль TCP. При работе с другими прикладными программами (NFS) используется модуль UDP. При получении сообщения от прикладной программы модули TCP и UDP работают как демультиплексоры, т.е. перенаправляют данные с нескольких выходов на один вход. Хотя технология Интернет поддерживает много различных сред передачи данных, здесь мы будем предполагать использование Ethernet, так как именно эта среда чаще всего служит физической основой для IP-сети.
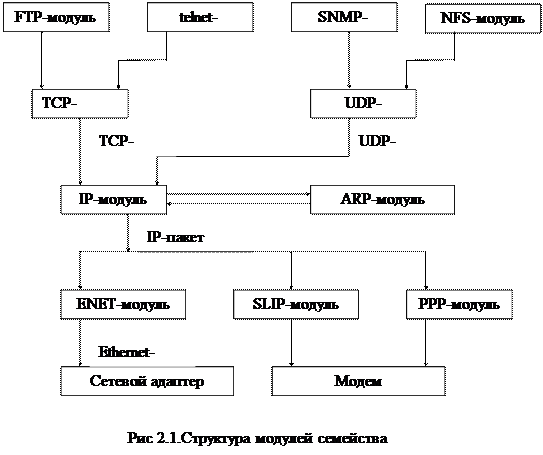
Машина, принявшая пакет, осуществляет мультиплексирование в соответствии с этими отметками. Пусть сообщение пришло на сетевой интерфейс компьютера. Когда Ethernet-кадр попадает в драйвер сетевого интерфейса Ethernet, он может быть направлен либо в ARP-модуль, либо в IP-модуль. На то, куда должен быть направлен Ethernet-кадр, указывает значение поля типа в заголовке кадра. Если IP-пакет попадает в модуль IP, то содержащиеся в нем данные могут быть переданы либо модулю TCP, либо UDP, что определяется полем “протокол” в заголовке IP-пакета. Если UDP-датаграмма попадает в модуль UDP, то на основании значения поля “порт” в заголовке датаграммы определяется прикладная программа, которой должно быть передано прикладное сообщение. Если TCP-сообщение попадает в модуль TCP, то выбор прикладной программы, которой должно быть передано сообщение, осуществляется на основе значения поля “порт” в заголовке TCP-пакета.
Машина может быть подключена одновременно к нескольким средам передачи данных. Для машин с несколькими сетевыми интерфейсами при отправлении пакета IP-модуль выполняет функции мультиплексора, так как он должен сделать выбор между несколькими сетевыми интерфейсами.Таким образом, он осуществляет мультиплексирование входных и выходных данных в обоих направлениях. Данные могут поступать через любой сетевой интерфейс и быть переданы через любой другой сетевой интерфейс.
Процесс получения пакета и немедленной передачи его в другую сеть называется ретрансляцией IP-пакета. Ретранслируемый пакет не передается модулям TCP или UDP. Некоторые шлюзы вообще могут не иметь модулей TCP и UDP.
Сначала попробуем разобраться, как устроены протоколы передачи данных. Удобнее вначале рассмотреть, как работает сетевой модуль при приеме сообщения. Уже было сказано ранее, что для этого модуля сообщение представляет собой информативную начальную часть – заголовок, содержательную среднюю часть, которая была инкапсулирована в данное сообщение и для данного модуля представляет собой черный ящик, и, быть может, информативную конечную часть – хвост сообщения. Работа модуля заключается в анализе заголовка и хвоста сообщения. Для этого прежде всего необходимо уметь выделять заголовок и хвост.
Тут может быть три способа. Либо все части сообщения имеют фиксированную заранее оговоренную длину, либо они будут выделены специальными маркерами, либо структура сообщения будет определяться в процессе анализа. Чаще всего используется последняя идея. Обычно протокол характеризуется набором полей, имеющих индивидуальную длину, измеряемую в байтах или битах. Однако заголовок конкретного сообщения не обязан включать все поля. Включение или невключение того или иного поля зависит от значения предшествующих полей заголовка. Протокол должен быть устроен таким образом, чтобы при последовательном просмотре сообщения для каждого текущего бита должно быть известно, к какому полю этот бит относится. Аналогично определяется начало содержательной части сообщения и хвост сообщения.
Проиллюстрируем сказанное на примере структуры IP-адреса, которая является частью протокола IP. Напомним, что IP-адрес узла идентифицирует сетевой адаптер, а не всю машину. IP-адрес имеет фиксированную длину, равную 4 байтам (32 битам). Старшие биты IP-адреса определяют номер IP-сети. Оставшаяся часть IP-адреса изображает внутренний номер узла в сети (хост-номер). Существуют 5 классов IP-адресов, отличающиеся количеством бит в сетевом номере и хост-номере. Класс адреса определяется значением старших битов первого байта. В табл. 2.1 приведены классы адресов и указано количество возможных IP-адресов каждого класса.
Таблица 2.1
Характеристики классов IP-адресов
| Класс | 1-й байт | Значения первого байта | 2-й байт | 3-й байт | 4-й байт | Возможое кол-во сетей | Возможое кол-во узлов |
| А | 0 + номер сети | 1 – 126 | Узел | ||||
| B | 10 + начало номера сети | 128 – 191 | Сеть | Узел | |||
| C | 110 + начало номера сети | 192 – 223 | Сеть | Узел | |||
| D | 1110 + начало номера группы | 224 – 239 | Группа | - | 218 | ||
| E | 240 – 247 | Зарезервировано |
Например, для машины с IP-адресом 221.137.10.34 сетевой номер равен 221.137.10, а хост-номер равен 34. Число 221 – это содержимое первого байта. Оно попадает в диапазон 192-223, поэтому данный IP-адрес относится к классу C. Числа 137 и 10 – соответственно содержимое второго и третьего байтов IP-адреса.
Адреса класса A предназначены для использования в больших сетях общего пользования. Они допускают большое количество номеров узлов. Адреса класса B используются в сетях среднего размера, например, сетях университетов и крупных компаний. Адреса класса C используются в сетях с небольшим числом компьютеров. Адреса класса D используются при обращениях к группам машин, а адреса класса E зарезервированы на будущее.
Прежде, чем вы начнете использовать сеть с TCP/IP, вы должны получить один или несколько официальных сетевых номеров. Выделением номеров (каки многими другими вопросами) занимается DDN Network Information Center (NIC). Выделение номеров производится бесплатно и занимает около недели. Вы можете получить сетевой номер вне зависимости от того, для чего предназначена ваша сеть. Даже если ваша сеть не имеет связи с объединенной сетью Internet, получение уникального номера желательно, так как в этом случае есть гарантия, что в будущем при включении в Internet или при подключении к сети другой организации не возникнет конфликта адресов. Одно из важнейших решений, которое необходимо принять при установке сети, заключается в выборе способа присвоения IP-адресов вашим машинам.Этот выбор должен учитывать перспективу роста сети. Иначе в дальнейшем вам придется менять адреса. Когда к сети подключено несколько сотен машин, изменение адресов становится почти невозможным. Организации, имеющие небольшие сети с числом узлов до 126, должны запрашивать сетевые номера класса C. Организации с большим числом машин могут получить несколько номеров класса C или номер класса B. Удобным средством структуризации сетей в рамках одной организации являются подсети.
2.1.2. Ethernet-кадр
Ethernet-кадр в заголовке содержит Ethernet-адрес назначения, Ethernet-адрес источника, поле типа пакета и еще некоторые данные. Важной особенностью Ethernet является то, что каждая сетевая карта имеет свой уникальный номер. Каждому производителю сетевых карт выделен свой диапазон номеров, в пределах которого он может нумеровать свои карты. Этот номер рассчитан на шесть байтов. Ethernet-адрес обычно записывается в виде шести групп шестнадцатиричных цифр по две в каждой (например, 2B:17:9A:23:DF:B7). Первые три байта называются префиксом, и именно они закреплены за производителем. Каждый префикс определяет диапазон из почти 17-ти млн. номеров.
При получении кадра сетевым драйвером считываются Ethernet-адреса источника и места назначения, указанные в заголовке кадра. Кроме того, считывается тип пакета. Работающий сетевой адаптер знает свой Ethernet-адрес. Если адрес назначения совпадает с собственным адресом, драйвер начинает принимать Ethernet-кадр.
Пусть тип кадра говорит о том, что его содержимое является IP-пакетом. Кроме Ethernet-адреса, сетевой адаптер имеет также четырехбайтный IP-адрес, который уникален в пределах всей сети Internet. Этот адрес обозначает точку доступа к сети IP-модуля (для сетевого драйвера). Работающий компьютер всегда знает также и свой IP-адрес.
При отправке IP-пакета необходимо по IP-адресу места назначения определить Ethernet-адрес с тем, чтобы записать это значение в поле адреса назначения Ethernet-кадра. Если все это происходит в пределах локальной сети, то для поиска используется специальная таблица соответствия IP-адресов Ethernet-адресам. Структура этой таблицы описывается протоколом ARP (Address Resolution Protocol).
Упрощенно, ARP-таблица состоит из двух столбцов:
IP-адрес Ethernet-адрес
223.1.2.1 08:00:39:00:2F:C3
223.1.2.3 08:00:5A:21:A7:22
223.1.2.4 08:00:10:99:AC:54
Если меняются IP-адреса, то ARP-таблица должна быть изменена. Это может быть сделано автоматически определенной процедурой. В сеть посылается широковещательный запрос типа "чей это IP-адрес?". Все сетевые интерфейсы получают этот запрос, но отвечает только владелец адреса. Если он есть, то соответствующая строка добавляется в ARP-таблицу. Следует отметить, что если искомого IP-адреса нет в локальной сети и сеть не соединена с другой сетью шлюзом, то разрешить запрос не удается. IP-модуль будет уничтожать такие пакеты, обычно по time-out (превышен лимит времени на разрешение запроса). Модули прикладного уровня при этом не могут отличить физического повреждения сети от ошибки адресации.
Однако в современной сети Internet, как правило, запрашивается информация с узлов, которые реально в локальную сеть не входят. В этом случае для разрешения адресных коллизий и отправки пакетов используется модуль IP.
Если компьютер соединен с несколькими сетями, т.е. является шлюзом, то в таблицу ARP вносятся строки, которые описывают как одну, так и другую IP-сети. При использовании Ethernet и IP каждый сетевой интерфейс имеет как минимум один адрес Ethernet и один IP-адрес. Если компьютер имеет несколько интерфейсов, то это автоматически означает, что каждому интерфейсу будет назначен свой Ethernet-адрес. IP-адрес назначается для каждого драйвера сетевого интерфейса. Грубо говоря, каждой сетевой карте Ethernet соответствуют один Ethernet-адрес и один IP-адрес. IP-адрес уникален в рамках всего Internet.
Сетевой адаптер контролирует обмен информацией, происходящий в сети, и принимает адресованные ему Ethernet-кадры, а также Ethernet-кадры с адресом "FF:FF:FF:FF:FF:FF" (в 16-ричной системе), который обозначает "всем", и используется при широковещательной передаче. Ethernet реализует метод доступа, называемый методом множественного доступа с контролем несущей и обнаружением столкновений. Этот метод предполагает, что все устройства взаимодействуют в одной среде, в каждый момент времени может передавать только одно устройство, а принимать могут все одновременно. Если два устройства пытаются передавать одновременно, то происходит столкновение передач, и оба устройства после случайного (краткого) периода ожидания пытаются вновь выполнить передачу. Понятно, что чем больше компьютеров подключено в сегменте Ethernet, тем больше столкновений будет зафиксировано и тем медленнее будет работать сеть. Кроме того, если в сети стоит сервер, к которому часто обращаются, то это также снизит общую производительность сети.
2.1.3. Протокол SLIP
Протоколы SLIP (Serial Line Internet Protocol) или PPP (Point to Point Protocol) обеспечивают передачу пакетов TCP/IP по последовательным каналам, в частности, телефонным линиям, между двумя компьютерами. На обоих компьютерах работают программы, использующие протоколы TCP/IP. Индивидуальные пользователи получают возможность устанавливать прямое соединение с Internet со своего компьютера, имея модем и телефонную линию.
Технология TCP/IP позволяет организовать межсетевое взаимодействие, используя различные физические и канальные протоколы обмена данными. Однако, без обмена данными по телефонным линиям связи с использованием обычных модемов популярность Internet была бы значительно ниже. Большинство пользователей Сети используют свой домашний телефон в качестве окна в мир компьютерных сетей, подключая компьютер через модем к модемному пулу компании, предоставляющей IP-услуги или к своему рабочему компьютеру. Наиболее простым способом, обеспечивающим полный IP-сервис, является подключение через последовательный порт персонального компьютера по протоколу SLIP.
В отличии от Ethernet, SLIP не "заворачивает" IP-пакет в свою обертку, а "нарезает" его на "кусочки". При этом делает это довольно примитивно. SLIP-пакет начинается символом ESC (восьмеричное 333 или десятичное 219) и кончается символом END (восьмеричное 300 или десятичное 192). Если внутри пакета встречаются эти символы, то они заменяются двухбайтовыми последовательностями ESC-END (333 334) и ESC-ESC (333 335). Стандарт не определяет размер SLIP-пакета. SLIP-модуль не анализирует поток данных и не выделяет какую-либо информацию в этом потоке. Он просто "нарезает" ее на "кусочки", каждый из которых начинается символом ESC, а кончается символом END. Из приведенного выше описания понятно, что SLIP не позволяет выполнять какие-либо действия, связанные с адресами, т.к. в структуре пакета не предусмотрено поле адреса и его специальная обработка. Компьютеры, взаимодействующие по SLIP, обязаны знать свои IP-адреса заранее. SLIP не позволяет различать пакеты по типу протокола. Вообще-то, при работе по SLIP предполагается использование только IP (что отражено в названии), но простота пакета может быть соблазнительной и для других протоколов. В SLIP нет информации, позволяющей корректировать ошибки линии связи. Коррекция ошибок возлагается на модули транспортного уровня - TCP, UDP.
SLIP/PPP действительно способ прямого соединения с Internet, поскольку:
¨ компьютер подсоединен к Internet;
¨ компьютер использует сетевое обеспечение для общения с другими компьютерами по протоколу TCP/IP;
¨ компьютер имеет уникальный IP-адрес.
Подключаясь посредством SLIP/PPP, можно запускать программы-клиенты WWW, электронной почты и т.п. непосредственно на своем компьютере. В чем же различие между SLIP/PPP-соединением и режимом удаленного терминала? Для установления как SLIP/PPP-соединения, так и режима удаленного терминала необходимо дозвониться к другому компьютеру, непосредственно соединенному с Internet (провайдеру) и зарегистрироваться на нем. Ключевое отличие состоит в том, что при SLIP/PPP-соединении Ваш компьютер получает уникальный IP-адрес и напрямую общается с другими компьютерами по протоколу TCP/IP. В режиме же удаленного терминала Ваш компьютер является всего лишь устройством отображения результатов работы программы, запущенной на компьютере провайдера.
В протоколе SLIP нет определения понятия "SLIP-сервер", но реальная жизнь вносит коррективы в стандарты. В контексте нашего изложения "SLIP-клиент" - это компьютер, инициирующий физическое соединение, а "SLIP-сервер" - это машина, постоянно включенная в IP-сеть.
2.1.4. Протокол PPP
Соединения типа "точка-точка" - протокол PPP (Point to Point Protocol). PPP - это более молодой протокол, нежели SLIP. Однако, назначение у него то же самое - управление передачей данных по выделенным или коммутируемым линиям связи. PPP обеспечивает стандартный метод взаимодействия двух узлов сети. Предполагается, что обеспечивается двунаправленная одновременная передача данных. Как и в SLIP, данные "нарезаются" на фрагменты, которые называются PPP-пакетами. Пакеты передаются от узла к узлу упорядоченно. В отличие от SLIP, PPP позволяет одновременно передавать по линии связи PPP-пакеты, содержащие внутри пакеты различных протоколов. Кроме того, PPP предполагает процесс автоконфигурации обоих взаимодействующих сторон. Собственно говоря, PPP состоит из трех частей: механизма инкапсуляции (encapsulation), протокола управления соединением (link control protocol) и семейства протоколов управления сетью (network control protocols).
В заголовке PPP-пакета, иногда называемого фреймом, в поле "протокол" указывается тип инкапсулированной содержательной части. Существуют специальные правила кодирования протоколов в этом поле. Далее в поле "информация" записывается собственно пакет данных, а в поле "хвост" добавляется "пустышка" для выравнивания на 32-битовую границу. По умолчанию для пакета PPP используется 1500 байтов. В это число не входит поле "протокол".
Протокол управления соединением предназначен для установки соглашения между узлами сети о параметрах инкапсуляции (размер фрейма, например). Кроме этого, протокол позволяет проводить идентификацию узлов. Первой фазой установки соединения является проверка готовности физического уровня передачи данных. При этом, такая проверка может осуществляться периодически, позволяя реализовать механизм автоматического восстановления физического соединения как это бывает при работе через модем по коммутируемой линии. Если физическое соединение установлено, то узлы начинают обмен пакетами протокола управления соединением, настраивая параметры сессии. Любой пакет, отличный от пакета протокола управления соединением, не обрабатывается во время этого обмена. После установки параметров соединения возможен переход к идентификации. Идентификация не является обязательной. После всех этих действий происходит настройка параметров работы с протоколами межсетевого обмена (IP, IPX и т.п.). Для каждого из них используется свой протокол управления. Для завершения работы по протоколу PPP по сети передается пакет завершения работы протокола управления соединением.
Процедура конфигурации сетевых модулей операционной системы для работы по протоколу PPP более сложное занятие, чем аналогичная процедура для протокола SLIP. Однако, возможности PPP соединения гораздо более широкие. Так например, при работе через модем модуль PPP, обычно, сам восстанавливает соединение при потере несущей частоты. Кроме того, модуль PPP сам определяет параметры своих фреймов, в то время как при SLIP их надо подбирать вручную. Правда, если настраивать оба конца, то многие проблемы не возникают из-за того, что параметры соединения известны заранее. Более подробно с протоколом PPP можно познакомиться в RFC-1661 и RFC-1548.
2.1.5. Межсетевой протокол IP
Модуль IP является базовым элементом технологии Интернет. При отправке данных этот модуль инкапсулирует переданное ему сообщение в IP-пакет, добавляя в заголовок поля, из которых основными являются IP-адрес источника, IP-адрес места назначения и поле «протокол». В поле «протокол» указывается тот модуль, которому должно быть передано инкапсулированное внутри IP-пакета сообщение. Центральной частью IP-модуля является его таблица маршрутов. Модуль IP использует эту таблицу при принятии всех решений о маршрутизации IP-пакетов. Чтобы понять технику межсетевого взаимодействия, нужно понять то, как используется таблица маршрутов. Пример таблицы маршрутов указан на рис.2.2.
| Номер сети | Прямая/косвенная маршрутизация | IP-адрес шлюза | Номер сетевого интерфейса |
| 223.1.2 | Прямая | ||
| 223.1.3 | Косвенная | 223.1.4.1 |
Рис.2.2. Таблица маршрутов
Пусть модуль IP должен отправить IP-пакет другому компьютеру B. Для этого надо определить, через какой сетевой интерфейс сообщение должно быть отправлено и какой Ethernet-адрес должен быть указан в качестве адреса назначения пакета. Пусть компьютер B имеет IP-адрес 223.1.2.2. Ключом поиска служит номер IP-сети, выделенный из IP-адреса места назначения IP-пакета. Модуль IP с помощью маски подсети выделяет номер сети из IP-адреса B. Номер сети равен 223.1.2. В таблице маршрутов ему соответствует первая строка. В этой строке указано, что флаг маршрутизации имеет значение «прямая», а посылать сообщение надо через 1-й интерфейс. С помощью ARP-таблицы выполняется преобразование IP-адреса 223.1.2.2 в соответствующий Ethernet-адрес, и через 1-й интерфейс Ethernet-кадр посылается узлу В.
Пусть теперь узел IP-модуль посылает IP-пакет узлу В с адресом 223.1.3.2. Сетевому номеру 223.1.3 в таблице маршрутов соответсвует вторая строка. Поскольку флаг маршрутизации во второй строке имеет значение «косвенная», сообщение должно быть послано через шлюз C, IP-адрес которого 223.1.4.1 указан в третьем столбце. Модуль IP осуществляет поиск в ARP-таблице, с помощью которого определяет Ethernet-адрес, соответствующий адресу шлюза 223.1.4.1. Но на место IP-адреса вставляется не адрес шлюза C, а адрес узла B, то есть IP-адрес назначения в этом пакете не соответствует Ethernet-адресу назначения. Затем пакет посылается через интерфейс 2, указанный во второй строке, шлюзу С. IP-пакет принимается сетевым интерфейсом в узле С и передается модулю IP компьютера C. Модуль проверяет IP-адрес места назначения, и, поскольку он не соответствует ни одному из собственных IP-адресов С, шлюз решает ретранслировать IP-пакет. Следуя тому же алгоритму, модуль IP в узле С выделяет сетевой номер из IP-адреса места назначения IP-пакета (223.1.3) и ищет соответствующую запись уже в своей таблице маршрутов. Если соответствующая строка характеризуется прямой маршрутизацией, пакет ретранслируется напрямую, в противном случае он опять направляется в шлюз и т.д. После того, как IP-пакет достигнет узла B, содержащееся в IP-пакете сообщение передается протокольному модулю верхнего уровня (согласно значению поля «протокол»).
Если прикладная программа пытается послать данные по IP-адресу, который не принадлежит сети, то модуль IP не сможет найти соответствующую запись в таблице маршрутов. В этом случае модуль IP отбрасывает IP-пакет. Некоторые реализации протокола возвращают сообщение об ошибке "Сеть не доступна".
Итак, для отправляемых IP-пакетов, поступающих от модулей верхнего уровня, модуль IP должен определить способ доставки - прямой или косвенный - и выбрать сетевой интерфейс. Этот выбор делается на основании результатов поиска в таблице маршрутов. Для принимаемых IP-пакетов, поступающих от сетевых драйверов, модуль IP должен решить, нужно ли ретранслировать IP-пакет по другой сети или передать его на верхний уровень другому модулю (TCP или UDP). Если модуль IP решит, что IP-пакет должен быть ретранслирован, то дальнейшая работа с ним осуществляется также, как с отправляемыми IP-пакетами. Входящий IP-пакет никогда не ретранслируется через тот же сетевой интерфейс, через который он был принят. Решение о маршрутизации принимается до того, как IP-пакет передается сетевому драйверу, и до того, как происходит обращение к ARP-таблице.
Содержание таблицы маршрутов определяется администратором сети. Ошибки при установке маршрутов могут заблокировать передачу данных.
Адресное пространство сети TCP/IP может быть разделено на непересекающиеся подпространства - "подсети", с каждой из которых можно работать как с обычной сетью TCP/IP. Таким образом единая IP-сеть организации может строиться как объединение подсетей. Как правило, подсеть соответствует одной физической сети, например, одной сети Ethernet. Конечно, использование подсетей необязательно. Можно просто назначить для каждой физической сети свой сетевой номер. Однако такое решение имеет два недостатка. Первый, и менее существенный, заключается в пустой трате сетевых номеров.
Более серьезный недостаток состоит в том, что если ваша организация имеет несколько сетевых номеров, то машины вне ее должны поддерживать записи о маршрутах доступа к каждой из этих IP-сетей. Таким образом, структура IP-сети организации становится видимой для всего мира. При каких-либо изменениях в IP-сети информация о них должна быть учтена в каждой из машин, поддерживающих маршруты доступа к данной IP-сети. Подсети позволяют избежать этих недостатков. Ваша организация должна получить один сетевой номер, например, номер класса B. Стандарты TCP/IP определяют структуру IP-адресов. Для IP-адресов класса B первые два байта являются номером сети. Оставшаяся часть IP-адреса может использоваться как угодно. Например, вы можете решить, что третий байт будет определять номер подсети, а четверый байт - номер узла в ней. Вы должны описать конфигурацию подсетей в файлах, определяющих маршрутизацию IP-пакетов. Это описание является локальным для вашей организации и не видно вне ее. Все машины вне вашей организации видят одну большую IP-сеть. Следовательно, они должны поддерживать только маршруты доступа к шлюзам, соединяющим вашу IP-сеть с остальным миром. Изменения, происходящие в IP-сети организации, не видны вне ее. Вы легко можете добавитьновую подсеть, новый шлюз и т.п.
После того, как решено использовать подсети или множество IP-сетей,вы должны решить, как назначать им номера. Обычно это довольно просто. Каждой физической сети, например, Ethernet или Token Ring, назначается отдельный номер подсети или номер сети. В некоторых случаях имеет смысл назначать одной физической сети несколько подсетевых номеров. Например, предположим, что имеется сеть Ethernet, охватывающая три здания. Ясно,что при увеличении числа машин, подключенных к этой сети, придется ее разделить на несколько отдельных сетей Ethernet. Для того, чтобы избежать необходимости менять IP-адреса, когда это произойдет, можно заранее выделить для этой сети три подсетевых номера - по одному на здание. (Это полезно и в том случае, когда не планируется физическое деление сети. Просто такая адресация позволяет сразу определить, где находится та или иная машина).
Вы также должны выбрать "маску подсети". Она используется сетевым программным обеспечением для выделения номера подсети из IP-адресов. Биты IP-адреса, определяющие номер IP-сети, в маске подсети должны бытьравны 1, а биты, определяющие номер узла, в маске подсети должны бытьравны 0. Как уже отмечалось, стандарты TCP/IP определяют количество байтов, задающих номер сети. Часто в IP-адресах класса B третий байт используется для задания номера подсети. Это позволяет иметь 256 подсе-тей, в каждой из которых может быть до 254 узлов. Маска подсети в такой системе равна 255.255.255.0. Но, если в вашей сети должно быть больше подсетей, а в каждой подсети не будет при этом более 60 узлов, то можно использовать маску 255.255.255.192. Это позволяет иметь 1024 подсети и до 62 узлов в каждой. (Напомним, что номера узлов 0 и "все единицы" используются особым образом). Обычно маска подсети указывается в файле стартовой конфигурации сетевого программного обеспечения. Протоколы TCP/IP позволяют также запрашивать эту информацию по сети.
Можно определить маршрут по умолчанию, который используется в тех случаях, когда IP-адрес места назначения не встречается в таблице маршрутов явно. Обычно маршрут по умолчанию указывает IP-адрес шлюза, который имеет достаточно информации для маршрутизации IP-пакетов со всеми возможными адресами назначения. Если ваша IP-сеть имеет всего один шлюз, тогда все, что нужно сделать, - это установить единственную запись в таблице маршрутов, указав этот шлюз как маршрут по умолчанию. После этого можно не заботиться о формировании маршрутов в других узлах (конечно, сам шлюз требует больше внимания).
Предположим, что нужно посылать IP-пакеты по IP-адресу 128.6.7.23. Первый IP-пакет пойдет на шлюз по умолчанию, так как это единственный подходящий маршрут, описанный в таблице. Однако шлюз128.6.4.27 знает, что существует лучший маршрут, проходящий через шлюз128.6.4.30. (Как он узнает об этом, мы сейчас не рассматриваем. Существует довольно простой метод определения лучшего маршрута.) В этом случае шлюз 128.6.4.27 возвращает сообщение перенаправления, где указывает, что IP-пакеты для узла 128.6.7.23 должны посылаться через шлюз 128.6.4.30. Модуль IP на машине-отправителе должен добавить соответствующую запись в таблицу маршрутов. Все последующие IP-пакеты для узла 128.6.7.23 будут посланы прямо через указанный шлюз.
Несколько более специальная проблема связана с бездисковыми рабочими станциями. По своей природе бездисковые машины сильно зависят от сети и от файл-серверов, с которых они осуществляют загрузку программ, и где располагается их область своппинга. Исполнение программ, следящих за широковещательными передачами в сети, на бездисковых машинах связано с большими трудностями. Протоколы маршрутизации построены в основном на широковещательных передачах. Например, все сетевые шлюзы могут широковещательно передавать содержание своих таблиц маршрутов через каждые 30 секунд. Программы, которые следят за такими передачами, должны быть загружены на бездисковые станции через сеть. На достаточно занятой машине программы, которые не используются в течение нескольких секунд, обычно отправляются в область своппинга. Поэтому программы, следящие за маршрутизацией, большую часть времени находятся в своппинге. Когда они вновь активизируются, должна производиться подкачка из своппинга. Как только посылается широковещательное сообщение, все машины активизируют программы, следящие за маршрутизацией. Это приводит к тому, что многие бездисковые станции будут выполнять подкачку из своппинга в одно и тоже время. Поэтому в сети возникнет временная перегрузка. Таким образом,исполнение программ, прослушивающих широковещательные передачи, на бездисковых рабочих станциях очень нежелательно.
2.1.6. Протокол UDP
Взаимодействие между прикладными процессами и модулем UDP осуществляется через UDP-порты. Порты нумеруются, начиная с нуля. Прикладной процесс, предоставляющий некоторые услуги другим прикладным процессам (сервер), ожидает поступления сообщений в порт, специально выделенный для этих услуг. Сообщения должны содержать запросы на предоставление услуг. Они отправляются процессами-клиентами. Например, сервер SNMP всегда ожидает поступлений сообщений в порт 161. Если клиент SNMP желает получить услугу, он посылает запрос в UDP-порт 161 на машину, где работает сервер. В каждом узле может быть только один сервер SNMP, так как существует только один UDP-порт 161. Данный номер порта является общеизвестным, то есть фиксированным номером, официально выделенным для услуг SNMP. Общеизвестные номера определяются стандартами Internet. Данные, отправляемые прикладным процессом через модуль UDP, достигают места назначения как единое целое. Например, если процесс-отправитель производит 5 записей в UDP-порт, то процесс-получатель должен будет сделать 5 чтений. Размер каждого записанного сообщения будет совпадать с размером каждого прочитанного. Протокол UDP сохраняет границы сообщений, определяемые прикладным процессом. Он никогда не объединяет несколько сообщений в одно и не делит одно сообщение на части.
Когда модуль UDP получает датаграмму от модуля IP, он проверяет контрольную сумму, содержащуюся в ее заголовке. Если контрольная сумма равна нулю, то это означает, что отправитель датаграммы ее не подсчитывал, и, следовательно, ее нужно игнорировать. Если два модуля UDP взаимодействуют только через одну сеть Ethernet, то от контрольного суммирования можно отказаться, так как средства Ethernet обеспечивают достаточную степень надежности обнаружения ошибок передачи. Это снижает накладные расходы, связанные с работой UDP. Однако рекомендуется всегда выполнять контрольное суммирование, так как возможно в какой-то момент изменения в таблице маршрутов приведут к тому, что датаграммы будут посылаться через менее надежную среду. Если контрольная сумма правильная (или равна нулю), то проверяется порт назначения, указанный в заголовке датаграммы. Если к этому порту подключен прикладной процесс, то прикладное сообщение, содержащееся в датаграмме, становится в очередь для прочтения. В остальных случаях датаграмма отбрасывается. Если датаграммы поступают быстрее, чем их успевает обрабатывать прикладной процесс, то при переполнении очереди сообщений поступающие датаграммы отбрасываются модулем UDP.
2.1.7. Протокол TCP
Протокол TCP предоставляет транспортные услуги, отличающиеся от услуг UDP. Вместо ненадежной доставки датаграмм без установления соединений, он обеспечивает гарантированную доставку с установлением соединений в виде байтовых потоков. Протокол TCP используется в тех случаях, когда требуется надежная доставка сообщений. Он освобождает прикладные процессы от необходимости использовать таймауты и повторные передачи для обеспечения надежности. Наиболее типичными прикладными процессами, использующими TCP, являются FTP (File Transfer Protocol - протокол передачи файлов) и TELNET. Кроме того, TCP используют система X-Window, rcp (remote copy - удаленное копи-рование) и другие "r-команды". Большие возможности TCP даются не бесплатно. Реализация TCP требует большой производительности процессора и большой пропускной способности сети.
Внутренняя структура модуля TCP гораздо сложнее структуры модуля UDP. Прикладные процессы взаимодействуют с модулем TCP также через порты. Для отдельных приложений выделяются общеизвестные номера портов. Например,сервер TELNET использует порт номер 23. Клиент TELNET может получатьуслуги от сервера, если установит соединение с TCP-портом 23 на его машине. Когда прикладной процесс начинает использовать TCP, то модуль TCP на машине клиента и модуль TCP на машине сервера начинают общаться. Эти два оконечных модуля TCP поддерживают информацию о состоянии соединения, называемого виртуальным каналом. Этот виртуальный канал потребляет ресурсы обоих оконечных модулей TCP. Канал является дуплексным; данные могут одновременно передаваться в обоих направлениях. Один прикладной процесс пишет данные в TCP-порт, они проходят по сети, и другой прикладной процесс читает их из своего TCP-порта.
Протокол TCP разбивает поток байт на пакеты вне зависимости от его содержания и не сохраняет границ между записями. Например, если один прикладной процесс делает 5 записей в TCP-порт, то прикладной процесс на другом конце виртуального канала может выполнить 10 чтений для того, чтобы получить все данные. Но этот же процесс может получить все данные сразу, сделав только одну операцию чтения. Не существует зависимости между числом и размером записываемых сообщений с одной стороны и числом и размером считываемых сообщений с другой стороны. Протокол TCP требует, чтобы все отправленные данные были подтверждены принявшей их стороной. Он использует таймауты и повторные передачи для обеспечения надежной доставки.
Отправителю разрешается передавать некоторое количество данных, не дожидаясь подтверждения приема ранее отправленных данных. Таким образом, между отправленными и подтвержденными данными существует окно уже отправленных, но еще не подтвержденных данных. Количество байт, которые можно передавать без подтверждения, называется размером окна. Как правило, размер окна устанавливается в стартовых файлах сетевого программного обеспечения.
Так как TCP-канал является дуплексным, то подтверждения для данных, идущих в одном направлении, могут передаваться вместе с данными, идущими в противоположном направлении. Приемники на обеих сторонах виртуального канала выполняют управление потоком передаваемых данных для того, чтобы не допускать переполнения буферов.
Почему существуют два транспортных протокола TCP и UDP, а не один из них? Дело в том, что они предоставляют разные услуги прикладным процессам. Большинство прикладных программ пользуются только одним из них. Вы, как программист, выбираете тот протокол, который наилучшим образом соответствует вашим потребностям. Если вам нужна надежная доставка, то лучшим может быть TCP. Если вам нужна доставка датаграмм, то лучше может быть UDP. Если вам нужна эффективная доставка по длинному и ненадежному каналу передачи данных, то лучше может подойти протокол TCP. Если нужна эффективность на быстрых сетях с короткими соединениями, то лучшим может быть протокол UDP.
Если ваши потребности не попадают ни в одну из этих категорий, то выбор транспортного протокола не ясен. Однако прикладные программы могут устранять недостатки выбранного протокола. Например,если вы выбрали UDP, а вам необходима надежность, то прикладная программа должна обеспечить надежность сама. Если вы выбрали TCP, а вам нужно передавать записи, то прикладная программа должна вставлять маркеры в поток байтов так, чтобы можно было различить записи.
Какие же прикладные программы доступны в сетях с TCP/IP? Общее их количество велико и продолжает постоянно увеличиваться. Некоторые приложения существуют с самого начала развития internet. Например, TELNET и FTP. Другие появились недавно: X-Window, SNMP. Протоколы прикладного уровня ориентированы на конкретные прикладные задачи. Они определяют как процедуры по организации взаимодействия определенного типа между прикладными процессами, так и форму представления информации при таком взаимодействии. Коротко опишем некоторые из прикладных протоколов.
Протокол TELNET позволяет обслуживающей машине рассматривать удаленные терминалы как стандартные "сетевые виртуальные терминалы" строчного типа, работающие в коде ASCII, а также обеспечивает возможность согласования более сложных функций (например, локальный или удаленный эхо-контроль, страничный режим, высота и ширина экрана и т.д.). TELNETработает на базе протокола TCP. На прикладном уровне над TELNET находится либо программа поддержки реального терминала (на стороне пользователя), либо прикладной процесс в обсуживающей машине, к которому осуществляется доступ с терминала. Работа с TELNET походит на набор телефонного номера. Пользователь набирает на клавиатуре что-то вроде «telnet А» и получает на экране приглашение на вход в машину А. Протокол TELNET существует уже давно. Он хорошо опробован и широко распространен. Создано множество реализаций для самых разных операционных систем. Вполне допустимо, чтобы процесс-клиент работал, скажем, под управлением одной операционной системой, а процесс-сервер - под управлением другой.
Протокол FTP (File Transfer Protocol – протокол передачи файлов) распространен так же широко и пользуется транспортными услугами TCP. Существует множество реализаций для различных операционных систем, которые хорошо взаимодействуют между собой. Пользователь FTP может вызывать несколько команд, которые позволяют ему посмотреть каталог удаленной машины, перейти из одного каталога в другой, а также скопировать один или несколько файлов.
Протокол SMTP (Simple Mail Transfer Protocol - простой протокол передачи почты) поддерживает передачу сообщений (электронной почты) между произвольными узлами сети internet. Имея механизмы промежуточного хранения почты и механизмы повышения надежности доставки, протокол SMTP допускает использование различных транспотных служб. Он может работать даже в сетях, не использующих протоколы семейства TCP/IP. Протокол SMTP обеспечивает как группирование сообщений в адрес одного получателя, так и размножение нескольких копий сообщения для передачи в разные адреса. Над модулем SMTP располагается почтовая служба конкретных вычислительных систем.
Сетевая файловая система NFS (Network File System) впервые была разработана компанией Sun Microsystems Inc. NFS использует транспортныеуслуги UDP и позволяет монтировать в единое целое файловые системы нескольких машин с ОС UNIX. Бездисковые рабочие станции получают доступ к дискам файл-сервера так, как-будто это их локальные диски. NFS значительно увеличивает нагрузку на сеть. Если в сети используются медленные линии связи, то от NFS мало толку. Однако, если пропускная способность сети позволяет NFS нормально работать, то пользователи получают большие преимущества. Поскольку сервер и клиент NFS реализуются в ядре ОС, все обычные несетевые программы получают возможность работать с удаленными файлами, расположенными на подмонтированных NFS-дисках, точно так же, как с локальными файлами.
Протокол SNMP (Simple Network Management Protocol - простой протокол управления сетью) работает на базе UDP и предназначен для использования сетевыми управляющими станциями. Он позволяет управляющим станциям собирать информацию о положении дел в сети internet. Протокол определяет формат данных, их обработка и интерпретация остаются на усмотрение управляющих станций или менеджера сети.
Система X-Window использует протокол X-Window, который работает на базе TCP, для многооконного отображения графики и текста на растровых дисплеях рабочих станций. X-Window - это гораздо больше, чем просто утилита для рисования окон - это целая философия человеко-машинного взаимодействия.
Протокол HTTP (Hyper text transfer protocol – протокол передачи гипертекста) применяется для обмена информацией между серверами WWW (World Wide Web – всемирная паутина) и программами просмотра гипертекстовых страниц – браузерами WWW. Допускает передачу широкого спектра разнообразной информации – текстовой, графической, аудио и видео.
POP3 (Post Office Protocol – протокол почтового узла, 3 версия), позволяет программам-клиентам электронной почты принимать и передавать сообщения с / на почтовые серверы. Обладает достаточно гибкими возможностями по управлению содержимым почтовых ящиков, расположенных на почтовом узле. В типичных программах-клиентах в основном применяется для приема входящих сообщений.
NNTP (Network News Transfer Protocol – протокол передачи сетевых новостей) позволяет общаться серверам новостей и клиентским программам – распространять, запрашивать, извлекать и передавать сообщения в группы новостей. Новые сообщения хранятся в централизованной базе данных, которая позволяет пользователю выбирать интересующие его сообщения. Также обеспечивается индексирование, организация ссылок и удаление устаревших сообщений.
2.2. Секреты Google Dance
В этом разделе мы опишем принципы, на которых работает поисковый робот и база данных Google. Хотя цикл ежемесячного обновления базы Google довольно-таки хорошо описан в соответствующей документации, за последний год этот цикл (его ласково называют "танец Google") стал все более и более отходить от оригинальной модели и в настоящее время кажется большинству веб-мастеров и обладателей сайтов, которые с нетерпением ждут всех ежемесячных обновлений, неким сумрачным силуэтом.
Начинается каждый "танец" с объемного, глубокого обследования сети. Назовем его Шагом А. На данном этапе поисковые агенты Google прочесывают всю доступную сеть - более 8.2 миллиарда страниц, по последним подсчетам. Google использует более 132,000 недорогих персоналок (собственно говоря, обыкновенных настольных компьютеров), находящихся в различных информационных центрах по всему земному шару. Затем запускается Googlebot (или DeepBot), дабы проверить все сайты, существующие в текущей базе данных, а также, чтобы найти новые, недавно появившиеся сайты. По завершении Шага А, когда Google успешно подцепил все эти сайты для последующего обновления базы, следует еще одно обновление, примерно две недели спустя.
Тем временем Google обновит всю свою базу данных, отображая вновь полученные результаты на www2.google.com и www3.google.com. Во время этого обновления, результаты часто переключаются с одной базы в другую. Как уже указывалось, Google задействует более 132,000 серверов, вследствие чего большинство людей в различных точках земного шара будут получать разные результаты по одним и тем же запросам, до тех пор, пока бóльшая часть обновлений не будет внесена в базу. "Танец Google" будет продолжаться еще несколько дней, но чаще всего не более недели (если, разумеется, не возникнет особых проблем и не появится надобность смены алгоритма, как случилось, например, при обновлении базы данных Google в апреле 2003 г.).
Тем временем, в процессе и непосредственно после каждого обновления базы, Google предпринимает еще одно тщательное обследование сети, назовем его Шагом Б, во время которого проверяются все сайты, существующие в текущей базе данных, а также новые, недавно появившиеся в сети, обнаруженные поисковыми агентами. После этого обследования, проводимого Googlebot'ом, цикл возвращается к началу и начинается заново со следующего месяца.
Чтобы как можно быстрее разместить тот или иной сайт в базе данных Google, а также, чтобы обновления сайта в этой базе отображались, хороший и опытный веб-разработчик должен все заранее спланировать, чтобы иметь шанс "подловить" Googlebot в определенный момент ежемесячного цикла. Большинство искушенных экспертов SEO знают, что наряду с первоначальным прочесыванием сети роботами, которое имеет место в начале месяца, существует также тщательное обследование как в процессе обновления базы, так и непосредственно вслед за этим.
Если веб-разработчик хочет поместить свой новый сайт в базу данных Google, спрашивается, насколько эти обследования могут обеспечить попадание сайта в базу? Судя по многомесячным наблюдениям за обновлениями, это происходит далеко не всегда! Собственно говоря, если поисковый робот попадает на сайт в начале месяца, не исключено, что в текущем месяце в обновленную базу данных этот сайт не попадет. Если же сайт попадает под вторичное обследование, которое следует непосредственно за обновлением базы, есть возможность, хотя и не стопроцентная, что он будет посещен еще раз в начале следующего цикла, и, соответственно, попадет в число обновлений в следующем месяце.
В прочих случаях робот Google просто посетит новый сайт, отметив индекс и файл Robots.txt. Такое развитие событий зачастую указывает на то, что в процессе следующего тщательного обследования Googlebot вновь появится здесь, и, таким образом, после второго визита сайт будет включен в обновленную базу данных. Из вышесказанного вроде бы следует, что нужно два визита Googlebot, чтобы сайт был включен в базу данных Google. В большинстве случаев так оно и есть, но всегда существуют исключения.
Есть несколько вещей, которые может сделать опытный вебмастер для возможно скорейшего включения своего сайта в базу данных. Если в первый раз Googlebot попадает на сайт в процессе или непосредственно после обновления базы, то более чем вероятно, что этот сайт будет фигурировать в "танце Google" в следующем месяце. Если же сайт обследуется не в этот период, а только в начале следующего цикла, то веб-разработчику или владельцу сайта придется ждать включения в базу данных значительно дольше.
В свете всего вышеперечисленного, что же может сделать веб-мастер, чтобы стать объектом внимания Googlebot'а именно в этот критический момент? Ну, разумеется, можно надеяться и молиться, что именно так все оно и случится, - само собой, научным такой подход не назовешь, - или же можно провести необходимую подготовку и все спланировать заранее. Если у данного вебмастера есть другие сайты, уже включенные в базу данных Google, то он может следить за датами обследования сети и обновления базы, и, соответственно, тщательно планировать апдейты. Если же у вас нет сайта, находящегося в базе данных Google, то за обновлениями можно следить на www.google.com.
На практике, стопроцентной гарантии, что поисковый робот появится на том или ином сайте или на какой-либо его части, не существует. Тем не менее, вебмастер может сделать несколько упредительных шагов, дабы "приманить" Googlebot'а и "подкинуть" поисковому роботу данный конкретный сайт. Первое, что можно сделать - это обменяться ссылками с другими сайтами, притом обладающими достаточно высоким рейтингом. Попросту говоря, чем выше рейтинг сайта, тем тщательнее Google будет его обследовать и отображать обновления, а, следовательно, тем быстрее ваш адрес (URL) будет замечен. Кстати, о релевантности: если ваш сайт посвящен розничной продаже мебели, вам стоит обмениваться ссылками с подобными же компаниями, например, с производителями мебели или с оптовиками. В этом случае Google присвоит вам более высокий рейтинг, чем, если бы ваша ссылка располагалась на сайте с отвлеченной тематикой.
Во-вторых, вы сами можете указать Google на ваш сайт, воспользовавшись опцией добавления адреса в базу. Хотя стопроцентного попадания в базу такой путь не гарантирует, сделать это все же стоит. В-третьих, вебмастер может установить панель инструментов Google (он же Google ToolBar), и заходить на свой сайт через нее. С лета 2002 года немало было сказано о прямой связи между заходом на сайт через панель инструментов Google и добавлением этого сайта в базу данных.
Обеспечив себе место в листинге каталога Yahoo! за 299 долларов в год, сайтовладелец также имеет хороший шанс попасть в базу данных Google, при том, что Yahoo! обновляет свои каталоги быстро, обычно в течение недели. Также путем к заветной базе может стать листинг DMOZ (Open Directory Project), правда, подождать придется чуть дольше. На DMOZ, однако же, безоговорочно полагаться нельзя, кроме того, с недавнего времени у них более чем достаточно проблем с серверами.
Вся техническая информация, доступная веб-разработчикам и SEO-экспертам, которая имеет отношение к путям исследования сети и пополнения базы данных Google, вне сомнения, имеет большое значение для планирования и реализации раскрутки того или иного проекта. Кроме помощи во всем вышеперечисленном, она может быть полезна при составлении расписаний апдейтов, поскольку новые разработки и обновления должны выкладываться в сеть в определенное время, для скорейшего их попадания в базу данных поисковой системы. Поскольку Google обладает высокой популярностью и следовательно может быть источником целевого траффика, чрезвычайно полезно иметь хотя бы примерное представление о том, как информация добавляется в эту систему.
2.3. Поиск по скрытой части интернета
Информация, доступная нам через "поисковики", - лишь малая часть того, что на самом деле находится в сети. Чтобы открыть для себя весь необъятный мир вэба, нужно знать, как искать.
Чаще всего, когда нам необходима какая-либо информация в интернете, мы прибегаем к помощи популярных информационно-поисковых систем (ИПС), таких как Google, Yahoo!, AltaVista или "Яндекс". Однако, как оказалось, кроме видимой для "поисковиков" части вэб-пространства существует огромное количество страниц, которые ими не охватываются.
Подобные ресурсы имеют собственное название - "скрытый" вэб (deep web), которое обозначает источники, недоступные для обычных поисковых систем. Однако к таким вэб-страничкам все же можно добраться и найти на них много полезной информации.
В 2000 году американская компания BrightPlanet с помощью программы LexiBot осуществила сканирование в сети некоторых динамических вэб-страниц, формируемых из баз данных.
Результаты были ошеломляющими - неопознанных ресурсов в интернете оказалось в сотни раз больше, чем доступных сегодня традиционным информационно-поисковым системам. То есть 10 миллиардов вэб-страниц - это лишь видимая крупица Глобальной паутины. В результате исследований также выявилось немало интересных особенностей "скрытых" вэб-страниц. Например, оказалось, что они в среднем на 27 % компактней страниц из видимой части интернета.
Невидимыми ресурсы для ИПС оказались по причине алгоритмов работы популярных роботов-индексаторов. Такие программы, как правило, посещают вэб-страницы по известным заранее адресам, анализируют их содержание и выделяют гиперссылки, идущие от них. Обычно, обработав текущую страницу, выделив ключевые слова и некоторые поля, робот переходит по адресам, найденным на ней. Затем система опять сканирует последующие страницы и выделяет новые адреса. Однако как только робот определяет, что он обращается к динамической странице, его работа приостанавливается. Ведь для получения осмысленного ответа из баз данных требуется соответствующий запрос, а большинству из роботов чужды элементы интеллекта (даже искусственного).
То есть "скрытый" вэб формируется в первую очередь из содержимого онлайновых баз данных. Сюда следует добавить и быстро обновляемые ресурсы, так называемые динамические. К ним относятся новости, конференции, онлайновые журналы и др. Конечно, есть и "острова" Глобальной паутины, на которые не ведут никакие гиперссылки и от которых гиперссылки не исходят. Защищенные паролями вэб-сайты также попадают в категорию "скрытого" интернета.
О материалах этих сайтов большинство пользователей никогда не узнают с помощью стандартных поисковых систем. Однако относительное количество таких ресурсов невелико. По мнению ученых, среди крупнейших сайтов "скрытого" вэба платными являются только 10 % ресурсов.
В свое время исследователи BrightPlanet определили более десятка разновидностей "скрытых" вэб-ресурсов, относящихся к классу онлайновых баз данных. В списке оказались как традиционные базы данных (патенты, медицина и финансы), так и публичные ресурсы - объявления о поиске работы, чаты, библиотеки, справочники. Ученые также причислили к "скрытым" ресурсам и специализированные поисковые системы, которые обслуживают определенные отрасли или рынки. При этом базы данных таких ИПС не включаются в каталоги глобальных поисковых служб.
К "невидимой" части сети также относятся многочисленные системы интерактивного взаимодействия с пользователями - помощи, консультации, обучения, требующие участия людей для формирования динамических ответов от серверов. В ней также находится и закрытая (полностью или частично) информация, доступная пользователям сети только с определенных адресов, групп адресов, а иногда городов и стран.
Например, для нашего пользователя наверняка "скрытой" можно признать большую часть гигантского китайского сегмента интернета.
Так, малоизвестный в Европе и Америке китайский поисковый портал Baidu (www.baidu.com) в 2004 году опередил Google по объему трафика, став четвертым в мире вэб-ресурсом по этому показателю. Другая китайская поисковая система 3721.com (https://www.3721.com/) заняла седьмое место в списке самых посещаемых ИПС.
В ноябре 1999 года Андрей Бродер (Andrei Broder) совместно с другими учеными из компаний AltaVista, IBM и Compaq математически описали карту ресурсов и гиперсвязей интернета. Исследователи опровергли расхожее мнение, будто интернет - это единое густое пространство. Проследив с помощью поискового механизма AltaVista свыше 200 млн вэб-страниц и несколько миллиардов ссылок, ученые построили ориентированный граф с топологией "галстук-бабочка" (Bow Tie), которая, по их мнению, соответствует структуре вэб-пространства. У ученых получилась модель связности, охватывающая более 90 % исследованных вэб-страниц в сети:
· центральное ядро (SCC) составляют ресурсы, взаимосвязанные так тесно, что,








