 2014-02-24
2014-02-24 651
651Предположим, что мы построили линейную модель и оценили её параметры МНК. Если модель адекватна, то мы имеем возможность определять прогнозные значения зависимой переменной, исходя из построенной модели. При этом различают два типа прогнозов: точечный и интервальный. Точечный прогноз дает возможность получить значение зависимой переменной, например, Yn+1 для соответствующего значения исходя из построенной модели:
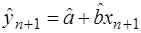 . (39)
. (39)
При этом, исходя из обобщенной модели, действительное значение Y для прогнозного периода будет
yn+1 = a + bxn+1 + en+1, (40)
где en+1 - значение случайной величины, не наблюдаемой в (n+1) периоде. Нетрудно убедиться, что для генеральной совокупности мы не можем определить действительное значение Y, но у нас есть возможность оценить его с помощью прогноза.
Таким образом, прогнозное значение 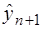 является оценкой действительного значения переменной yn+1 и мы можем определять любые прогнозные значения. Пусть такое прогнозное значение будет точечным. Исходя из точечного прогноза мы можем построить интервалы доверия для действительного значения зависимой переменной, другими словами, построить интервал, в который с заданной вероятностью попадает действительное значение зависимой переменной. Такой интервал доверия при заданном уровне значимости a для yn+1 определяется по формуле
является оценкой действительного значения переменной yn+1 и мы можем определять любые прогнозные значения. Пусть такое прогнозное значение будет точечным. Исходя из точечного прогноза мы можем построить интервалы доверия для действительного значения зависимой переменной, другими словами, построить интервал, в который с заданной вероятностью попадает действительное значение зависимой переменной. Такой интервал доверия при заданном уровне значимости a для yn+1 определяется по формуле
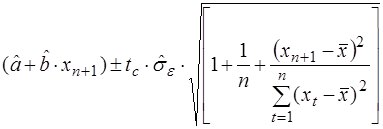 . (41)
. (41)
На практике больший интерес представляет построение интервалов доверия для математического ожидания yn+1:
E (yn+1) = a + bxn+1. (42)
При заданном уровне значимости a такой прогноз определяют следующим образом:
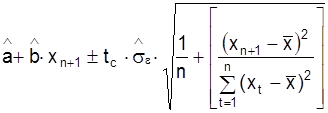 . (42)
. (42)
П р и м е р. Доходы семьи. В этом примере используются данные обследования 3781 семей Российской Федерации, проведенного осенью 1999 года совместно Госкомстатом РФ, Институтом социологии РАН, Институтом питания РАМН и Университетом Северной Каролины (США). Пусть Inc обозначает реальный доход семьи, Expend - её реальные расходы. Для того, чтобы исследовать зависимость расходов от доходов, оценим коэффициент регрессии и неизвестные параметры.
Для всех типов семей (количество наблюдений 3594):
Expend = 4663,3 + 0,686 Inc, R2 = 0,21, S = 11307.
(233,6) (0,0223)
В скобках приведены стандартные ошибки коэффициентов регрессии. Соответствующие t-статистики равны 19,96 и 30,81, т.е. коэффициенты статистически достоверно отличаются от нуля. Однако значение коэффициента детерминации R2 невелико. Это объясняется, конечно, разнородностью семей, как по составу, так и по другим факторам, таким, как место проживания, структура расходов, состав семьи и т. д. Таким образом, для более однородной выборки семей мы вправе ожидать увеличения коэффициента детерминации.
Для семей, состоящих из одного человека (количество наблюдений 509),
Expend = 3229,2 + 0,355 Inc, R2 =0,39, S = 4567.
(182,0) (0,0162)
Как и в предыдущем случае, коэффициенты являются значимыми; t-статистики равны соответственно 17,74 и 20,70. Как мы и ожидали, качество подгонки улучшилось – коэффициент R2 возрос с 0,21 до 0,39, а оценка стандартного отклонения остатков S уменьшилась с 11307 до 4567. Так как в семьях, состоящих из одного человека, нет расходов на содержание неработающих членов семьи (детей, престарелых), то на потребление тратится меньшая часть прироста дохода. Склонность к потреблению определяется как ¶Expend/¶Inc, для семьи из одного человека она составляет 0,355, в то время как в среднем по всей выборке – 0,686.
Обозначим через NF количество членов в семье. Оценим регрессию среднего расхода на членов семьи на средний доход члена семьи (количество наблюдений 3594):
Expend / NF = 2387,2 + 0,447 Inc/NF, R2 = 0,24, S = 4202.
(76,8) (0,0133)
Значение R2 увеличилось по сравнению с первой регрессией. Переход к удельным данным приводит к уменьшению дисперсии данных.








