2014-02-09
2014-02-09 516
516virtual HRESULT STDMETHODCALLTYPE GetIDsOfNames(
/* [m] */ REFIID riid,
/* [size_is][in] */ LPOLESTR __RPC_FAR *rgszNames,
/* [in] */ UINT cNames,
/* [in] */ LCID Icid,
/* [size_is][out] */ DISPID __RPC_FAR *rgDispld) = 0;
virtual /* [local] */ HRESULT STDMETHODCALLTYPE lnvoke(
/*[in] */ DISPID displdMember,
/*f[in] REFIID riid,
/* [in] */ LCID Icid,
/* [in] */ WORD wFlags,
/* [out][m] */ DISPPARAMS __RPC_FAR *pDispParams,
/* [out] */ VARIANT __RPC_FAR *pVarResuIt,
/* [out] */ EXCEPINFO __RPC_FAR *pExceplnfo,. „
/* [°ut3 */ UINT __RPC.FAR *puArgErr) = 0;
};
Хотя интерфейс IDispatch выглядит сложнее, чем IUnknown, он объявляет всего несколько до полнительных функций: GetType InfoCount(), GetType Info(), Get IDsOfNames() и Invoke(). Поскольку он наследуется от lUnknown, он имеет и унаследованные функции Querylnterface(), AddRef,() и Release(). Они являются чисто виртуальными, поэтому любой класс СОМ, наследующий от IDispatch, должен включать свою реализацию этих функций. Самой важной из всех определенных выше функций является I nvoke(), используемая для вызова функций сервера автоматизации и доступа к его свойствам.
10.8. Элементы управления ActiveX
Элементы управления ActiveX являются миниатюрными серверами автоматизации ActiveX, которые загружаются и выполняются в процессе. Последнее указывает на то, что они работают исключительно быстро. Раньше их принято было называть элементами управления OLE. Они были разработаны для замены элементов управления VBX, 16-битовых элементов управления, написанных для использования в Visual Basic и Visual C++. (Имеется достаточное количество существенных технических причин, по которым технология VBX не может быть распространена на 32-битовые приложения.) Поскольку элементы управления OLE традиционно хранились в файлах с расширением. OCX, многие ссылались на элементы управления OLE, как на элементы управления OCX или просто OCX. Хотя технология OLE со временем была замещена ActiveX, создаваемые Visual C++ 6.0 элементы управления ActiveX по-прежнему хранятся в файлах, имеющих расширение. OCX.
Первоначально цель создания элементов управления VBX состояла в предоставлении программистам возможности включать в пользовательский интерфейс нестандартные элементы управления. Они позволяли без особых трудностей разработать элемент управления, который имел вид индикатора количества топлива или регулятора громкости. Однако почти сразу же программисты, работающие с VBX, от простых элементов управления перешли к модулям, включающим значительное количество вычислений и обработки. Точно так же многие элементы управления ActiveX являются на самом деле чем-то существенно большим, чем просто элементами управления. Они являются компонентами, которые могут быть использованы для быстрого построения мощных приложений.
Если вы уже имеете опыт создания OCX в одной из более ранних версий Visual C++, у вас могло сложиться впечатление, что подобная работа является непростой. Однако пакет Control Developer Kit, интегрированный в новую версию Visual C++, прини мает на себя большую часть работы по обеспечению требований ActiveX и дает вам возможность сконцентрироваться на вычислениях, отображении на экран или любых других действиях, для выполнения которых и предназначен данный элемент Мастер ActiveX Control значительно упрощает работу, позволяя начать с уже имеющейся пустой заготовки.
Поскольку элементы управления являются небольшими серверами автоматизации ActiveX, они должны использоваться контроллерами автоматизации ActiveX. Чтобы не путать контроллер и элемент управления (что безотносительно к ActiveX есть одно и то же), вместо термина контроллер автоматизации будем пользоваться более привычным термином приложение-контейнер или просто контейнер. И Visual C++, и Visual Basic являются контейнерами, ими являются также многие программы, входящие в состав Office, и другие программы Microsoft.
В дополнение к методам и свойствам элементы управления ActiveX имеют дело с событиями. Говоря конкретнее, элемент управления посылает контейнеру сообщение о событии и делает это в том случае, когда происходит что-то, о чем следует уведомить контейнер. Например, когда пользователь делает щелчок в любом месте изображения, элемент обрабатывает щелчок (скажем, изменяет облик этого участка или выполняет какие-либо вычисления). Но ему необходимо, как правило, еще и уведомить о щелчке приложение-контейнер, чтобы оно выполнило, к примеру, открытие файла или какое-либо иное действие.
В этой главе вам был предоставлен краткий обзор концепций технологии ActiveX и используемой в ней терминологии, а также перечислены разнообразные возможности приложений, использующих элементы технологии ActiveX. Остальные главы этой части книги посвящены созданию приложений с помощью MFC и Мастеров Visual C++, поддерживающих технологию ActiveX.
11.УКАЗАТЕЛИ
11.1Указательные типы
Переменная — не более чем удобная нотация адресования ячейки памяти. Имя переменной является статическим и определено на этапе компиляции: разные имена относятся к разным ячейкам, и не существует способов «вычисления имени», кроме как в определенных видах контекстов, таких как индексирование массива. Значение указательного (ссылочного) типа (pointer type) — это адрес; указательная переменная (указатель) содержит адрес другой переменной или константы. Объект, на который указывают, называется указуемым или обозначаемым объектом (designated object). Указатели применяются скорее для вычислений над адресами ячеек, чем над их содержимым.
Следующий пример:
int i = 4;
int*ptr=&I;
породит структуру, показанную на рис. 1. Указатель ptr сам является переменной со своим собственным местом в памяти (284), но его содержимое -это адрес (320) другой переменной i.
Синтаксис объявления может ввести в заблуждение, потому что звездочка «*» по смыслу относится к типу int, а не к переменной ptr.

рис.1 Переменная-указатель и указуемая переменная
Объявление следует читать как: «ptr имеет указатель типа на int». Унарная операция «&» возвращает адрес следующего за ней операнда.
К значению переменной i, конечно, можно получить доступ, просто использовав ее имя, например, как i + 1, но к нему также можно получить доступ путем разыменования (dereferencing) указателя с помощью синтаксиса *ptr. Когда вы разыменовываете указатель, вы хотите увидеть не содержимое переменной-указателя ptr, а содержимое ячейки памяти, адрес которой содержится в ptr, то есть указуемый объект.
11.1.1 Типизированные указатели
В приведенном примере адреса записаны как целые числа, но адрес не является целым числом. Форма записи адреса будет зависеть от архитектуры компьютера. Например, компьютер intel 8086 использует два 16-разрядных слова, которые объединяются при формировании 20-разрядного адреса. Разумно предположить, что все указатели представляются единообразно.
Однако в программировании полезнее и надежнее использовать типизированные указатели, которые объявляются, чтобы ссылаться на конкретный тип, такой как тип int в приведенном выше примере. Указуемый объект *ptr должен иметь целый тип, и после разыменования его можно использовать в любом контексте, в котором требуется число целого типа:
int а[10];
а[*ptr] = а[(*ptr) + 5]; /* Раскрытие и индексирование*/
а[i] = 2 * *ptr; /* Раскрытие и умножение */
Важно делать различие между переменной-указателем и указуемым объектом и быть очень осторожными при присваивании или сравнении указателей:
int i1=10;
int i2=20;
int *ptr1 = &i1; /* ptr1 указывает на i1 */
int *ptr2 = &i2; /* ptr2 указывает на i2 */
*ptr1 = *ptr2; /* Обе переменные имеют одно и то же значение */
if(ptr1 = = ptr2)... /* «Ложь», разные указатели */
if (*ptr1 = = *ptr2) /* «Истина», обозначенные объекты равны */
ptr1 = ptr2; /* Оба указывает на i2 */
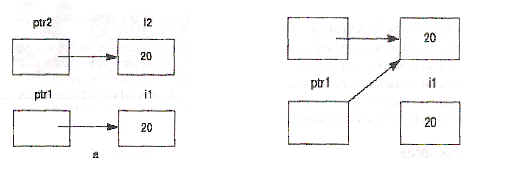
ptr
Рис. 2. Присваивания с указателями.
На рисунке 2а показаны переменные после первого оператора присваивания: благодаря раскрытию указателей происходит присваивание указуемых объектов и i1 получает значение 20. После выполнения второго оператора присваивания (над указателями, а не над указуемыми объектами) переменная i1 больше не является доступной через указатель, что показано на рис. 2б.
Важно понимать различие между указателем-константой и указателем на константный указуемый объект. Создание указателя-константы не защищает указуемый объект от изменения:
int i1, i2;
int * const p1 = &i1; /* Указатель-константа */
const int * p2 = &i1; /* Указатель на константу */
const int * const p3 = &i1; /* Указатель-константа на константу */
p1 =&i2; /* Ошибка, указатель-константа */
*p1=5 /* Правильно, указуемый объект не является константой */
p2 =&i2; /* Правильно, указатель не является константой */
*p2 = 5; /* Ошибка, указуемый объект — константа */
p3 =&i2; /* Ошибка, указатель-константа */
*p3 = 5; /* Ошибка, указуемый объект — константа */
В языке С указатель на void является нетипизированным указателем. Любой указатель может быть неявно преобразован в указатель на void и обратно, хотя смешанное использование присваиваний типизированных указателей обычно будет сопровождаться предупреждающим сообщением. В C++ контроль соответствия типов делается намного тщательнее. Типизированные указатели неявно могут быть преобразованы в указатели на void, но не обратно:
void *void_ptr; /* Нетипизированный указатель */
int *int_ptr; /* Типизированный указатель */
char *char_ptr; /* Типизированный указатель */
void_ptr = int_ptr; /* Правильно */
char_ptr = void_ptr; /* Правильно в С, но ошибка в C++ */
char_ptr = int_ptr; /* Предупреждение в С, ошибка в C++ */
Поскольку в С нет контроля соответствия типов, указателю может быть присвоено произвольное выражение. Нет никакой гарантии, что указуемый объект имеет ожидаемый тип; фактически значение указателя могло бы даже не быть адресом в отведенной программе области памяти. В лучшем случае это приведет к аварийному сбою программы из-за неправильной адресации, и вы получите соответствующее сообщение от операционной системы. В худшем случае это может привести к разрушению данных операционной системы. Ошибки в указателях очень трудно выявлять при отладке, потому что сложно разобраться в абсолютных адресах, которые показывает отладчик. Решение состоит в более строгом контроле соответствия типов для указателей, как это делается в Ada и C++.
11.1.2 Синтаксис
Раскрытие указателей, индексация массивов и выбор полей записей — это средства доступа к данным внутри структур данных. В языке Pascal синтаксис самый ясный: каждая из этих трех операций обозначается отдельным символом, который пишется после переменной. В следующем примере Ptr объявлен как указатель на массив записей с целочисленным полем:
type Rec_Type =
record
Field: Integer;
end;
type Array_Type = array[1..100] of Rec_Type;
type Ptr_Type = Array_Type;
Ptr: Ptr_Type;
Теперь, используя символ () обозначающий раскрытие указателя, мы с каждым добавлением к Ptr совершаем переход на один шаг вглубь декомпозиции структуры данных:
Ptr (*Указатель на массив записей с целочисленным полем *)
Ptr (*Массив записей с целочисленным полем *)
Ptr [78] (*3апись с целочисленным полем *)
Ptr [78].Field (*Целочисленное поле *)
В языке С символ раскрытия ссылки (*) является префиксным оператором,
поэтому приведенный пример записывался бы так:
typedef struct {
int field;
} Rec_Type;
typedef Rec_Type Array_Type[100];
Array_Type *ptr;
ptr /* Указатель на массив записей с целочисленным полем */
*ptr /* Массив записей с целочисленным полем */
(*ptr)[78] /* Запись с целочисленным полем */
(*ptr)[78].field /* Целочисленное поле */
Здесь необходимы круглые скобки, потому что индексация массива имеет более высокий приоритет, чем раскрытие указателя. В сложной структуре данных это может внести путаницу при расшифровке декомпозиции, которая использует разыменование как префикс, а индексацию и выбор поля как постфикс. Наиболее часто используемая последовательность операций, в которой за разыменованием следует выбор поля, имеет специальный, простой синтаксис. Если ptr указывает на запись, то ptr->field — это краткая запись для (*ptr).field.
Синтаксис Ada основан на предположении, что за разыменованием почти всегда следует выбор поля, поэтому отдельная запись для разыменования не нужна. Вы не можете сказать, является R.Field просто выбором поля обычной записи с именем R, или R — это указатель на запись, который раскрывается перед выбором. Такой подход имеет то преимущество, что в структурах данных мы можем перейти от использования самих записей к использованию указателей на них без других изменений программы. В тех случаях, когда необходимо только разыменование, используется довольно неуклюжий синтаксис, как показывает вышеупомянутый пример на языке Ada:
type Rec_Type is
record
Field: Integer;
end record;
type Array_Type is array(1..100) of Rec_Type;
type Ptr_Type is access Array_Type;
Ptr: Ptr_Type;
Ptr -- Указатель на массив записей с целочисленным полем
Ptr.all -- Массив записей с целочисленным полем
Ptr.all[78] -- Запись с целочисленным полем
Ptr.all[78].Field -- Целочисленное поле
В Ada для обозначения указателей используется ключевое слово access, а не символ. Ключевое слово all используется в тех немногих случаях, когда требуется разыменование без выбора.
11.1.3 Реализация
Для косвенного обращения к данным через указатели требуется дополнительная команда в машинном коде. Сравним прямой оператор присваивания с косвенным присваиванием, например:
int i,j; [С]
int *p = &i;
int *q = &j;
i=j; /* Прямое присваивание */
*p = *q; /* Косвенное присваивание */
Машинные команды для прямого присваивания:
load R1,j
store R1,i
в то время как команды для косвенного присваивания:
load R1,&q Адрес (указуемого объекта)
load R2,(R1) Загрузить указуемый объект
load R3,&p Адрес (указуемого объекта)
store R2,(R3) Сохранить в указуемом объекте
При косвенности неизбежны некоторые издержки, но обычно не серьезные, поскольку при неоднократном обращении к указуемому объекту оптимизатор может гарантировать, что указатель будет загружен только один раз. В операторе
p->right = p->left;
раз уж адрес р загружен в регистр, все последующие обращения могут воспользоваться этим регистром:
load R1,&p Адрес указуемого объекта
load R2,left(R1) Смещение от начала записи
store R2,right(R1) Смещение от начала записи
Потенциальным источником неэффективности при косвенном доступе к данным через указатели является размер самих указателей. В начале 1970-х годов, когда разрабатывались языки С и Pascal, компьютеры обычно имели только 16 Кбайт или 32 Кбайт оперативной памяти, и для адреса было достаточно 16 разрядов. Теперь, когда персональные компьютеры и рабочие станции имеют много мегабайтов памяти, указатели должны храниться в 32 разрядах. Кроме того, из-за механизмов управления памятью, основанных на кэше и страничной организации, произвольный доступ к данным через указатели может обойтись намного дороже, чем доступ к массивам, которые располагаются в непрерывной последовательности ячеек. Отсюда следует, что оптимизация структуры данных для повышения эффективности сильно зависит от системы, и ее никогда не следует делать до измерения времени выполнения с помощью профилировщика.
Типизированные указатели в Ada предоставляют одну возможность для оптимизации. Для набора указуемых объектов, связанных с конкретным типом доступа, т. е. для так называемой коллекции (collection), можно задать размер:
type Node_Ptr is access Node;
for Node_Ptr'Storage_Size use 40_000;
Поскольку объем памяти, запрошенный для Node, меньше 64 Кбайт, указатели относительно начала блока могут храниться в 16 разрядах, при этом экономятся и место в структурах данных, и время центрального процессора для загрузки и сохранения указателей.
11.1.4 Указатели и алиасы в Ада 95
Указатель в языке С может использоваться для задания алиаса (альтернативного имени) обычной переменной:
int i;
int*ptr = &i;
Алиасы бывают полезны; например, они могут использоваться для создания связанных структур во время компиляции. Так как в Ада 83 структуры, основанные на указателях, могут быть созданы только при выполнении, это может привести к ненужным издержкам и по времени, и по памяти.
В Ada 95 добавлены специальные средства создания алиасов, названные типами обобщенного доступа (general access types), но на них наложены ограничения для предотвращения создания повисших ссылок. Предусмотрен и специальный синтаксис как для объявления указателя, так и для переменной с алиасом:
type Ptr is access all Integer; -- Ptr может указывать на алиас
I: aliased Integer; --I может иметь алиас
P: Ptr:= I'Access; -- Создать алиас
Первая строка объявляет тип, который может указывать на целочисленную переменную с алиасом, вторая строка объявляет такую переменную, и третья строка объявляет указатель и инициализирует его адресом переменной. Такие типы обобщенного доступа и переменные с алиасом могут быть компонентами массивов и записей, что позволяет построить связанные структуры, не обращаясь к администратору памяти во время выполнения.
11.1.5 Привязка к памяти
В языке С привязка к памяти тривиальна, потому что указателю может быть присвоен произвольный адрес:
int * const reg = 0x4f00;
*reg = Ox1f1f;
/* Адрес (в шестнадцатеричной системе) */
/* Присваивание по абсолютному адресу */
Благодаря использованию указателя-константы, адрес в reg не будет случайно изменен.
В Ada используется понятие спецификации представления для явного установления соответствия между обычной переменной и абсолютным адресом:
Reg: Integer;
for Reg use at 16#4f00#; -- Адрес (в шестнадцатеричной системе)
Reg:= 16#1 f 1 f#; -- Присваивание по абсолютному адресу
Преимущество метода языка Ada состоит в том, что не используются явные указатели
11.2 Структуры данных
Указатели нужны для реализации динамических структур данных, таких как списки и деревья. Кроме элементов данных узел в структуре содержит один или несколько указателей со ссылками на другие узлы (см. рис.3).
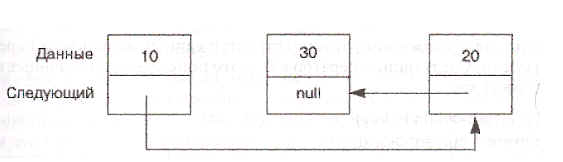
Рис.3. Динамическая структура данных.
Попытка определить узел неизбежно ведет к рекурсии в определении типа, а именно: запись типа node (узел) должна содержать указатель на свой собственный тип node. Для решения этой проблемы в языках допускается задавать частичное объявление записи, в котором указывается имя ее типа. Объявление сопровождается объявлением указателя, ссылающегося на это имя, а далее следует полное объявление записи, в котором уже можно ссылаться на тип указателя. В языке Ada эти три объявления выглядят так:
type Node; -- Незавершенное объявление типа
type Ptr is access Node; -- Объявление типа указателя
type Node is -- Полное объявление
record
Data: Integer; -- Данные в узле
Next: Ptr; -- Указатель на следующий узел
end record;
Язык С требует использования тега структуры и альтернативного синтаксиса для объявления записи:
typedef struct node *Ptr; /* Указатель на структуру с тегом */
typedef struct node { /* Объявление структуры узла */
int data; /* Данные в узле */
Ptr next; /* Указатель на следующий узел */
} node;
В C++ нет необходимости использовать typedef, поскольку struct определяет как тег структуры, так и имя типа:
typedef struct node *Ptr; /* Указатель на структуру с тегом */
struct node { /* Объявление структуры узла */
int data; /* Данные в узле */
Ptr next; /* Указатель на следующий узел */
}
Алгоритмы для прохождения (traverse) структур данных используют переменные-указатели. Следующий оператор в С — это поиск узла, поле данных которого содержит key:
while (current->data!= key)
current = current->next;
Аналогичный оператор в Ada (использующий неявное раскрытие ссылки) таков:
while Current.Data /= Key loop
Current:= Current.Next;
end loop;
Структуры данных характеризуются числом указателей, хранящихся в каждом узле, тем, куда они указывают, и алгоритмами, используемыми для прохождения структур и их обработки.
11.2.1 Указатель null (пустой)
На рисунке 3. поле next последнего элемента списка не указывает ни на что. Обычно считается, что такой указатель имеет специальное значение — пустое, которое отличается от любого допустимого указателя. Пустое значение в Ada обозначается зарезервированным словом null. В предыдущем разделе, чтобы не пропустить конец списка, поиск фактически следовало бы запрограммировать следующим образом:
while (Current /= null) and then (Current.Data /= Key) loop
Current:= Current.Next;
end loop;
Обратите внимание, что укороченное вычисление здесь существенно.
В языке С используется обычный целочисленный литерал «ноль» для обозначения пустого указателя:
while ((current!= 0) && (current->data!= key))
current = current->next;
Нулевой литерал — это всего лишь синтаксическое соглашение; реальное значение зависит от компьютера. При просмотре с помощью отладчика в пустом указателе все биты могут быть, а могут и не быть нулевыми. Для улучшения читаемости программы в библиотеке С определен символ NULL:
while ((current!= NULL) && (current->data!= key))
current = current->next;
Когда объявляется переменная, например целая, ее значение не определено. И это не вызывает особых проблем, поскольку любая комбинация битов задает допустимое целое число. Однако указатели, которые не являются пустыми и при этом не ссылаются на допустимые блоки памяти, могут вызвать серьезные ошибки. Поэтому в Ada каждая переменная-указатель неявно инициализируется как null. В языке С каждая глобальная переменная неявно инициализируется как ноль; глобальные переменные-указатели инициализируются как пустые. Позаботиться о явной инициализации локальных указателей должны сами.
Нужно быть очень осторожными, чтобы случайно не разыменовать пустой указатель, потому что значение null не указывает ни на что (или, вернее, ссылается на данные системы по нулевому адресу):
Current: Ptr:= null;
Current:=Current.Next;
В языке Ada эта ошибка будет причиной исключительной ситуации, но в С результат попытки разыменовывать null может привести к катастрофе. Операционные системы, которые защищают программы друг от друга, смогут прервать «провинившуюся» программу; без такой защиты разыменование могло бы вмешаться в другую программу или даже разрушить систему.
11.2.2 Указатели на подпрограммы
В языке С указатель может ссылаться на функцию. При программировании это чрезвычайно полезно в двух случаях:
• при передаче функции как параметра,
• при создании структуры данных, которая каждому ключу или индексу
ставит в соответствие процедуру.
Например, один из параметров пакета численного интегрирования -- это функция, которую нужно проинтегрировать. Это легко запрограммировать в С, создавая тип данных, который является указателем на функцию; функция получит параметр типа float и вернет значение типа float:
typedef float (*Func) (float);
Этот синтаксис довольно плох потому, что имя типа (в данном случае — Func) находится глубоко внутри объявления, и потому, что старшинство операций в С требует дополнительных круглых скобок.
Раз тип объявлен, он может использоваться как тип формального параметра:
float integrate(Func f, float upper, float lower)
{
float u = f (upper);
float l = f(lower);
…
}
Раскрытие указателя делается автоматически, когда вызывается функция-параметр, иначе нам пришлось бы написать (*f)(upper). Теперь, если определена функция с соответствующей сигнатурой, ее можно использовать как фактический параметр для подпрограммы интегрирования:
float fun (float parm)
{
… /* Определение "fun" */
}
float x = integrate(fun, 1.0, 2.0); /* "fun" как фактический параметр */
Структуры данных с указателями на функции используются при создании интерпретаторов — программ, которые получают последовательность кодов и выполняют действия в соответствии с этими кодами. В то время как статический интерпретатор может быть реализован с помощью case-оператора и обычных вызовов процедур, в динамическом интерпретаторе соответствие между кодами и операциями будет устанавливаться только во время выполнения. Современные системы с окнами используют аналогичную методику программирования: программист должен предоставить возможность обратного вызова (callback), т.е. процедуру, обеспечивающую выполнение соответствующего действия для каждого события. Это указатель на подпрограмму, которая будет выполнена, когда получен код, указывающий, что событие произошло:
typedef enum {Event1,..., Event10} Events;
typedef void (*Actions)(void);
/* Указатель на процедуру */
Actions action [10];
/* Массив указателей на процедуры */
Во время выполнения вызывается процедура, которая устанавливает соответствие между событием и действием:
void install(Events e, Actions a)
{
action [e] = a;
}
Затем, когда событие происходит, его код может использоваться для индексации и вызова соответствующей подпрограммы:
action [е] ();
Поскольку в Ada 83 нет указателей на подпрограммы, эту технологию нельзя запрограммировать без использования нестандартных средств. Когда язык разрабатывался, указатели на подпрограммы были опущены, потому что предполагалось, что родовых (generics) программных модулей будет достаточно для создания математических библиотек, а методика обратного вызова еще не была популярна. В Ada 95 этот недостаток устранен, и разрешены указатели на подпрограммы. Объявление математической библиотечной функции таково:
Type Func is access function(X:Float) return Float;
--Тип: указатель на функцию
function Integrate(F: Func; Upper, Lower: Float);
--Параметр является указателем на функцию
а обратный вызов объявляется следующим образом:
type Events is (Event 1,..., Event 10);
type Actions is access procedure;
--Тип: указатель на процедуру
Action: array(Events) of Actions;
--Массив указателей на процедуры
11.2.3 Указатели и массивы
В языке Ada в рамках строгого контроля типов единственно допустимые операции на указателях — это присваивание, равенство и разыменование. В языке С, однако, считается, что указатели будут неявными последовательными адресами, и допустимы арифметические операции над значениями указателей. Это ясно из взаимоотношений указателей и массивов: указатели рассматриваются как более простое понятие, а доступ к массиву определяется в терминах указателей. В следующем примере
int *ptr; /* Указатель на целое */
int а[100]; /* Массив целых чисел */
ptr = &а[0]; /* Явный адрес первого элемента */
ptr = а; /* Неявный тот же адрес */
два оператора присваивания эквивалентны, потому что имя массива рассматривается всего лишь как указатель на первый элемент массива. Более того, если прибавление или вычитание единицы делается для указателя, результат будет не числом, а результатом увеличения или уменьшения указателя на размер типа, на который ссылается указатель. Если для целого числа требуются четыре байта, а р содержит адрес 344, то р+1 равно не 345, а 348, т.е. адресу «следующего» целого числа. Доступ к элементу массива осуществляется прибавлением индекса к указателю и разыменованием, следовательно, два следующих выражения эквивалентны:
*(ptr + i)
a[i]
Несмотря на эту эквивалентность, в языке С все же остается значительное различие между массивом и указателем:
char s1[] = "Hello world";
char *s2 = "Hello world";
Здесь s1 — это место расположения последовательности из 12 байтов, содержащей строку, в то время как s2 — это переменная-указатель, содержащая адрес аналогичной последовательности байтов (см. рис. 4). Однако s1[i] –
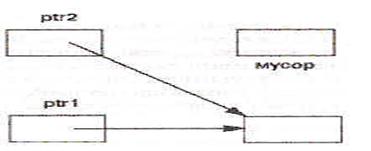
Рис. 4. Массив и указатель в языке С.
это то же самое, что и *(s2+i) для любого i из рассматриваемого диапазона, потому что массив при использовании автоматически преобразуется в указатель.
Проблема арифметических операций над указателями состоит в том, что нет никакой гарантии, что результат выражения действительно ссылается на элемент массива. Тогда как нотацию индексации относительно легко понять и быть уверенным в ее правильности, арифметических операций над указателями по возможности следует избегать. Однако они могут быть очень полезны для улучшения эффективности в циклах, если ваш оптимизатор недостаточно хорош.
11.3.1 Распределение памяти
При выполнении программы память используется для хранения как программ (кода), так и различных структур данных, например стека. Хотя распределение и освобождение памяти правильнее обсуждать в контексте компиляторов и операционных систем, вполне уместно сделать обзор этой темы здесь, потому что реализация может существенно повлиять на выбор конструкций языка и стиля программирования.
Существует пять типов памяти, которые должны быть выделены.
Код. Машинные команды, которые являются результатом компиляции программы.
Константы. Небольшие константы, такие как 2 и 'х', часто могут содержаться внутри команды, но для больших констант память должна выделяться особо, в частности для констант с плавающей точкой и строк.
Стек. Стековая память используется в основном для записей активации, которые содержат параметры, переменные и ссылки. Она также используется для временных переменных при вычислении выражений.
Статические данные. Это переменные, объявленные в главной программе и в других местах: в Ada — данные, объявленные непосредственно внутри библиотечных пакетов; в С — данные, объявленные непосредственно внутри файла или объявленные как статические (static) в блоке.
Динамическая область. Динамическая область (куча — heap) — термин, используемый для области данных, из которой данные динамически выделяются командой malloc в С и new в Ada и C++.
Код и константы похожи тем, что они определяются во время компиляции и уже не изменяются. Поэтому объединим эти два типа памяти вместе. Если система это поддерживает, код и константы могут храниться в памяти, доступной только для чтения (ROM).
Статические (глобальные) данные можно считать распределенными в начале стека. Однако статические данные обычно распределяются независимо. Например, в Intel 8086 каждая область данных (называемая сегментом) ограничена 64 Кбайтами. Поэтому есть смысл выделять отдельный сегмент для стека помимо одного или нескольких сегментов для статических данных.
И наконец, должны выделить память для кучи. Динамическая область отличается от стека тем, что выделение и освобождение памяти может быть очень хаотичным. Исполняющая система должна применять сложные алгоритмы, чтобы гарантировать оптимальное использование динамической области.
Программа обычно помещается в отдельную, непрерывную область. Память должна быть разделена так, чтобы разместить требуемые области памяти. На рисунке 5 показано, как это реализуется. Поскольку области кода, констант и статических данных имеют фиксированные размеры, они распределяются в начале памяти.
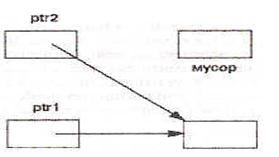
Рис. 5. Распределение памяти: код, данные, стек и куча.
Две области переменной длины, куча и стек помещаются в противоположные концы остающейся памяти.
При таком способе, если программа использует большой стек во время одной фазы вычисления и большую кучу во время другой фазы, то меньше шансов, что памяти окажется недостаточно.
Важно понять, что каждое выделение памяти в стеке или в куче (то есть каждый вызов процедуры и каждое выполнение программы выделения памяти) может закончиться неудачей из-за недостатка памяти. Тщательно разработанная программа должна уметь восстанавливаться при недостатке памяти, но такую ситуацию нелегко обработать, потому что процедуре, которая выполняет восстановление, может понадобиться еще больший объем памяти! Поэтому желательно получать сигнал о недостатке памяти, когда еще остается значительный резерв.