 2014-02-09
2014-02-09 440
44012.7 Неограниченные записи в Ada
В дополнение к ограниченным записям, вариант которых при создании переменной фиксирован, Ada допускает объявление неограниченных записей (unconstrained records), для которых допустимо во время выполнения безопасное с точки зрения контроля типов присваивание, хотя записи относятся к разным вариантам:
S1, S2: S_Type; -- Неограниченные записи
S1:= (Record_Code, 4.5);
S2:= (Array_Code, 1..10=>17);
S1:= S2; -- Присваивание S1 другого варианта
-- S2 больше, чем S1!
Два правила гарантируют, что контроль соответствия типов продолжает работать:
• Для дискриминанта должно быть задано значение по умолчанию, чтобы гарантировать, что первоначально в записи есть осмысленный дискриминант:
type S_Type (Code: codes: = Record_Code) is...
• Само по себе поле дискриминанта не может быть изменено. Допустимо только присваивание допустимого значения всей записи, как показано в примере.
Существуют две возможные реализации неограниченных записей. Можно создавать каждую переменную с размером максимального варианта, чтобы помещался любой вариант. Другая возможность - неявно использовать динамическую память из кучи. Если присваиваемое значение больше по размерам, то память освобождается и запрашивается большая порция. В большинстве реализаций выбран первый метод: он проще и не требует нежелательных в некоторых приложениях неявных обращений к менеджеру кучи.
12.8 Динамическая диспетчеризация
Предположим, что каждый вариант записи S_Type должен быть обработан собственной подпрограммой. Нужно использовать case-оператор, чтобы перейти (dispatch) в соответствующую подпрограмму. Рассмотрим «диспетчерскую» процедуру:
procedure Dispatch(S: S_Type) is IAda
begin
case S.Code is
when Record_Code => Process_Rec(S);
when Array_Code => Process_Array(S);
end case;
end Dispatch;
Предположим далее, что при изменении программы в запись необходимо добавить дополнительный вариант. Сделать изменения в программе нетрудно: добавить код к типу Codes, добавить вариант в case-оператор процедуры Dispatch и добавить новую подпрограмму обработки. Насколько легко сделать эти изменения, настолько они могут быть проблематичными в больших системах, потому что требуют, чтобы исходный код существующих, хорошо проверенных компонентов программы был изменен и перекомпилирован. Кроме того, вероятно, необходимо сделать повторное тестирование, чтобы гарантировать, что изменение глобального типа перечисления не имеет непредусмотренных побочных эффектов.
Решением является размещение «диспетчерского» кода так, чтобы он был частью системы на этапе выполнения, поддерживающей язык, а не явно запрограммированным кодом, как показано выше. Это называется динамическим полиморфизмом, так как теперь можно вызвать общую программу Process(S), а привязку вызова конкретной подпрограммы отложить до этапа выполнения, когда станет известен текущий тег S. Этот полиморфизм поддерживается виртуальными функциями (virtual functions) в C++ и подпрограммами с class-wide-параметрами в Ada 95.
13. ПАРАЛЛЕЛИЗМ
13.1. Что такое параллелизм?
Компьютеры с несколькими центральными процессорами (ЦП) могут выполнять несколько программ или компонентов одной программы параллельно. Вычисление, таким образом, может завершиться за меньшее время счета (количество часов), чем на компьютере с одним ЦП, с учетом затрат дополнительного времени ЦП на синхронизацию и связь. Несколько программ могут также совместно использовать компьютер с одним ЦП, так быстро переключая ЦП с одной программы на другую, что возникает впечатление, будто они выполняются одновременно. Несмотря на то, что переключение ЦП не реализует настоящую параллельность, удобно разрабатывать программное обеспечение для этих систем так, как если бы выполнение программ действительно происходило параллельно. Параллелизм — это термин, используемый для обозначения одновременного выполнения нескольких программ без уточнения, является вычисление параллельным на самом деле или только таким кажется.
Прямой параллелизм знаком большинству программистов в следующих формах::
• Мультипрограммные (multi-programming) операционные системы дают
возможность одновременно использовать компьютер нескольким поль
зователям. Системы разделения времени, реализованные на обычных
больших машинах и миникомпьютерах, в течение многих лет были
единственным способом сделать доступными вычислительные средства
для таких больших коллективов, как университеты.
• Многозадачные (multi-tasking) операционные системы дают возможность
одновременно выполнять несколько компонентов одной программы
(или программ одного пользователя). С появлением персональных ком
пьютеров мультипрограммные компьютеры стали менее распространен
ными, но даже одному человеку часто необходим многозадачный режим
для одновременного выполнения разных задач, как, например, фоновая
печать при диалоговом режиме работы с документом.
• Встроенные системы (embedded systems) на заводах, транспортных систе
мах и в медицинской аппаратуре управляют наборами датчиков и приво-
дов в «реальном масштабе времени». Для этих систем характерно требование, чтобы они выполняли относительно небольшие по объему вычисления через очень короткие промежутки времени: каждый датчик должен быть считан и проинтерпретирован, затем программа должна выбрать соответствующее действие, и, наконец, данные в определенном формате должны быть переданы к приводам. Для реализации встроенных систем используются многозадачные операционные системы, позволяющие координировать десятки обособленных вычислений.
Проектирование и программирование параллельных систем являются чрезвычайно сложным делом, и целые учебники посвящены различным аспектам этой проблемы: архитектуре систем, диспетчеризации задач, аппаратным интерфейсам и т. д. Цель этого раздела состоит в том, чтобы дать краткий обзор языковой поддержки параллелизма, который традиционно обеспечивался функциями операционной системы и аппаратурой.
Параллельная программа (concurent program) состоит из одного или нескольких программных компонентов (процессов), которые могут выполняться параллельно. Параллельные программы сталкиваются с двумя проблемами:
Синхронизация. Даже если процессы выполняются одновременно, иногда один процесс должен будет синхронизировать свое выполнение с другими процессами. Наиболее важная форма синхронизации — взаимное исключение: два процесса не должны обращаться к одному и тому же ресурсу (такому, как диск или общая таблица) одновременно.
Взаимодействие. Процессы не являются полностью независимыми; они должны обмениваться данными. Например, в программе управления полетом процесс, считывающий показания датчика высоты, должен передать результат процессу, который делает расчеты для автопилота.
13.2. Общая память
Самая простая модель параллельного программирования — это модель с общей памятью (см. рис. 1). Два или несколько процессов могут обращаться к одной и той же области памяти, хотя они также могут иметь свою собственную частную, или приватную, (private) память. Предположим, что есть два процесса, которые пытаются изменить одну и ту же переменную в общей памяти (в языке Ada процессы называются задачами (tasks)):
procedure Main is
N: Integer:= 0;
task T1;
task T2;
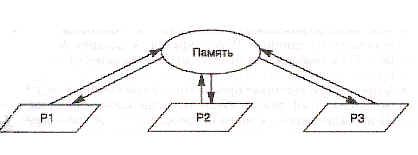
Рис.1. Модель параллелизма с общей памятью.
task body Т1 is
begin
for I in 1.. 100 loop N:= N+1; end loop;
end T1;
task body T2 is
begin
for I in 1..100 loop N:= N+1; end loop;
end T2;
begin
null;
end Main;
Рассмотрим теперь реализацию оператора присваивания:
load R1, N Загрузить из памяти
add R1,#1 Увеличить содержимое регистра
store R1,N Сохранить в памяти
Если каждое выполнение тела цикла в Т1 завершается до того, как Т2 выполняет свое тело цикла, N будет увеличено 200 раз. Однако каждая задача может быть выполнена на отдельном компьютере со своим набором регистров. В этом случае может иметь место следующая последовательность событий:
• Т1 загружает N в свой регистр R1 (значение равно п).
• Т2 загружает N в свой регистр R1 (значение равно п).
• Т1 увеличивает R1 (значение равно п + 1).
• Т2 увеличивает R1 (значение равно п + 1).
• Т1 сохраняет содержимое своего регистра R1 в N (значение равно п + 1).
• Т2 сохраняет содержимое своего регистра R1 в N (значение равно п + 1).
Результат выполнения каждого из двух тел циклов состоит только в том, что N увеличится на единицу. Результирующее значение N может лежать между 100 и 200 в зависимости от относительной скорости каждого из двух процессоров.
Важно понять, что это может произойти даже на компьютере, который реализует многозадачный режим путем использования единственного ЦП. Когда ЦП переключается с одного процесса на другой, регистры, которые используются заблокированным процессом, сохраняются, а затем восстанавливаются, когда этот процесс продолжается.
В теории параллелизма выполнение параллельной программы определяется как любое чередование атомарных команд задач. Атомарная команда -это всего лишь команда, которую нельзя выполнить «частично» или прервать, чтобы продолжить выполнение другой задачи. В модели параллелизма с общей памятью команды загрузки и сохранения являются атомарными.
Если говорить о чередующихся вычислениях, то языки и системы, которые поддерживают параллелизм, различаются уровнем определенных в них атомарных команд. Реализация команды должна гарантировать, что она выполняется атомарно. В случае команд загрузки и сохранения это обеспечивается аппаратным интерфейсом памяти. Атомарность команд высокого уровня реализуется с помощью базисной системы поддержки времени выполнения и поддерживается специальными командами ЦП.
13.3. Проблема взаимных исключений
Проблема взаимных исключений (mutual exclusion problem) для параллельных I программ является обобщением приведенного выше примера. Предполагается, что в каждой задаче (из параллельно выполняемых) вычисление делится на критическую (critical) и некритическую (non-critical) секцию (section), которые неоднократно выполняются:
task body T_i is
begin
loop
Prologue;
Critical_Section;
Epilogue;
Non_Critical_Section;
end loop;
end T_i:
Для решения проблемы взаимных исключений надо найти такие последовательности кода, называемые прологом (prologue) и эпилогом (epilogue), чтобы программа удовлетворяла следующим требованиям, которые должны выполняться для всех чередований последовательностей команд из набора задач:
Взаимное исключение. В любой момент времени только одна задача выполняет свою критическую секцию.
Отсутствие взаимоблокировки (no deadlock). Всегда есть, по крайней мере, одна задача, которая в состоянии продолжить выполнение.
Жизнеспособность. Если задаче необходимо выполнить критическую секцию, в конце концов она это сделает.
Справедливость. Доступ к критическому участку предоставляется «по справедливости».
Существуют варианты решения проблемы взаимных исключений, использующие в качестве атомарных команд только load (загрузить) и store (сохранить), но эти решения трудны для понимания.
Э. Дейкстра (E.W. Dijkstra) определил абстракцию синхронизации высокого уровня, называемую семафором, которая тривиально решает эту проблему. Семафор S является переменной, которая имеет целочисленное значение; для семафоров определены две атомарные команды:
Wait(S): when S > 0 do S:= S -1;
Signal(S): S:=S+1;
Процесс, выполняющий команду Wait(S), блокируется на время, пока значение S неположительно. Поскольку команда является атомарной, то, как только процесс удостоверится, что S положительно, он сразу уменьшит S (до того, как любой другой процесс выполнит команду!). Точно так же Signal(S) выполняется атомарно без возможности прерывания другим процессом между загрузкой и сохранением S. Проблема взаимных исключений решается следующим образом:
procedure Main is
S: Semaphore:= 1;
task T_i; — Одна из многих
task body T_i is
begin
loop
Wait(S);
Critical_Section;
Signal(S);
Non_Critical_Section;
end loop;
end T_i;
begin
null;
end Main;
13.4. Мониторы и защищенные переменные
Проблема, связанная с семафорами и аналогичными средствами, обеспечиваемыми операционной системой, состоит в том, что они не структурны. Если нарушено соответствие между Wait и Signal, программа может утратить синхронизацию или блокировку. Для решения проблемы структурности была разработана концепция так называемых мониторов (monitors), и они реализованы в нескольких языках. Монитор — это совокупность данных и подпрограмм, которые обладают следующими свойствами:
• Данные доступны только подпрограммам монитора.
• В любой момент времени может выполняться не более одной подпрограммы монитора.. Попытка процесса вызвать процедуру монитора в то время, как другой процесс уже выполняется в мониторе, приведет к приостановке нового процесса.
Поскольку вся синхронизация и связь выполняются в мониторе, потенциальные ошибки параллелизма определяются непосредственно программированием самого монитора; а процессы пользователя привести к дополнительным ошибкам не могут. Интерфейс монитора аналогичен интерфейсу операционной системы, в которой процесс вызывает монитор, чтобы запросить и получить обслуживание. Синхронизация процессов обеспечивается автоматически. Недостаток монитора в том, что он является централизованным средством.
Первоначально модель параллелизма в языке Ada была чрезвычайно сложной и требовала слишком больших затрат для решения простых проблем взаимных исключений. Чтобы это исправить, в Ada 95 были введены средства, аналогичные мониторам, которые называются защищенными переменными (protected variables). Например, семафор можно смоделировать как защищенную переменную. Этот интерфейс определяет две операции, но целочисленное значение семафора рассматривает как приватное (private), что означает, что оно недоступно для пользователей семафора:
protected type Semaphore is
entry Wait;
procedure Signal;
private
Value: Integer:=1;
End Semaphore;
Реализация семафора выглядит следующим образом:
protected body Semaphore is
entry Wait when Value > 0 is
begin
Value:= Value - 1;
end Wait;
procedure Signal is
begin
Value:= Value + 1;
end Signal;
end Semaphore;
Выполнение entry и procedure взаимно исключено: в любой момент времени только одна задача будет выполнять операцию с защищенной переменной. К тому же entry имеет барьер (barrier), который является булевым выражением. Задача, пытающаяся выполнить entry, будет заблокирована, если выражение имеет значение «ложь». Всякий раз при завершении защищенной операции все барьеры будут перевычисляться, и будет разрешено выполнение той задачи, барьер которой имеет значение «истина». В приведенном примере, когда Signal увеличит Value, барьер в Wait будет иметь значение «истина», и заблокированная задача сможет выполнить тело entry.
13.5. Передача сообщений
По мере того как компьютерные аппаратные средства дешевеют, распределенное программирование приобретает все большее значение. Программы разбиваются на параллельные компоненты, которые выполняются на разных компьютерах. Модель с разделяемой памятью уже не годится; проблема синхронизации и связи переносится на синхронную передачу сообщений (synchronous message passing), изображенную на рис.2. В этой модели канал связи с может существовать между любыми двумя процессами. Когда один процесс посылает сообщение m в канал, он приостанавливается до тех пор, пока другой процесс не будет готов его получить. Симметрично, процесс, который ожидает получения сообщения, приостанавливается, пока посылающий процесс не готов послать. Эта приостановка используется для синхронизации процессов.
Синхронная модель параллелизма может быть реализована в самом языке программирования или в виде услуги операционной системы: потоки (pipes),

Рис.2. Параллелизм с передачей сообщений (оссаm).
гнезда (sockets) и т.д. Модели отличаются способами, которыми процессы адресуют друг друга, и способом передачи сообщений.
13.6. Язык параллельного программирования оссаm
Модель синхронных сообщений была первоначально разработана Хоаром (С. A. R. Ноаге) в формализме - называющемся CSP (Communicating Sequential Processes — Взаимодействующие последовательные процессы). На практике он реализован в языке оссаm, который был разработан для программирования транспьютеров — аппаратной многопроцессорной архитектуры для распределенной обработки данных.
В языке оссаm адресация фиксирована, и передача сообщений односторонняя, как показано на рисунке.2. Канал имеет имя и может использоваться только для отправки сообщения из одного процесса и получения его в другом:
CHAN OF INT c:
PAR
INT m:
SEQ
--Создается целочисленное значение m
с! m
INT v:
SEQ
с? v
-- Используется целочисленное значение в v
с объявлено как канал, который может передавать целые числа. Канал должен использоваться именно в двух процессах: один процесс содержит команды вывода (с!), а другой — команды ввода (с?).
Интересен синтаксис языка оссаm. В других языках режим выполнения «по умолчанию» — это последовательное выполнение группы операторов, а для задания параллелизма требуются специальные указания. В языке оссаm параллельные и последовательные вычисления считаются в равной степени важными, поэтому должны явно указать, используя PAR и SEQ, как именно должна выполняться каждая группа (выровненных отступами) операторов.
Хотя каждый канал связывает ровно два процесса, язык оссаm допускает, чтобы процесс одновременно ждал передачи данных по любому из нескольких каналов:
[10]CHAN OF INT с: — Массив каналов
ALT i=0 FOR 1O
c[i ]? v
-- Используется целочисленное значение в v
Этот процесс ждет передачи данных по любому из десяти каналов, а обработка полученного значения может зависеть от индекса канала.
Преимущество коммуникации точка-точка состоит в ее чрезвычайной эффективности, потому что вся адресная информация «скомпилирована». Не требуется никаких других средств поддержки во время выполнения кроме синхронизации процессов и передачи данных; в транспьютерных системах это делается аппаратными средствами. Конечно, эта эффективность достигается за счет уменьшения гибкости.
13.7. Рандеву в языке Ada
Задачи в языке Ada взаимодействуют друг с другом во время рандеву (rendezvous). Говорят, что одна задача Т1 вызывает вход (entry) e в другой задаче Т2 (см. рис.3). Вызываемая задача должна выполнить accept-оператор для этого входа:
accept Е(Р1: in Integer; P2: out Integer) do
…
end E;
Когда задача выполняет вызов входа, и есть другая задача, которая уже выполнила accept для этого входа, имеет место рандеву.
• Вызывающая задача передает входные параметры принимающей задаче
и затем блокируется.
• Принимающая задача выполняет операторы в теле accept.
• Принимающая задача возвращает выходные параметры вызывающей
задаче.
• Вызывающая задача разблокируется.

Рис. 3. Задачи и входы в Ada.
Определение рандеву симметрично в том смысле, что, если задача выполняет accept-оператор, но ожидаемого вызова входа еще не произошло, она
будет заблокирована, пока некоторая задача не вызывет вход для этого accept-оператора.
Подчеркнем, что адресация осуществляется только в одном направлении: вызывающая задача должна знать имя принимающей задачи, но принимающая задача не знает имени вызывающей задачи. Возможность создания серверов (servers), т. е. процессов, предоставляющих определенные услуги любому другому процессу, послужила мотивом для выбора такого проектного решения. Задача-клиент (client) должна, конечно, знать название сервиса, который она запрашивает, в то время как задача-сервер предоставит сервис любой задаче, и ей не нужно ничего знать о клиенте.
Одно рандеву может включать передачу сообщений в двух направлениях, потому что типичный сервис может быть запросом элемента из структуры данных. Издержки на дополнительное взаимодействие, чтобы возвратить результат, были бы сверхмерными.
Механизм рандеву чрезвычайно сложен: задача может одновременно ждать вызова различных точек входа, используя select-оператор:
select
accept E1 do... end E1;
or
accept E2 do... end E2;
or
accept E3 do... end E3;
end select;
Альтернативы выбора в select могут содержать булевы выражения, называемые охраной (guards), которые дают возможность задаче контролировать, какие вызовы она хочет принимать. Можно задавать таймауты (предельные времена ожидания рандеву) и осуществлять опросы (для немедленной реакции в критических случаях). В отличие от конструкции ALT в языке оссаm, select-оператор языка Ada не может одновременно ожидать произвольного числа входов.
Обратите внимание на основное различие между защищенными переменными и рандеву:
• Защищенная переменная — это пассивный механизм, а его операции
выполняются другими задачами.
• accept-оператор выполняется задачей, в которой он появляется, то есть он выполняет вычисление от имени других задач.
Рандеву можно использовать для программирования сервера и в том случае, если сервер делает значимую обработку помимо связи с клиентом:
task Server is
begin
loop
select
accept Put(l: in Item) do
--Отправить I в структуру данных
end Put;
or
accept Get(l: out Item) do
--Достать I из структуры данных
end Get;
end select;
-- Обслуживание структуры данных
end loop;
end Server;
Сервер отправляет элементы в структуру данных и достает их из нее, а после каждой операции он выполняет дополнительную обработку структуры данных, например регистрирует изменения. Нет необходимости блокировать другие задачи во время выполнения этой обработки, отнимающей много времени.
В языке Ada чрезвычайно гибкий механизм параллелизма, но эта гибкость достигается ценой менее эффективной связи, чем коммуникации точка-точка в языке оссаm. С другой стороны, в языке оссаm фактически невозможно реализовать гибкий серверный процесс, так как каждый дополнительный клиентский процесс нуждается в отдельном именованном канале, а это требует изменения программы сервера.
13.8. Linda
Linda — это не язык программирования как таковой, а модель параллелизма, которая может быть добавлена к существующему языку программирования. В отличие от однонаправленной (Ada) или двунаправленной адресации (occam), Linda вообще не использует никакой адресации между параллельными процессами! Вместо этого процесс может по выбору отправить сообщение в глобальную кортежную область (Tuple Space). Она названа так потому, что каждое сообщение представляет собой кортеж, т. е. последовательность из одного или нескольких значений, возможно, разных типов. Например:
(True, 5.6, 'С', False)
Кортежная область
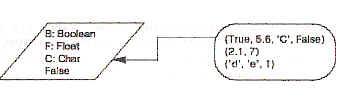
Рис. 4. Кортежная область в модели Linda.
- это четверной кортеж, состоящий из булева с плавающей точкой, символьного и снова булева значений.
Существуют три операции, которые обращаются к кортежной области:
out - поместить кортеж в кортежную область;
in - блокировка, пока не существует соответствующего кортежа, затем его удаление (см. рис. 4);
read — блокировка, пока не существует соответствующего кортежа (но без удаления его).
Синхронизация достигается благодаря тому, что команды in и read должны определять сигнатуру кортежа: число элементов и их типы. Только если кортеж существует с соответствующей сигнатурой, может быть выполнена операция получения, иначе процесс будет приостановлен. Кроме того, один или несколько элементов кортежа могут быть заданы явно. Если значение задано в сигнатуре, оно должно соответствовать значению в той же самой позиции кортежа; если задан тип, он может соответствовать любому значению этого типа в данной позиции. Например, все последующие операторы удалят первый кортеж в кортежной области на рис.4:
in(True, 5.6, 'С', False)
in(B: Boolean, 5.6, 'С', False)
in(True, F: Float, 'С', В2: Boolean)
Второй оператор in возвратит значение True в формальном параметре В; третий оператор in возвратит значения 5.6 в F и False — в В2.
Кортежная область может использоваться для диспетчеризации вычислительных работ для процессов, которые могут находиться на разных компьютерах. Кортеж ("job", J, С) укажет, что работу J следует назначить компьютеру С. Каждый компьютер может быть заблокирован в ожидании работы:
in("job", J: Jobs, 4); -- Компьютер 4 ждет работу
Задача диспетчеризации может «бросать» работы в кортежную область. С помощью формального параметра оператора out можно указать, что безразлично, какой именно компьютер делает данную работу:
out("job", 6, С: Computers); -- Работа 6 для любого компьютера
Преимущество модели Linda в чрезвычайной гибкости. Процесс может поместить кортеж в кортежную область и завершиться; только позднее другой процесс найдет этот кортеж. Таким образом, Linda-программа распределена как во времени, так и в пространстве (среди процессов, которые могут быть на отдельных ЦП). Сравните это с языками Ada и оссаm, которые требуют, чтобы процессы непосредственно связывались друг с другом. Недостаток модели Linda состоит в дополнительных затратах на поддержку кортежной области, которая требует потенциально неограниченной глобальной памяти. Хотя кортежная область и является глобальной, были разработаны сложные алгоритмы для ее распределения среди многих процессоров.
14.Объектно-ориентированное программирование
В предыдущей главе обсуждалась языковая поддержка структурирования программ, но мы не пытались ответить на вопрос: как следует разбивать программы на модули? Обычно этот предмет изучается в курсе по разработке программного обеспечения, но один метод декомпозиции программ, называемый объектно-ориентированным программированием (ООП), настолько важен, что современные языки программирования непосредственно поддерживают этот метод.
При проектировании программы естественный подход должен состоять в том, чтобы исследовать требования в терминах функций или операций, то есть задать вопрос: что должна делать программа? Например, программное обеспечение для предварительной продажи билетов в авиакомпании должно выполнять такие функции:
1. Принять от кассира место назначения заказчика и дату отправления.
2. Отобразить на терминале кассира список доступных рейсов.
3. Принять от кассира предварительный заказ на конкретный рейс.
4. Подтвердить предварительный заказ и напечатать билет.
Эти требования, естественно, находят отражение в проекте, показанном на рис.1, с модулем для каждой функции и «главным» модулем, который вызывает другие.
Но этот проект не будет надежным в эксплуатации; даже для небольших изменений в требованиях могут понадобиться значительные изменения программного обеспечения. Для примера предположим, что авиакомпания улучшает условия труда, заменяя устаревшие дисплейные терминалы. Вполне правдоподобно, что для новых терминалов потребуется изменить все четыре модуля; точно так же придется вносить много исправлений, если изменятся соглашения о форматах информации, используемой совместно с другими компаниями.
Так как изменение программного обеспечения чревато внесением ошибок; не устойчивый к ошибкам проект приведет к тому, что поставленная программная система будет ненадежной и неустойчивой. Персонал должен воздержаться от изменения программного обеспечения, но весь смысл программного обеспечения состоит в том, что это именно программное обеспечение, а значит, его можно перепрограммировать, изменить; иначе все прикладные программы было бы эффективнее «зашить» подобно программе карманного калькулятора.
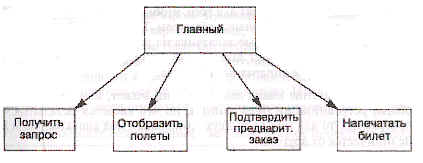
Рис. 1. Функциональная декомпозиция.
Программное обеспечение можно сделать намного устойчивее к ошибкам и надежнее, если изменить основные критерии, которыми мы руководствуемся при проектировании. Правильнее задать вопрос: над чем работает программное обеспечение? Акцент делается не на функциональных возможностях, а на внешних устройствах, внутренних структурах данных и моделях реального мира, т. е. на том, что принято называть объектами (objects). Модуль должен быть создан для каждого «объекта» и содержать все данные и операции, необходимые для реализации объекта. В нашем примере мы можем выделить несколько объектов, как показано на рис. 2.
Такие внешние устройства, как дисплейный терминал и принтер, идентифицированы как объекты, так же как и базы данных с информацией о рейсах и предварительных заказах. Кроме того, мы выделили объект Заказчик, назначение которого — моделировать воображаемую форму, в которую кассир вводит данные до того, как подтвержден рейс и выдан билет. Этот проект устойчив к ошибкам при внесении изменений:

Рис. 2. Объектно-ориентированное проектирование.
• Изменения, которые вносят для того, чтобы использовать разные терми
налы, могут быть ограничены объектом Терминал. Программы этого
объекта отображают данные заказчика на реальный дисплей и команды
клавиатуры, так что объект Заказчик не должен изменяться, а только ото
бражаться на новые аппаратные средства.
• Перераспределение кодов авиакомпаний может, конечно, потребовать
общей реорганизации базы данных, но что касается остальных частей
программы, то для них один двухсимвольный код авиакомпании ничем
не отличается от другого.
Объектно-ориентированное проектирование можно использовать не только для моделирования реальных объектов, но и для создания многократно используемых программных компонентов. Это непосредственно связано с одной из концепций языков программирования, которую мы подчеркивали, — абстрагированием. Модули, реализующие структуры данных, могут быть разработаны и запрограммированы как объекты, которые являются экземплярами абстрактного типа данных вместе с операциями для обработки данных. Абстрагирование достигается за счет того, что представление типа данных скрывается внутри объекта.
Фактически, основное различие между объектно-ориентированным и «обычным» программированием состоит в том, что в обычном программировании мы ограничены встроенными абстракциями, в то время как в объектно-ориентированном мы можем определять свои собственные абстракции..
Как можно создавать новые абстракции? Один из способов состоит в том, чтобы использовать соглашения кодирования и документирование («первый элемент массива — вещественная часть, а второй — мнимая часть»). С другой стороны, язык может обеспечивать такую конструкцию, как приватные типы в языке Ada, которая дает возможность программисту явно определить новые абстракции; эти абстракции будут компилироваться и проверяться точно так же, как и встроенные абстракции. ООП можно (и полезно) применять и в рамках обычных языков, но, аналогично другим идеям в программировании, оно работает лучше всего, когда используются языки, которые непосредственно поддерживают это понятие. Основная конструкция для поддержки ООП — абстрактный тип данных, который обсуждался в предыдущей главе, но важно понять, что объектно-ориентированное проектирование I является более общим и простирается до абстрагирования внешних устройств, моделей реального мира и т. д.
Объектно-ориентированное проектирование — дело чрезвычайно сложное. Нужны большой опыт и здравый смысл, чтобы решить, что же заслуживает того, чтобы стать объектом. Наилучшее интуитивное правило, на которое стоит опираться, — это правило упрятывания информации:
В каждом объекте должно скрываться одно важное проектное решение.
Конкретные дисплейные терминалы и принтеры, выбранные для системы предварительных заказов, явно подлежат обновлению. Точно так же решения по организации базы данных, вероятно, будут изменяться, чтобы улучшить эффективность, поскольку система растет. С другой стороны, можно было бы привести доводы, что изменение формы данных заказчика маловероятно и что отдельный объект здесь не нужен. Даже если вы не согласны с нашим проектным решением создать объект Заказчик, вы должны согласиться, что объектно-ориентированное проектирование — хороший общий подход для обсуждения проблем разработки и достоинств одного проекта перед другим.
Сначала рассмотрим язык C++, который был разработан как добавление одной интегрированной конструкции для ООП к языку С, в котором нет поддержки даже для модулей. Затем, как полное объектно-ориентированное программирование определено в языке Ada 95 путем добавления нескольких небольших конструкций к языку Ada S3, который уже имел много свойств, частично поддерживающих ООП.








