 2014-02-09
2014-02-09 593
593Стандарт сжатия изображений JPEG (Joint Photographic Experts
Group) включает два способа сжатия: первый предназначен для сжатия без потерь, второй – сжатия с потерей качества. Метод сжатия без потерь, используемый в стандарте JPEG основан на методе разностного (дифференциального) кодирования. Основная идея дифференциального кодирования состоит в следующем. Обычно изображения характеризуются сильной корреляцией между точками изображения. Этот факт учитывается при разностном кодировании, а именно, вместо сжатия последовательности точек изображения x 1, x 2,... xN сжатию подвергается последовательность разностей yi = xi - xi -1,. i =1,2,... N, x 0 = 0. Числа yi называют ошибками предсказания xi. Типичные распределения значений точек xi и yi на входе и выходе дифференциального кодера приведены на рис.2а и 2б. Очевидно, что распределение, представленное на рис.2а, близко к равномерному, т.е. вероятность каждого значения pi ≈1/256 и длина кодового слова в среднем равна 8 битам, т.е. сжатие информации при побуквенном кодировании будет незначительным. Распределение, показанное на рис. 2б, неравномерное, и средняя длина кодового слова при кодировании неравномерным кодом будет менее 8 бит и возможно достичь заметного сжатия изображения.
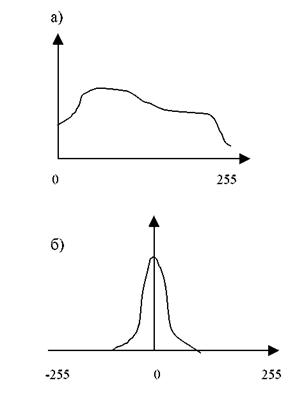
Рисунок 2 – Типичные распределения вероятностей значений отсчетов изображения (а) и ошибок предсказания отсчетов (б)
В стандарте JPEG без потерь предусмотрено формирование ошибок предсказания с использованием предыдущих закодированных точек в текущей строке и/или в предыдущей строке. Ошибка предсказания для точки X на рис.3 вычисляется как r = y – X, где y может быть одной из следующих функций:
y = 0; y = a;
y = b; y = c;
y = a + b + c,
y = a + (b - c) / 2;
y = b + (a - c) / 2;
y = (a + b) / 2.
| c | b | ||
| a | X | ||
Рисунок 3 – Предсказание в стандарте JPEG
Заметим, что значения на позициях a, b, c известны как кодеру, так и декодеру до обработки точки X. Выбор функции для вычисления y задается в заголовке битового потока на выходе кодера. Таким образом, кодер и декодер используют идентичные функции. Полученные ошибки предсказания округляются до ближайшего целого значения.
Затем каждое значение y преобразуется в пару символов (битовая категория, значение). Битовая категория представляет собой число двоичных знаков, необходимое для представления значения y. Битовые категории кодируются кодом Хаффмана. Для передачи самого значения используется равномерный код, длина которого определяется битовой категорией. Значения битовых категорий всех возможных значений целых чисел от –32767 до 32768 приведены в таблице 2.
Например, если ошибка предсказания X оказалась равной y= 42, то из таблицы 2 следует, что это y принадлежит категории 6, т.е. что для представления числа 42 требуется 6 бит. Ошибка предсказания преобразуется в пару (6, 6-битовый код для числа 42). Категория 6 кодируется словом кода Хаффмана. Таким образом, сжатое представление y состоит из слова кода Хаффмана со следующим за ним 6-битовым представлением значения. В общем случае, если значение ошибки предсказания положительно, то код значения – это просто двоичное представление этого значения. Если же значение отрицательно, то код значения представляет собой обратный код соответствующего числа. В результате код отрицательного числа всегда начинается с 0.
Таблица 2 – Значения битовых категорий
| Категория | Числа |
| -1,1 | |
| -3,-2,2,3 | |
| -7,...,-4,4,...7 | |
| -15,...,-8,8,...15 | |
| -31,...-16,16,...31 | |
| -63,...-32,32,...63 | |
| -127,...-64,64,...127 | |
| -255,...-128,128,...255 | |
| -511,...-256,256,...511 | |
| -1023,...-512,512,...1023 | |
| -2047,...-1024,1024,…2047 | |
| -4095,...-2048,2048,…4095 | |
| -8191,...-4096,4096,…8191 | |
| -16383,...-8192,8192,...16383 | |
| -32767,…-16384,16384,..32767 | |
Пример. Пусть a =100, b =191, c =100, X =180. Пусть также y = (a + b) / 2, тогда y = 145 и ошибка предсказания r = 145-180 = -35. Из таблицы 2 следует, что -35 принадлежит категории 6. Двоичный код 35 равен 100011, его обратный код есть 011100, т.е. -35 представляется как (6,011100). Если код Хаффмана для 6 есть 1110, то -35 кодируется 10-битовым кодовым словом 1110011100. В декодере категория (в нашем случае 6) извлекается первой, следующие 6 бит 011100 соответствуют значению ошибки. Так как старший бит равен 0, то значение - отрицательное. После взятия обратного кода получаем r = -35. Числа a, b уже декодированы и известны, таким образом, получаем y = 145и X = y + 35 = 180.
Отметим, что использование битовой категории упрощает код Хаффмана. Без использования категорий нам потребовался бы код для алфавита значительно большего объема, что сильно усложнило бы кодирование и декодирование








