 2014-02-10
2014-02-10 1277
1277Тип char
Элемент данных типа char всегда имеет размер 1 байт (8 бит). Это размер наиболее мелкого адресуемого элемента оперативной памяти (т.е. каждый байт памяти имеет собственный адрес).
В действительности тип char — не что иное, как тип целочисленных данных самого короткого размера (диапазон от 0 до 255 либо от -128 до +127; эти варианты, как и в случае int, можно указать с помощью квалификаторов типа: unsigned char и signed char). Однако на практике этот тип обычно используют для представления символьных данных — букв, цифр, знаков препинания, знаков математических операций, специальных символов вроде $, &, @ и т. д.
Совокупность всех возможных символов образует алфавит. Алфавит — это упорядоченный набор символов, т.е. для каждого символа (кроме, быть может, первого и последнего) известно, какой символ ему предшествует и какой является следующим. Упорядочивая один и тот же набор символов разными способами, мы получим разные алфавиты. Тем более разными будут алфавиты, составленные из различающихся наборов символов.
Если задан алфавит (т.е. набор n символов и способ их упорядочивания), то можно пронумеровать символы по порядку от 0 до n -1. Тогда на любой символ алфавита можно сослаться, указав его порядковый номер. Именно так и представляются символьные данные в компьютере — вместо самих символов хранятся их порядковые номера в алфавите (называемые кодами символов). Коды зависят от конкретного способа упорядочивания символов, или от их кодировки. Если возможны различные кодировки, то для правильной интерпретации символьных данных необходимо знать, какой именно кодировке они соответствуют.
Числовые величины, которые могут содержать дробную часть, в компьютере представляются в виде чисел с плавающей точкой. Такое число хранится в виде двух составных частей — мантиссы и порядка, что соответствует записи:
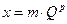
Здесь m — мантисса, p — порядок, Q — основание системы счисления. Порядок всегда является целым числом (положительным или отрицательным). Мантисса — это значащая часть числа, она может быть правильной или смешанной дробью. Машинные числа представляются в двоичной системе, так что для них Q = 2.
Поскольку общий размер памяти, отводимой для хранения одного числа, фиксирован, то значение числа можно представить лишь с ограниченной точностью. Истинное значение округляется до такого числа цифр, которое возможно изобразить при данном размере мантиссы. Поэтому числа с плавающей точкой в большинстве случаев содержат некоторую погрешность, называемую ошибкой округления.
Множество значений для типа с плавающей точкой характеризуется диапазоном (зависящим от диапазона возможных значений порядка) и точностью (зависящей от размера мантиссы).
Большинство процессоров умеют работать по меньшей мере с двумя разновидностями (или форматами) чисел с плавающей точкой, которые различаются по размеру, а следовательно, по диапазону и точности. Поэтому в языке C предусмотрены два базовых типа с плавающей точкой:
float — числа с плавающей точкой обычной точности (4 байта)
double — числа с плавающей точкой удвоенной точности (8 байт)
Указанные здесь размеры являются типичными, но они не обязательно будут такими на любом компьютере. Характеристики этих типов для процессоров x86:
float — 4 байта, 1.175×10-38£ | x | £ 3.403×1038, |D x / x | £ 1.192×10-7
double — 8 байт, 2.225×10-308£ | x | £ 1.797×10308, |D x / x | £ 2.220×10-16
Если в программе понадобятся конкретные значения границ диапазона и относительной точности значений типов float и double, то лучше использовать не приведенные выше величины (которые справедливы для процессоров x86), а стандартные символические константы, определенные в заголовочном файле float.h с помощью #define:
FLT_MIN, FLT_MAX, FLT_EPSILON — для типа float
DBL_MIN, DBL_MAX, DBL_EPSILON — для типа double
Тогда текст программы не будет «привязан» лишь к одной разновидности процессоров.
Так как некоторые процессоры умеют работать более чем с двумя форматами чисел с плавающей точкой (например, бывает «расширенная» или «учетверенная» точность), то в стандарте языка C допускается использование кваличикатора long не только с типом int, но и с double. Будет ли тип long double в самом деле обладать более широким диапазоном и точностью по сравнению с double, зависит от возможностей процессора, а также от решения, принятого разработчиками компилятора. Так, во многих современных компиляторах[2] для процессоров семейства Intel x86 long double не отличается от double, хотя процессор умеет работать с числами расширенной точности размером 10 байт (80 разрядов). Для границ диапазона и точности представления чисел типа long double в заголовочном файле float.h определены стандартные константы LDBL_MIN, LDBL_MAX и LDBL_EPSILON.
[1] В русскоязычной литературе компоновку называют еще сборкой или связыванием. Встречается также термин «редактирование связей».
[2] Исключение составляют компиляторы фирмы Borland.








