2014-02-09
2014-02-09 562
562Р
x~(k) = å api x`(k-i), (8.1)
i=1
где api и Р - коэффициенты и порядок предсказания, когда значение сигнала в k -ый тактовый момент определяется через его восстановленные значения в предыдущие (k –1),..., (k–p) моменты. Выходной сигнал предсказывающего устройства представляет собой взвешенную сумму последних Р отсчетов, каждый из которых в свою очередь является суммой выходных сигналов предсказателя и квантователя. Таким образом, предсказанное значение является выходным сигналом фильтра с передаточной функцией вида P(z) = å ak Z-k, на вход которого поступает восстановленный сигнал x`(k). Здесь символ Z-1 означает задержку на период дискретизации. Так что предсказатель может быть реализован в виде трансверсального фильтра на основе М -отводной линии задержки (регистра сдвига) с временем задержки между отводами, равным периоду временной дискретизации Тд.
Классификационными признаками кодеров ДИКМ считаются наличие блока линейного предсказания и использование многоуровневого (больше двух уровней) квантователя. Блок линейного предсказания может состоять из двух частей — долговременного и кратковременного предсказателей. Если предсказатель хороший, то дисперсия sz2 разности z(k) будет существенно меньше, чем дисперсия sx2 отсчета речевого сигнала x(k), в результате квантователь с заданным шагом (или количеством уровней квантования) даст меньшую погрешность при квантовании разности, чем при квантовании исходного сигнала. Следовательно, шум квантования при подаче на вход квантователя z(k) будет меньше, чем при непосредственном квантовании (в обычной ИКМ). При одинаковом уровне шума число уровней квантования z(k) будет меньше, а длина кодового слова (число разрядов m) и необходимая скорость передачи Rц (7.1) будут снижены.
На приемной стороне из принятого цифрового сигнала аналогичным образом формируется квантованный аппроксимирующий сигнал, который после низкочастотной фильтрации и усиления поступает на выход ТФ канала.
Концепцию ДИКМ можно расширить таким образом, чтобы включить в цепь предсказания значения более чем одного предшествующего отсчета. За счет этого дополнительная избыточность, извлекаемая из всех предшествующих отсчетов, может быть взвешена и суммирована для получения лучшей оценки значения следующего входного отсчета. В связи с улучшенной оценкой диапазон ошибок предсказания уменьшается, что дает возможность кодировать с меньшим числом разрядов. Для систем с постоянными коэффициентами предсказания большая часть реализуемого выигрыша достигается, когда используются значения только трех последних отсчетов.
При анализе систем с ДИКМ и предсказанием первого порядка обычно получается уменьшение длины кодовой комбинации, соответствующей отсчету, на один разряд по сравнению с ее длиной в системах с ИКМ при эквивалентных показателях систем. В системах с ДИКМ с предсказанием третьего порядка может быть реализовано уменьшение на 1,5 - 2 разряда на отсчет. Таким образом, обычная система с ДИКМ может обеспечить то же качество, что и система с ИКМ-64 при скорости передачи 56 кбит/с, а в системе с предсказанием третьего порядка можно получить сопоставимое качество при скорости передачи 48 кбит/с.
Величина отношения сигнал-шум квантования (ОСШК) в такой системе увеличивается (по сравнению с оценкой (7.2) в системе ИКМ) пропорционально уменьшению дисперсии погрешности предсказания. Выигрыш в ОСШК (или коэффициент, характеризующий эффективность предсказания): Gp = sx2 / sz2, где sz2 – дисперсия погрешности предсказания. Квантователь может быть адаптивный или неадаптивный, равномерный или неравномерный. ДИКМ обеспечивает выигрыш Gp @ 6 дБ (в случае неадаптивного равномерного квантования РС с частотой дискретизации 8 кГц) по сравнению с прямым квантованием (т.е. ИКМ).
Как и в системах с ИКМ, процесс АЦП в ДИКМ может осуществляться с компандированием, а также может использоваться техника адаптации для подстройки размеров шагов квантования в соответствии с уровнем средней мощности сигнала. Эти способы адаптации называют слоговым компандированием в соответствии с интервалом времени между подстройками усиления.
Дельта-модуляция (ДМ) считается частным случаем ДИКМ-кодирования. В методе ДМ вычисляется разница между текущим и предыдущим отсчетами. Затем эта разница подвергается квантованию в одноразрядном (двухуровневом) квантователе. Этот единственный разряд просто показывает полярность отсчета разностного сигнала и посредством этого указывает на то, увеличился или уменьшился сигнал за время, прошедшее после последнего отсчета. За упрощение схемы кодирования приходится платить необходимостью увеличения частоты дискретизации по сравнению с минимально возможной частотой дискретизации, используемой в ИКМ-кодере. В простейшем ДМ-кодере частота дискретизации представляет собой компромисс между скоростью выходного потока данных и приемлемым уровнем ошибок квантования. Наиболее значительные ошибки дискретизации сигнала вызываются двумя явлениями - перегрузкой по крутизне и шумом дробления. Суть первого явления заключается в том, что при кодировании быстро изменяющегося сигнала возникают ошибки, обусловленные невозможностью изменения аппроксимирующего сигнала более чем на один шаг квантования.
В простейшем случае линейной ДМ-квантователь имеет только два уровня (+ D и – D) и фиксированный шаг квантования, а предсказатель представляет собой цифровое интегрирующее устройство, в котором сигнал x`(k) задерживается на время dt и умножается на коэффициент a, где 0 < a £ 1. На выходе интегратора образуется ступенчатое напряжение, крутизна которого не может превышать значение Fд D = D/dt, при котором кодированный сигнал отстоит от входного сигнала не более, чем на размер шага. Если дельта-модулятор не в состоянии отслеживать быстрые изменения во входном сигнале, то возникает "отставание" восстановленного сигнала от исходного (рис. 8.2), характеризуемое как искажение перегрузки по крутизне.
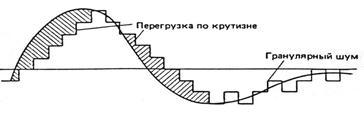
Рис. 8.2. Искажение перегрузки по крутизне при дельта-модуляции
Фактически, ДМ-кодер не успевает отслеживать быстрые изменения уровня сигнала и генерирует линейно изменяющийся квантованный сигнал. Шум дробления или гранулярный шум возникает при квантовании квазистационарного сигнала. При ДМ-кодировании постоянного сигнала результат представляет собой неравномерно чередующиеся положительные и отрицательные двоичные импульсы. Как показано на рис. 8.2, для медленно меняющихся сигналов основное значение имеет гранулярный шум, в то время как для быстро меняющихся сигналов - шум перегрузки по крутизне. Последний достигает пиковых значений непосредственно перед тем, как достигает максимумов кодируемый сигнал. Поэтому шум перегрузки по крутизне эффективно маскируется энергией речи, вследствие чего он менее заметен, чем шумы дробления.
Перегрузка по крутизне является не только ограничивающим фактором для системы с дельта-модуляцией, но и проблемой, присущей любой системе, когда кодируется разность значений соседних отсчетов. Система, оперирующая разностью, кодирует крутизну входного сигнала конечным числом разрядов и имеет, следовательно, конечный диапазон. Если крутизна превышает этот диапазон, происходит перегрузка по крутизне. В противоположность этому в обычной системе с ИКМ ограничена не скорость изменения входного сигнала, а максимальная кодируемая амплитуда. А дифференциальная система может кодировать сигналы с произвольно большими амплитудами, лишь бы эти большие амплитуды достигались постепенно.
Расчеты ОСШК при дельта-модуляции показывают, что последняя уступает ИКМ при больших скоростях передачи и превосходит ее при скоростях около 40 кбит/с. Так, для получения ОСШК, равного 35 дБ при частоте Найквиста (т.е. Fв) 3 кГц, требуется скорость передачи 200 кбит/с. Для улучшения эффективности ДМ применяют адаптацию - изменение шага D в соответствии с нестационарными свойствами сигнала и прежде всего - в зависимости от усредненного за короткое время значения крутизны входного сигнала.
Системы с ДИКМ обеспечивают такое качество восстановления сигнала, которое сопоставимо с качеством ИКМ-кодирования, и на порядок более высокую помехоустойчивость. Для снижения погрешности передачи при ДИКМ и повышения эффективности ДМ параметры квантователя и предсказателя должны быть согласованы со статистическими характеристиками сигнала, а поскольку последние изменяются во времени - алгоритмы должны быть адаптивными.
9. Адаптивные методы кодирования формы речевого сигнала
Неадаптивное построение систем с дифференциальной ИКМ, когда предсказатель и квантователь рассчитаны на средние статистические характеристики речи, недостаточно эффективно (см. материал разд.8). Это обусловлено тем, что для сообщений, содержащих долговременную избыточность, кратковременный предсказатель не обеспечивает существенного уменьшения динамического диапазона входного сигнала квантователя, что является причиной значительных искажений. Эффективность метода ДИКМ может быть повышена путем перехода к адаптивной дифференциальной импульсно-кодовой модуляции (АДИКМ). При этом производится автоматическое регулирование величины шага квантования сигнала ошибки предсказания, а также автоматическая подстройка коэффициентов ci трансверсального фильтра устройства предсказания (рис. 9.1) в соответствии с изменением текущего спектра сообщения. Для этого 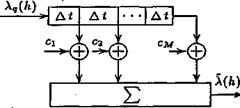 как в передающее, так и в приемное устройства вводятся дополнительные цепи автоматической регулировки усиления и подстройки параметров предсказателя на основе статистического оценивания параметров передаваемого сообщения.
как в передающее, так и в приемное устройства вводятся дополнительные цепи автоматической регулировки усиления и подстройки параметров предсказателя на основе статистического оценивания параметров передаваемого сообщения.
Рис. 9.1. Структурная схема трансверсального фильтра устройства предсказания
Амплитуда речевого сигнала (РС) может изменяться в широких пределах в зависимости от диктора, условий передачи, а также внутри фразы при переходе от вокализованного к невокализованному сегменту. Один из методов учета этих флуктуаций состоит в адаптации свойств квантователя к уровню входного сигнала. Учесть нестационарный характер РС, в частности медленное изменение его мощности (дисперсии), позволяет адаптивный квантователь.
Основная идея адаптивного квантования состоит в том, что шаг квантования изменяется таким образом, чтобы соответствовать изменяющейся дисперсии кодируемого сигнала. В результате размеры шкалы квантования подстраивают в соответствии с энергией речи так, чтобы слабые сигналы квантовались малыми ступенями квантования, а сильные сигналы - большими. Благодаря непрерывной подстройке шага квантования к текущей мощности речи, разрядность шкалы квантования при АДИКМ удалось снизить до четырех бит.
Адаптивная дифференциальная ИКМ была стандартизирована в 1984 г. (Рек. ITU-T G. 721) для скорости передачи речи 32 кбит/с, и включает в себя два метода обработки сигнала: дифференциальное кодирование с предсказанием и адаптивное квантование(рис. 9.2).

Рис. 9.2. Схема кодирования речи по Рек. ITU-T G. 721
Аналоговый сигнал дискретизируется и линейно обрабатывается в 12-битном (b = 12) квантователе. На следующем этапе вычисляется ошибка предсказания как разность между реальным и предсказанным значениями сигнала. Представленный 12-битным словом разностный сигнал обрабатывается в квантователе, имеющим логарифмическую (по основанию 2) характеристику и 16 порогов квантования (b = 4). В результате формируется 4-битовое представление ошибки отсчета, что при частоте дискретизации 8 кГц обеспечивает скорость цифрового потока на выходе кодера АДИКМ равной 32 кбит/с. 4-битовый разностный сигнал на основе статистического оценивания его параметров позволяет определить коэффициенты предсказания, используемые как в адаптивном квантователе, так и в схеме адаптивного предсказания. Кроме того, квантованная ошибка добавляется к сигналу, снимаемому с выхода адаптивного предсказателя, и направляется на его вход.
Оценка дисперсии может осуществляться в результате анализа либо входного, либо выходного сигнала квантователя. Соответственно имеем прямое и обратное управление квантованием, что отражается в обозначении метода: АДИКМ-П (АДИКМ с прямой адаптацией) и АДИКМ-О (АДИКМ с обратной адаптацией). В первом случае адаптивное квантование основано непосредственно на знании характеристик входного сигнала (прямая оценка), а во втором - информация для адаптации квантователя извлекается из передаваемого цифрового потока (задержанная оценка). Когда используется прямая оценка, коэффициент усиления квантователя кодируется в явной форме и передается совместно с коэффициентами предсказания и результатами кодирования разностных сигналов.
В дифференциальных кодеках формируется аппроксимирующее напряжение, сравниваемое с передаваемым сигналом. Процедура предсказания может быть фиксированной и адаптивной. Фиксированное предсказание (ФП) характеризуется постоянными параметрами предсказывающего фильтра с передаточной функцией
Р
P(z) = å bpiz-i. (9.1)
i=1
Здесь z-i - оператор задержки на i интервалов дискретизации, а bpi и Р - коэффициенты и порядок предсказания, которые выбираются исходя из свойств долговременной корреляционной функции РС. Наибольшее распространение при дифференциальном кодировании получило линейное предсказание, при котором предсказанное значение сигнала формируется как линейная комбинация предыдущих отсчетов на анализируемом сегменте РС длительностью 20...30 мс.
Адаптивное предсказание (АП), реализующее адаптацию коэффициентов предсказателя bpi(k) (9.1), основано на слежении за изменением кратковременной дисперсии РС. В этом случае оценивается кратковременная корреляционная функция речевого сигнала в предположении его локальной стационарности, т.е. предполагается, что свойства РС не меняются в течение короткого интервала времени. Другими словами, коэффициенты предсказания выбираются так, чтобы минимизировать средний квадрат погрешности предсказания на коротком интервале времени. Параметры адаптивного предсказателя определяются в результате анализа (измерений) либо исходного РС (АП-П), либо квантованного (выходного) сигнала (АП-О). Адаптивное квантование может быть основано на оценке огибающей или структуры кратковременной спектральной плотности мощности речевого сигнала. В первом случае существенна в основном частотная характеристика голосового тракта, а во втором - период основного тона речи.
Структурная схема кодека АДИКМ-АП-П первого типа приведена на рис. 9.3. Она содержит адаптивно управляемые АЦП (на стороне передачи) и ЦАП (на приемной стороне) и отличается от схемы на рис. 8.1 наличием блока адаптации, реализующего алгоритмы адаптации квантователя (Q) и предсказателя (P). Предсказывающий фильтр вместе с сумматором, на второй вход которого подается выходной сигнал адаптивного АЦП, образует оценивающий фильтр с передаточной функцией H(z) = 1 / [1 – P(z) ]. В таких системах на приемную сторону передаются: 1 - результаты кодирования разностных сигналов; 2 - параметры квантователя (коэффициент усиления); 3 - коэффициенты предсказания. Для передачи параметров 2 и 3 предусматривается дополнительный низкоскоростной канал связи (2...3 бит/с).
Для преобразования ошибки (остатка) предсказания z(k) в цифровую форму обычно используют симметричные квантователи с постоянным числом уровней квантования и переменным шагом квантования Di, где i - дискретное время. Процесс адаптации заключается в изменении шага квантования в соответствии с алгоритмом адаптации. Известны различные алгоритмы адаптации квантователей. Один из них - "мгновенно адаптирующийся квантователь" или "квантователь с памятью на одно слово". В этом случае размер шага квантования вычисляется согласно алгоритму Di+1 = Di M(i), где M - множитель, зависящий от номера уровня квантования (т.е. от абсолютной величины отсчета), переданного в момент i.
Алгоритмы адаптации при АДИКМ построены так, что при обнаружении ошибок передачи в кодированном двоичном сигнале происходит восстановление работы, не приводящее к сбою. При отсутствии ошибок в канале системы АДИКМ-П и АДИКМ-О имеют приблизительно одинаковые характеристики. Адаптивное квантование может обеспечить выигрыш около 5 дБ по сравнению со стандартной неадаптивной ИКМ-МК. С учетом дополнительного выигрыша в величине ОСШК приблизительно 6 дБ за счет применения дифференциальной (разностной) схемы с неадаптивным квантованием, можно заключить, что системы АДИКМ-П и АДИКМ-О позволят получить ОСШК на 10...11 дБ больше, чем при использовании неадаптивного квантователя с тем же числом уровней.
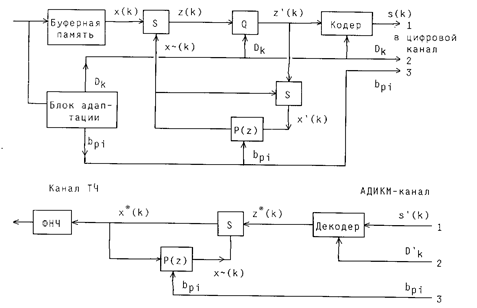
Рис. 9.3. Структурная схема системы АДИКМ-АП-П первого типа
В кодеке АДИКМ-АП-О с обратной адаптацией коэффициенты адаптивного предсказания формируются в результате анализа цифрового сигнала. В этом случае оценивается кратковременная дисперсия сжатого сигнала - с выхода кодера на передающей стороне и с входа декодера на приемной стороне. Поэтому передавать параметры предсказателя и квантователя на приемную сторону нет необходимости. По тракту связи передается только квантованная ошибка предсказания. Поскольку коэффициенты предсказания изменяются от отсчета к отсчету, то задержка РС значительно меньше, чем в случае предсказания с прямым управлением.
Дельта-модуляцию с адаптивным квантователем называют адаптивной ДМ (АДМ). Она является частным случаем АДИКМ с фиксированным предсказателем первого порядка и адаптивным квантователем с двумя уровнями квантования и обратной адаптацией. Это означает, что информация для определения текущего значения шага квантования Di определяется непосредственно по выходной последовательности кодовых слов.
В системах АДМ важным моментом является выбор алгоритма адаптации квантователя (т.е. шага квантования). По скорости адаптации системы с АДМ подразделяются на системы с мгновенным компандированием (АДМ-МК) и системы со слоговым компандированием (АДМ-СК). В системах АДМ-МК часто применяется алгоритм адаптации Джаянта, когда шаг квантования подчиняется следующему правилу:
D(k) = M ´ D(k–1); Dmin £ D(k) £ Dmax.
В этом случае множитель М является функцией текущего s(k) и предшествующего s(k–1) кодовых слов. Алгоритм выбора множителя М шага квантования имеет вид
M = p > 1, s(k) = s(k–1); ü
M = 1/p < 1, s(k) ¹ s(k–1). þ
Кодовое слово s(k) зависит только от знака z(k), который задается соотношением z(k) = x(k) – ax`(k–1), что соответствует использованию предсказателя первого порядка, описываемого разностным уравнением x~(k) = ax`(k–1). Здесь a - коэффициент предсказания.
Процедура AДИКМ применена также в международном стандарте кодирования речевых сигналов с частотой дискретизации 8 кГц для передачи по каналам со скоростью 16, 24, 32 и 40 кбит/с (Рек. ITU-T G. 726). Этот метод кодирования сигнала применяется в некоторых распространенных системах подвижной связи, в частности, в бесшнуровой телефонии и системах абонентского доступа. Субъективно качество речи в результате АДИКМ-кодирования мало отличается от обычной обработки сигнала в системе ИКМ.
10. Основы параметрического кодирования речи
Как отмечалось ранее, при кодировании формы сигнала практически не учитываются свойства артикуляционного аппарата человека и особенности его слухового восприятия. В то же время именно здесь заключен значительный ресурс избыточности речевого сигнала (РС). На использовании этого ресурса избыточности основывается широко распространенное параметрическое представление речевого сигнала.Параметрическое представление РС основывается в первую очередь на данных о механизмах речеобразования, т.е. используется своего рода модель голосового тракта, что привело к разработке систем типа анализ-синтез, получившим название вокодерных систем или вокодеров (сокращение от voice coder). Описание первого вокодера было опубликовано Г. Дадли более 60 лет назад. Восстановленная речь была достаточно разборчивой, но звучала ненатурально. Значительного улучшения качества передаваемой речи удалось достичь только с появлением методов, основанных на линейном предсказании (LPC). Именно вокодерные методы на основе линейного предсказания и применяются в сотовой связи.
Линейное предсказание (ЛП) является одним из наиболее эффективных методов анализа речевого сигнала. Этот метод становится доминирующим при оценке основных параметров РС, таких, как период основного тона, форманты, спектр, а также при сокращенном представлении речи с целью ее низкоскоростной передачи и экономного хранения. Важность метода обусловлена высокой точностью получаемых оценок и простотой вычислений.
Основной принцип линейного предсказания состоит в том, что текущий отсчет РС можно аппроксимировать линейной комбинацией предшествующих отсчетов, а именно, очередная k -я выборка РС S(k) может быть приблизительно предсказана путем суммирования с определенным весом некоторого числа предшествующих выборок сигнала:
P
Ś(k) = å api S(k-i), (10.1)
i =1
где - Ś(k) - предсказанное значение РС; k – номер временн о го отсчета; api - коэффициенты линейного предсказания; Р - порядок предсказания (число коэффициентов линейного предсказания).
При анализе и синтезе речи используется модель речеобразования, представленная на рис. 10.1. Параметры модели обычно разделяются на параметры возбуждения (относящиеся к источнику звуков речи и отвечающие за основной тон, т.е. за возбуждение фильтра) и параметры голосового тракта (относящиеся непосредственно к отдельным звукам речи и определяющие формантную структуру сигнала). А отрезки глухой речи при моделировании заменяют шумом.
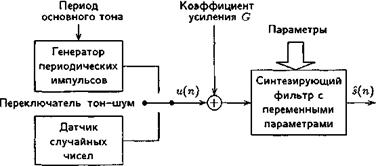
Рис. 10.1. Модель речеобразования, используемая в методе линейного предсказания
В соответствии с таким подходом, компрессия РС осущест-вляется на передающем конце канала в анализаторе, выделяющем из сигнала сравнительно медленно меняющиеся параметры выбранной модели. Затем эти параметры передаются по каналу связи. На приемном конце с помощью местных источников сигналов, управляемых принятыми параметрами (в соответствие с моделью), синтезируется речевой сигнал. При этом синтез речи осуществляется согласно разностному уравнению
P
Ŝ(k) = å api Ŝ(k-i) + Gu(n), (10.2)
i =1
где - Ŝ(k) - синтезированное значение речевого сигнала; и(п) - либо периодическая последовательность импульсов, следующих с периодом основного тона в случае синтеза вокализованных сегментов, либо случайная последовательность импульсов для синтеза невокализованных сегментов; Р - порядок синтезирующего фильтра; api - коэффициенты линейного предсказания, используемые в качестве параметров синтезирующего фильтра; G - коэффициент усиления, регулирующий интенсивность сигнала возбуждения для получения речевого сигнала заданной громкости. Коэффициенты линейного предсказания определяются однозначно минимизацией среднего квадрата разности между отсчетами РС и их предсказанными значениями на некотором конечном интервале. Коэффициенты линейного предсказания - это весовые коэффициенты, используемые в линейной комбинации.
Вокодеры на основе линейного предсказания обеспечивают высокую разборчивость передаваемой речи и иногда вполне удовлетворительную натуральность ее звучания. Одним из основных факторов, определяющих качество речи в этих вокодерах, является выделение основного тона речи и других параметров возбуждения в классической модели голосового аппарата. Для адекватного “отражения” этими параметрами модели постоянно изменяющегося РС, последний разбивается на сегменты по 20 ÷ 30 мс (длительность выбрана исходя из периода локальной стационарности РС), на каждом из которых и происходит описанная выше процедура. Характерной чертой вокодерных систем (по сравнению с кодеками формы сигнала) является то, что они производят все операции анализа, кодирования, декодирования сразу для целого сегмента отсчетов, а не для каждого отсчета в отдельности, как в ДИКМ и АДИКМ.
Таким образом, в процессе параметрического представления РС в кодере источника определяются коэффициенты предсказания, а в декодере на основе этих коэффициентов с помощью рекурсивного цифрового фильтра синтезируется эквивалент голосового тракта. Посредством возбуждения этого “эквивалента тракта” формируется синтезированная речь.
Разность между истинным (известным точно) S(k) и предсказанным Ś(k) значениями выборки определяет ошибку предсказания, которую также называют остатком предсказания или первым остаточным сигналом r1(k):
z(k) = r1(k) = S(k) - Ś(k). (10.3)
На базе линейного предсказателя в системе кодер/декодер строятся два цифровых фильтра: инверсный (обратный) фильтр-анализатор A(z) и формирующий фильтр-синтезатор H(z).
В результате z-преобразования разностного уравнения (10.3) имеем
R(z) = X(z) ´ A(z), (10.4)
где X(z) – z-преобразование выборки РС S(k) на входе фильтра-анализатора, а R(z) может интерпретироваться как выходной сигнал этого фильтра, имеющего передаточную функцию
p
A(z) = 1 - å api z-i = 1 - P(z). (10.5)
i=1
Здесь z-1 соответствует задержке РС на одну выборку; P(z) – коэффициент передачи предсказывающего устройства – предиктора.
Цифровой фильтр-анализатор A(z) – рис. 10.2 - называют инверсным, поскольку АЧХ такого фильтра должна быть обратной частотной характеристике голосового тракта (следовательно, обратной и огибающей спектра входного сигнала). Значения коэффициентов предсказания api являются параметрами этого фильтра. Они остаются постоянными на интервале анализируемого сегмента речи (как правило, 20 мс), поскольку линейный предсказатель перенастраивается (т.е. адаптируется) не под каждый речевой отсчет, а под их последовательность, вследствие чего ошибка минимизируется на протяжении всего сегмента.

Рис. 10.2. Инверсный фильтр-анализатор A(z)
Инверсный фильтр применяется в кодере для устранения избыточности РС. Пропуская через него исходный РС, на выходе фильтра получаем сигнал остатка предсказания z(k) (иначе - первый остаточный сигнал - r1(k)). В этом “остатке” устранены внутренние корреляционные связи, он имеет спектр с плоской огибающей.
Коэффициенты предсказания api можно подобрать таким образом, чтобы ошибка z(k) была минимальной. Чаще всего в качестве критерия используется минимум среднеквадратической ошибки. В этом случае требуется определить такие значения api, чтобы величина
p
å z 2 (k)
k=1
была минимальной.
При подаче речевого сигнала на вход фильтра-анализатора с оптимально подобранными параметрами его выходной сигнал будет представлять собой сигнал возбуждения R(z), подобный (с точностью до ошибок, определяемых конечностью порядка предсказания Р и погрешностью оценки коэффициентов предсказания) сигналу возбуждения u(k) на входе фильтра голосового тракта на рис. 10.1. На выходе этого фильтра остается только периодическая составляющая РС, соответствующая основному тону. Это модель фильтра - анализатора РС, описываемая уравнением (10.5).
Синтезирующий фильтр выполняет противоположные функции. Он находится в декодере и осуществляет формирование речевого сигнала с заданной огибающей спектра. “Нужная“ настройка этого фильтра в декодере обеспечивается передачей на приемную сторону коэффициентов предсказателя, используемых в этот момент в кодере. Подаваемый на вход синтезирующего фильтра сигнал называется “сигналом возбуждения” R(z). Является очевидным, что он должен быть максимально “похож” на сигнал остатка предсказания, полученный в кодере. Из выражения (10.4) можно получить модель фильтра-синтезатора, который находится в декодере (рис. 10.3)