2014-02-12
2014-02-12 2404
2404Низкая расширяемость
Особенности CC-NUMA ( Cache Coherent Non-Uniform Memory Architecture )
1) Наличие кэша у процессоров.
2) Совместимость кэшей на программном или аппаратном уровне.
Способы обеспечения совместимости кешей:
A. Отслеживание системной шины (низкая масштабируемость, простота технической реализации)
B. Использование каталога (хранение БД кэш-строк в высокоскоростном специализированном аппаратном обеспечении)
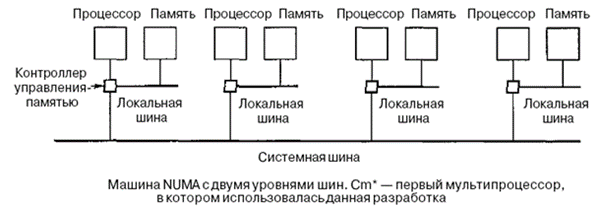
Мультипроцессор Sun Enterprise 10000
1) Архитектура UMA из одного корпуса с 64 процессорами.
2) Координатный коммутатор Gigaplahe-XB 16х16запакован в плату, содержащую 8 гнезд с двух сторон.
3) Каждое гнездо вмещает огромную плату процессора (40x50 см), содержащую 4 процессора UltraSPARC на 333 МГц и ОЗУ на 4 Гбайт.
4) Жесткие требования к синхронизации и малое время ожидания.
5) Доступ к памяти вне платы занимает столько же времени, что и доступ к памяти на плате.
6) Длина строки кэш-памяти составляет 64 байта, а ширина канала связи составляет 16 байтов, поэтому для перемещения строки кэш-памяти требуется 4 цикла.
7) Помимо координатного коммутатора имеются 4 адресные шины, которые используются для отслеживания строк в кэш-памяти. Каждая шина используется для 1/4 физического адресного пространства.
Для выбора шины используется два адресных бита. В случае промаха кэш-памяти при считывании процессор должен считывать нужную ему информацию из основной памяти, и тогда он обращается к соответствующей адресной шине, чтобы узнать, нет ли нужной строки в других блоках кэш-памяти. Все 16 плат отслеживают все адресные шины одновременно, поэтому если ответа нет, это значит, что требуемая строка отсутствует в кэш-памяти и ее нужно вызывать из основной памяти.
Enterprise 10000 использует 4 отслеживающие шины параллельно, плюс очень широкий координатный коммутатор для передачи данных. Ясно, что такая система преодолевает предел в 64 процессора.
Литература:
Таненбаум, Э. Архитектура компьютера/ Э. Таненбаум. – СПб.: Питер, 2007. – 848 с.
Лекция 10. Векторные и векторно-конвейерные вычислительные системы
Область применения векторно-конвейерных ВС – задачи моделирования реальных процессов и объектов, для которых характерна обработка больших регулярных массивов чисел в форме с плавающей запятой. Такие массивы представляются матрицами и векторами, а алгоритмы их обработки описываются в терминах матричных операций.
Для обработки массивов требуются вычислительные средства, позволяющие с помощью единой команды производить действие сразу над всеми элементами массивов - средства векторной обработки.
Понятие вектора и размещение данных в памяти
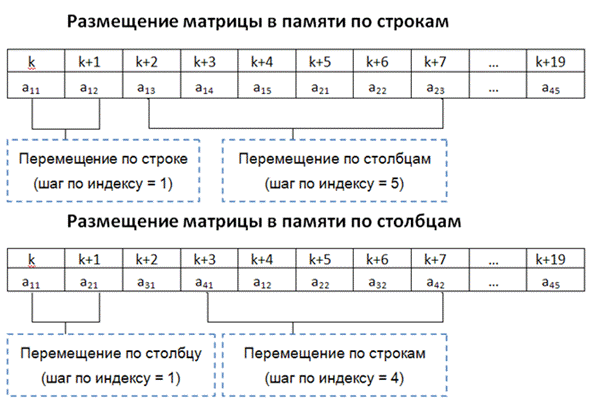
В средствах векторной обработки под вектором понимается одномерный массив однотипных данных (обычно в форме с плавающей запятой), регулярным образом размещенных в памяти ВС. Если обработке подвергаются многомерные массивы, их также рассматривают как векторы. Такой подход допустим, если учесть, каким образом многомерные массивы хранятся в памяти ВМ. Пусть имеется массив данных A, представляющий собой прямоугольную матрицу размерности 4x5.
| a11 | a12 | a13 | a14 | a15 |
| a21 | a22 | a23 | a24 | a24 |
| a31 | a32 | a33 | a34 | a35 |
| a41 | a42 | a43 | a44 | a45 |
При размещении матрицы в памяти все ее элементы заносятся в ячейки с последовательными адресами, причем данные могут быть записаны строка за строкой или столбец за столбцом. С учетом такого размещения многомерных массивов в памяти вполне допустимо рассматривать их как векторы и ориентировать соответствующие вычислительные средства на обработку одномерных массивов данных (векторов).
Характеристики вектора:
· Шаг по индексу (stride)
· Длина
Понятие векторного процессора
Векторный процессор — это процессор, в котором операндами некоторых команд могут выступать упорядоченные массивы данных — векторы. Векторный процессор может быть реализован в двух вариантах:
1. дополнительный блок к универсальной ВС.
2. основа самостоятельной ВС.
Рассмотрим возможные подходы к архитектуре средств векторной обработки. Наиболее распространенные из них сводятся к трем группам:
· конвейерное АЛУ;
· массив АЛУ;
· массив процессорных элементов.
Последний вариант - один из случаев многопроцессорной системы, известной как матричная ВС. Понятие векторного процессора имеет отношение к двум первым группам, причем, как правило, к первой.
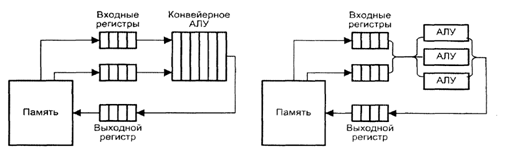
В варианте с конвейерным АЛУ (слева) обработка элементов векторов производится конвейерным АЛУ для чисел с плавающей запятой (ПЗ). Операции с числами в форме с ПЗ достаточно сложны, но поддаются разбиению на отдельные шаги. Так, сложение двух чисел может быть сведено к четырем этапам:
1. сравнению порядков,
2. сдвигу мантиссы меньшего из чисел,
3. сложению мантисс
4. нормализации результата.
Каждый этап может быть реализован с помощью отдельной ступени конвейерного АЛУ. Очередной элемент вектора подается на вход конвейера, как только освобождается первая ступень. Ясно, что такой вариант вполне годится для обработки векторов.
Одновременные операции над элементами векторов можно проводить и с помощью нескольких параллельно используемых АЛУ, каждое из которых отвечает за одну пару элементов.
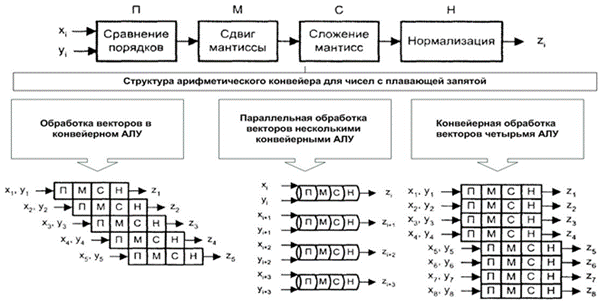
Если параллельно используются конвейерные АЛУ, то возможен еще один уровень конвейеризации. Вычислительные системы, где реализована эта идея, называют векторно-конвейерными. Коммерческие векторно-конвейерные ВС, в состав которых для обеспечения универсальности включен также скалярный процессор, известны как суперЭВМ.
PVP-система
Вычислительная система на векторно-конвейерных процессорах, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Обычно несколько таких процессоров работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций.
Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
1. CRAY X1, SMP -архитектура. Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
2. NEC SX-6, NUMA -архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP -архитектура. Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт.
Структура векторного процессора
Обобщенная структура векторного процессора приведена на рис. На схеме показаны основные узлы процессора, без детализации некоторых связей между ними.