 2015-01-21
2015-01-21 898
898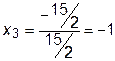 ,
,
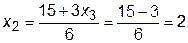 ,
,
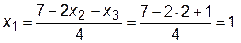 .
.
Проверка решения производится подстановкой корней в исходные уравнения системы:
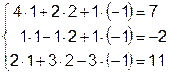 .
.
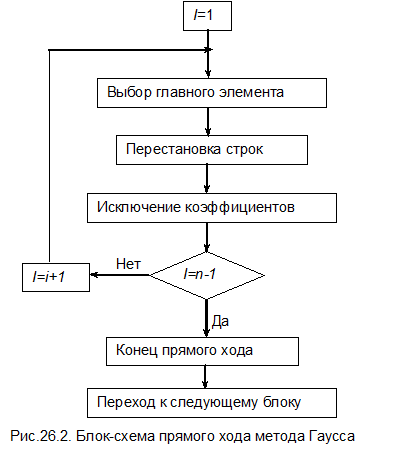
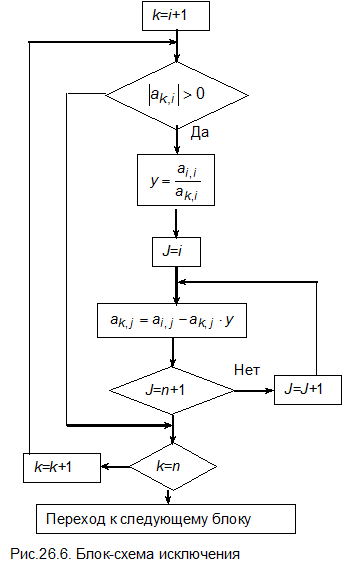
В общем случае метод Гаусса состоит из двух частей:
1) прямого хода, в результате которого исходная матрица преобразуется к верхнему треугольному виду;
2) обратного хода, в котором подстановкой определяются корни уравнения.
Запишем общие формулы для расчета.
Элементы матрицы ai,I, в которых индексы строк совпадают с индексами столбцов, называются элементами главной диагонали.
Пусть при прямом ходе были исключены коэффициенты из i- 1 столбцов. На этом этапе матрица коэффициентов имеет вид
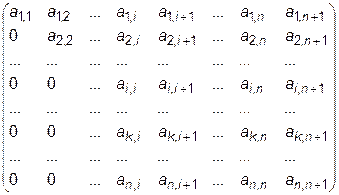
Теперь необходимо преобразовать матрицу таким образом, чтобы в i -том столбце элементы ниже главной диагонали с индексами i,k стали равными нулю. Здесь параметр k изменяется от k=i +1 до k = n. Сначала умножим каждый элемент k -той строки на величину  , а затем вычтем из соответствующего элемента
, а затем вычтем из соответствующего элемента
i -той строки. Элемент матрицы в j -том столбце получит новое значение
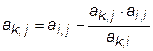 .
.
Параметр j должен изменяться от j=i до j=n+ 1.
Выполняя подобную процедуру от i =1 до i=n -1, получим верхнюю треугольную матрицу, в которой все элементы ниже главной диагонали будут равны нулю.
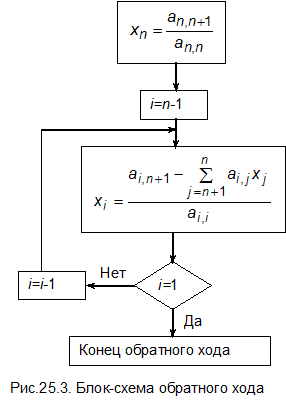
Неизвестный параметр xn находится непосредственно
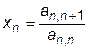 ,
,
а остальные неизвестные определяются при обратном ходе по формуле
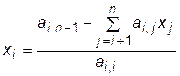 .
.
Лекция 26. ВЫБОР ГЛАВНОГО ЭЛЕМЕНТА.
ОБЕСПЕЧЕНИЕ УСТОЙЧИВОСТИ РАБОТЫ АЛГОРИТМА
При разработке программы для решения системы уравнений необходимо учесть следующие факторы:
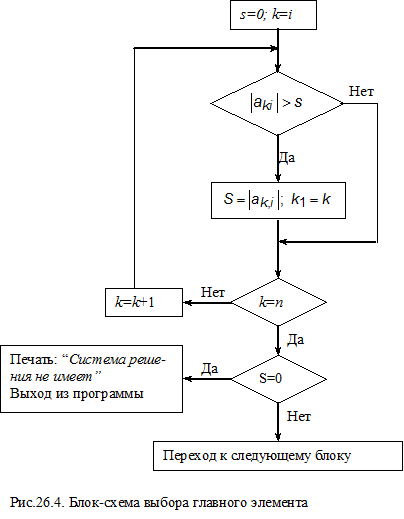
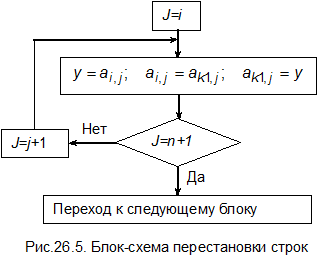
1. Исключение коэффициентов по указанной схеме нельзя производить, если на главной диагонали оказался нулевой коэффициент, т.е. ai,i =0. Если система имеет решение, то в i -том столбце должен быть хотя бы один коэффициент, отличный от нуля. Поэтому перестановкой строк сначала надо на главную диагональ переместить ненулевой коэффициент.
2. Если элемент на главной диагонали мал по абсолютной величине, то операции исключения коэффициентов при прямом коде и вычисления корней при обратном ходе могут привести к появлению значительных погрешностей за счет потери значащих цифр при округлении. Чтобы этого избежать, каждый цикл прямого хода начинают с выбора главного элемента. Среди элементов i- того столбца, начиная с i -той строки и до строки с номером n, находят главный элемент, т.е. коэффициент, имеющий наибольшее по абсолютной величине значение. Затем перестановкой строк переводят этот элемент на главную диагональ и только после этого проводят исключение коэффициентов столбца.
Погрешность округления можно еще уменьшить, если в каждом цикле выбирать главный элемент не в столбце, а во всей матрице. Однако, точность метода возрастет не значительно по сравнению с выбором главного элемента в столбце, но при этом расчет заметно усложнится, т.к. потребует также перестановки столбцов. Этот метод применяется только при специальных расчетах, обычно ограничиваются выбором главного элемента столбца.
3. Случай, когда при выборе главного элемента в столбце не будет обнаружен ненулевой коэффициент, означает, что система не имеет единственного решения. Эту ситуацию можно предусмотреть заранее, вычислив определитель системы до начала расчета. Однако, трудоемкость вычисления определителя сопоставима с решением системы методом Гаусса. Поэтому обычно эта проверка не проводится, а при выявлении несовместимости решения системы в ходе расчета в программе следует предусмотреть ее останов и вывод информации на экран.
4. Если подлежащий исключению коэффициент уже равен нулю, то необходимо обойти эту строку, не применяя операцию деления на нуль.
Метод Гаусса с выбором главного элемента надежен, прост и наиболее выгоден для линейных систем общего вида с плотно заполненной матрицей. Здесь нет серьезных ограничений на размерность системы до величины n <200.
Общая блок-схема метода Гаусса и блок-схемы отдельных этапов приведены на рис.26.1-26.6.
 |
 |
 |
 |
 |
 |
Лекция 27. Интерполяция
Инженеру часто приходится работать с таблицами, в которых приводятся значения некоторой функции f (x) в зависимости от фиксированных значений одного или двух параметров. Табличное представление функции может быть связано с тем, что данные получены экспериментально и лишь для некоторых дискретных значений аргумента, либо с тем, что объем таблиц ограничен и в них можно привести лишь некоторые данные. Хотя частота узлов таблицы может быть достаточно малой, тем не менее в практических расчетах требуется использовать значения функции, для которых аргумент находится между узлами. Операция определения промежуточного значения функции внутри интервала по ее значениям на границах интервала называется интерполяцией.
При интерполяции табличные значения функции f (x) аппроксимируются приближенной функцией j(х,а), которая совпадает с f (x) по крайней мере в двух ближайших узлах таблицы и легко вычисляется. В дальнейшем при всех значениях аргумента искомое значение функции f (x) определяют вычислением значений j(х, а). Близость функций f (х) и j(х,а) обеспечивают введением в аппроксимирующую функцию свободных параметров а (а1,а2,…аn) и соответствующим их выбором.
Если потребовать, чтобы функция j(х,а) совпадала в n выбранных узлах таблицы с f (x), то получим систему уравнений
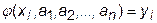 , 1 £ i £ n,
, 1 £ i £ n,
из которой можно определить параметры ai. Если j(х,а) линейно зависит от параметров ai, то такая интерполяция называется линейной.
На практике чаще всего для интерполяции используются следующие функции:
Ø последовательность степеней x:
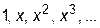 , то есть интерполяционный многочлен
, то есть интерполяционный многочлен  ;
;
Ø последовательность тригонометрических функций: 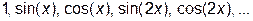 ;
;
Ø последовательность показательных функций:
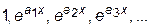 .
.
Увеличение количества узлов таблицы, по которым проводится интерполяция, формально увеличивает близость функций f (х) и j(х,а) на всем пространстве изменения аргумента. Задавая порядок интерполирования равный количеству всех узлов таблицы, получим полное совпадение значений функций f (х) и j(х,а) во всех узлах. Однако при этом вследствие погрешности эксперимента или погрешности округлений табличных значений функции в пространстве между узлами могут появиться выбеги значений функции j (х,а), существенно отличающиеся от значений в близлежащих узлах.
К интерполированию приходится прибегать и в том случае, когда для функции f (x) известно ее аналитическое представление или существует способ вычисления значения функции для любого значения х из отрезка [ a,b ], но вычисления каждого значения сопряжено со значительными затруднениями. В таких условиях вычисляют несколько значений f (xi) и по ним строят интерполирующую функцию j(х,а), а затем с помощью ее вычисляют приближенные значения f (x) в остальных точках.
Однопараметрическая интерполяция.
Рассмотрим случай, когда функция f (х) зависит только от одного параметра x. Например, имеем таблицу данных
| X | ¥ | |||||||||
| Y | 0,16 | 0,22 | 0,27 | 0,29 | 0,31 | 0,32 | 0,36 | 0,40 | 0,48 |
Независимо от того, проводим ли вычисления вручную или составляем программу для компьютера, необходимо разработать метод для определения значений y в зависимости от произвольного значения x, например для х =2,33.
Возьмем для аппроксимации степенной многочлен, причем запишем в виде
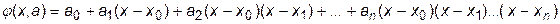 .
.
Если ограничиться линейной интерполяцией по двум точкам, то получим систему двух уравнений
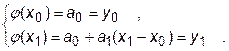
Решая ее относительно а 0 и а 1, будем иметь
 .
.
Отсюда формула для линейной интерполяции
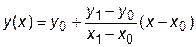 . (27.1)
. (27.1)
Поиск значения y (x) интерполяцией по двум точкам и появление возможной погрешности показано на рисунке 27.1.
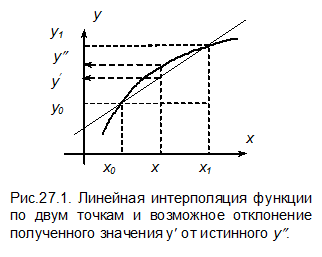 |
Формулу для линейной интерполяции можно также получить, рассматривая два подобных треугольника с катетами (y 1- y 0, x 1- x 0) и (y - y 0, x - x 0). Из условия подобия
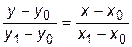
получаем сразу искомую зависимость (27.1).
Более точной является интерполяция по трем точкам. В этом случае формула интерполяционного многочлена приобретает вид
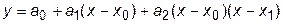 , (27.2)
, (27.2)
а коэффициенты интерполяции находятся из условия
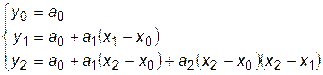
по формулам
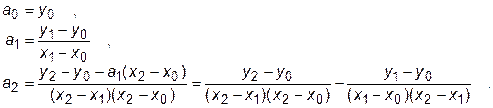
По этой схеме находятся коэффициенты для интерполяции полиномами более высоких степеней. Следует отметить, что при выборе степени полинома не следует стремиться к точности вычисления промежуточных значений, больших, чем точность представления значений в узлах таблицы.
Двухпараметрическая интерполяция.
Аналогичным образом проводится интерполяция, когда функция 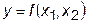 зависит от двух параметров х 1 и х 2. Для этого случая таблица данных представляет двухмерный массив для у и одномерные массивы для х 1 и х 2:
зависит от двух параметров х 1 и х 2. Для этого случая таблица данных представляет двухмерный массив для у и одномерные массивы для х 1 и х 2:
| x 1,1 | x 1,2 | … | x 1, k | … | x 1, n 1 | |
| X 2,1 | y 1,1 | y 1,2 | … | y 1, k | … | y 1, n 1 |
| X 2,2 | y 2,1 | y 2,2 | … | y 2, k | … | y 2, n 1 |
| … | … | … | … | … | … | … |
| X 2, i | yi ,1 | yi ,2 | … | yi , k | … | yi , n 1 |
| … | … | … | … | … | … | … |
| X 2, n 2 | yn 2,1 | yn 2,2 | … | yn 2, k | … | Yn 2, n 1 |
Предположим, что значения параметров х 1 и х 2 находятся в области
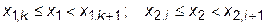 .
.
Это означает, что искомая точка находится внутри прямоугольника с вершинами y 1= y i,k; y 2= y i,k+1; y 3= y i+1,k; y 4= y i+1,k+1.
 |
Расчетная схема двухпараметрической интерполяции показана на рис.27.2. Для того, чтобы избежать громоздких вычислений, сначала проводят интерполяцию по одному параметру при фиксированном другом, например по х 1, и определяют значения функции в точках y 5 и y 6, а затем по второму параметру при фиксированном первом и находят окончательное значение функции в искомой точке y 7.
Если ограничиться линейной интерполяцией, то формулы для определения промежуточных и окончательного значений принимают вид
 . (27.3)
. (27.3)
Для того, чтобы с помощью интерполяции найти из таблицы значение функции, необходимо сначала определить узловые точки, между которыми находится искомое значение. Поиск таких узловых точек должен быть автоматизирован, чтобы при каждом обращении к таблице было бы достаточным указать только значения координат искомой точки.
Следует обратить внимание еще на одну проблему. Интерполяция обычно является вспомогательной задачей и применяется для вычисления значений некоторой функции, используемой в основной задаче. Координаты точки, в которой необходимо определить значение функции, могут оказаться вне диапазона табличных значений. В этом случае выбор варианта продолжения программы интерполяции должен основываться на физической сущности решаемой задачи.
Если выход координат точки за диапазон табличных значений противоречит физической природе исследуемого явления, то дальнейший расчет должен быть прекращен и на экран выведено соответствующее сообщение.
Иногда функция при некоторых значениях своих аргументов практически достигает своего предела. В этом случае при выходе аргументов за табличный диапазон можно принимать значения функции, соответствующие указанным в таблице предельным значениям аргументов.
Довольно часто встречается ситуация, когда в таблице приводятся значения аргументов и функции, полученные в результате ограниченного количества экспериментов. При этом отсутствуют экспериментальные данные о поведении функции за пределами исследованной области. Если выход аргументов за границы табличного диапазона не противоречит физической сущности описываемого явления, то иногда можно предположить, что и вне табличного диапазона характер изменения функции будет таким же, как и в ближайшей окрестности табличных значений. При этом допущении применяется метод экстраполяции, когда значение функции в некоторой точке рассчитывается по значениям функции на границах интервала, в который данная точка не попадает. Для расчета используются те же интерполяционные формулы. Достоверность полученных значений при экстраполяции будет тем выше, чем ближе к базовому интервалу находятся координаты расчетной точки. К экстраполяции прибегают обычно в тех случаях, когда получить интересующие данные другим путем невозможно, например, при оценке будущего состояния некоторой сложной системы.
Общая блок-схема интерполяции представлена на рис.27.3.
 |
Лекция 28. Численное дифференцирование.
К численному дифференцированию приходится прибегать в том случае, когда функция f (x), для которой нужно найти производную, задана таблично, или же функциональная зависимость x и f (x) имеет сложное аналитическое выражение. В первом случае методы дифференциального исчисления просто неприменимы, а во втором случае их использование вызывает значительные трудности.
Во всех этих случаях вместо функции f (x) рассматривают интерполирующую функцию j(х) и считают производную от f (x) приближенно равной производной от j(х). Естественно, что производная от f (x) будет найдена с некоторой погрешностью.
Существуют два основных источника возможного появления значительных погрешностей при численном дифференцировании. Функцию f(x) можно записать в виде
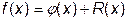 , (28.1)
, (28.1)
где j(х) – интерполирующая функция, а R (x) – остаточный член интерполяционной формулы. Предполагая, что f (x) и j(х) имеют производные k -того порядка, можно найти эти производные, дифференцируя тождество (5.1) k раз:
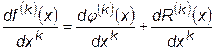 . (28.2)
. (28.2)
Так как за приближенное значение 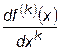 принимается величина
принимается величина 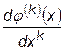 , то величина погрешности численного дифференцирования будет равна
, то величина погрешности численного дифференцирования будет равна 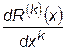 .
.
При замене f (x) интерполирующей функцией j(х) предполагается, что остаточный член (то есть величина R (x)) мал, но из этого совсем не следует, что мало 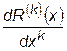 . Производные от малой функции могут быть весьма большими. Особенно это относится к производным высших порядков. Данная ситуация иллюстрируется на рис.28.1.
. Производные от малой функции могут быть весьма большими. Особенно это относится к производным высших порядков. Данная ситуация иллюстрируется на рис.28.1.
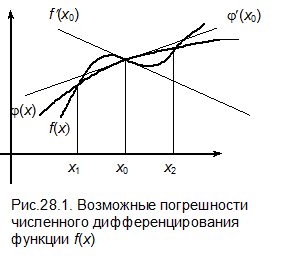 |
Даже в случае, когда интерполяционный многочлен хорошо аппроксимирует табличную функцию, его производные могут ничего не иметь общего с производными аппроксимируемой функции.
Вторая причина обусловлена использованием табличных данных, полученных экспериментальным путем. Эти значения всегда содержат некоторую погрешность, так называемый шум. Если продифференцировать эти значения, то наличие экспериментальных погрешностей значительно увеличит погрешность определения производной истинной функции.
Формулы численного дифференцирования.
Первая производная наиболее просто вычисляется при аппроксимации функции f (x) прямой линией. В этом случае касательная к кривой в одной точке заменяется секущей, проходящей через две точки кривой. Для точки х1 производная может быть рассчитана по формулам:
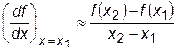 , (28.3)
, (28.3)
или
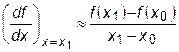 . (28.4)
. (28.4)
 |
Эти формулы равноправны, хотя могут привести к различным результатам, как это показано на рис.28.2. Если интервалы x 2- x 1 и х 1- х 0 равны, то более точной будет формула
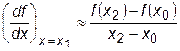 . (28.5)
. (28.5)
При расчетах по неравномерной сетке можно вычислить производные по формулам (28.3) и (28.4), а затем усреднить их с учетом весовых коэффициентов:
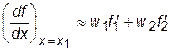 .
.
Логично предположить, что ближе к истинному значению производной будет значение, рассчитанное по формуле, у которой меньше интервал дифференцирования. Сумма весовых коэффициентов должна быть равна единице. Из этих соображений получаем весовые коэффициенты:
для первой формулы 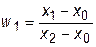 ,
,
для второй формулы 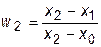 .
.
Окончательно формула для вычисления производной принимает вид
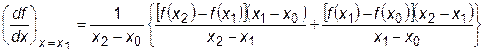 . (28.6)
. (28.6)
При x 2- x 1= х 1- х 0 она сводится к формуле (28.5).
Также можно аппроксимировать функцию f (x) степенным многочленом, например, многочленом второй степени:
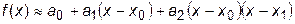 .
.
Коэффициенты а 0, а 1, а 2 рассчитываются по формулам:
Дифференцируя многочлен, получаем
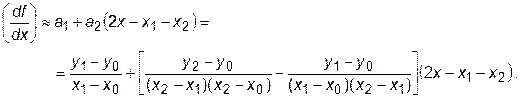
При x = х 1 эта формула сводится к выражению
 . (28.7)
. (28.7)
Для равноотстоящих узлов, когда x 2- x 1= х 1- х 0= h, получаем
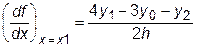 . (28.8)
. (28.8)
Аппроксимируя функцию f (x) многочленом более высокой степени, можно получить соответствующие формулы для вычисления производных по 4, 5 и более точкам.
Для расчета второй производной необходимо, как минимум, уже три точки.
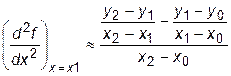 . (28.9)
. (28.9)
Для равноотстоящих узлов, когда x 2- x 1= х 1- х 0= h, получаем
 . (28.10)
. (28.10)
При выборе типа аппроксимации следует исходить из того, что вычисление по формулам более высокого порядка не всегда дает положительный эффект. Во-первых, расчет по более сложным формулам охватывает большее количество точек и требует большего объема машинной памяти, большего времени вычисления и поэтому он менее экономичен. Во-вторых, формулы более высокого порядка заметно эффективнее только при мелкой сетке, когда шаги дифференцирования x 2- x 1, х 1- х 0, относительно малы. В случае грубой сетки преимущество в точности быстро уменьшается.
С одной стороны ясно, что для увеличения точности вычислений необходимо стремиться к уменьшению шага дифференцирования. Это возможно только в том случае, если имеется возможность вычислять значения функции f (x) для любого х. При табличном представлении функции f (x) такая возможность отсутствует. С другой стороны, при наличии погрешностей в значениях функции уменьшение шага дифференцирования может привести даже к увеличению погрешности определения производной. При этом на точность расчета может существенным образом повлиять выбор порядка аппроксимирующего многочлена. Превосходство формул высокого порядка зависит от гладкости функций. Если есть разрывы функций или случайные колебания, то погрешности у формул высокого порядка могут оказаться выше, чем при использовании формул более низкого порядка.
Лекция 29. Решение оптимизационных задач
Одной из часто решаемых инженерных задач является поиск оптимального варианта некоторого решения. Обычно имеет место ситуация, при которой необходимо достичь некоторой цели, причем пути достижения этой цели могут быть различными. Соответственно выбор пути определит и соответствующие затраты. В общем случае выбор наилучшего способа называется решением оптимизационной задачи.
Прежде чем искать наилучший вариант, необходимо определить, в каком смысле он будет считаться наилучшим. Для оценки качества решения необходимо выбрать соответствующий критерий, который должен количественно отражать качество решения. Этот критерий называется целевой функцией.
Допустим, необходимо составить график ремонта сложного объекта, например, энергетического блока. Известен объем работы, которую необходимо выполнить. Работу можно организовать различными способами. В качестве целевой функции можно взять продолжительность ремонта и считать, что чем быстрее будет закончен ремонт, тем лучше вариант ремонта. В этом случае целесообразно увеличить количество ремонтного персонала, привлечь к работе посторонние организации. Такое решение потребует дополнительных затрат и может существенно увеличить стоимость ремонта.
Можно поставить другую задачу: необходимо выбрать график ремонта, при котором затраты на ремонт будут наименьшими. Здесь большую часть работы будет целесообразно выполнять собственными силами, причем используя только минимально необходимое количество ремонтного персонала.
Нельзя одновременно минимизировать продолжительность ремонта и затраты на ремонт. Целевая функция для поиска оптимального решения должна быть только одна. В том случае, когда желательно обеспечить выбор варианта, удовлетворяющего нескольким требованиям, можно представить обобщающую целевую функцию в виде некоторой суммы частных целевых функций, входящих в сумму с некоторыми весовыми коэффициентами.
Иногда приходится решать оптимизационные задачи с ограничениями. Для выбора графика ремонта может быть поставлена задача: обеспечить окончание работы в течение заданного срока, при этом затраты на ремонт должны быть минимально возможными.
В некоторых задачах наилучшим решением признается такое, при котором целевая функция достигает максимального значения, в других задачах необходимо найти минимум целевой функции. Традиционно алгоритмы поиска составляются таким образом, чтобы найти минимум целевой функции. В случае, когда решение является оптимальным при максимальном значении функции F 1, оно будет также оптимальным при минимуме функции F 2 = - F 1.
Выбор варианта решения связан с выбором некоторых величин, управляющих процессом. Эти величины называются факторами. Значения факторов определяют значения целевой функции. Факторы должны обладать следующими свойствами:
1. Быть управляемыми, т.е. в некотором диапазоне мы должны иметь возможность выбрать любое значение каждого из факторов.
2. Быть независимыми, т.е. изменение любого из факторов не должно приводить к изменению остальных.
Однофакторная оптимизация.
Наиболее простыми являются однофакторные задачи оптимизации. В этом случае целевая функция F зависит только от одного фактора x, т.е. имеем целевую функцию F (x).
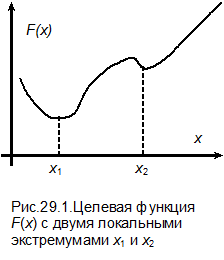 |
Функция F (x) может иметь несколько экстремумов. Если будем рассматривать задачу минимизации целевой функции, то точками оптимума будут точки минимума функции. Если таких точек несколько, как это показано на рис.29.1, то они называются точками локальных минимумов или точками локальных оптимальных решений. Глобальным называется решение, оптимальное для всей области определения x.
Переменной x могут быть самые разнообразные величины: геометрические размеры, электрические или механические показатели, концентрации химических веществ, объем производимой продукции и т.д. Для поиска оптимального решения необходимо, чтобы эти переменные были управляемыми.
Если задачу удается формализировать, т.е. подобрать ее математическое описание, то для поиска оптимума можно использовать соответствующие численные методы.
В общем виде при поиске минимума функции одной переменной F (x) необходимо найти такое 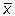 , при котором в некоторой окрестности
, при котором в некоторой окрестности 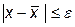 выполняется условие
выполняется условие 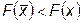 . Это условие локального минимума.
. Это условие локального минимума.
Для составления алгоритма поиска необходимо, чтобы функция F (x) была непрерывной или, по крайней мере, кусочно-непрерывной, т.е. состояла из конечного числа непрерывных кусков.
Для нахождения глобального минимума есть только один способ: найти все локальные минимумы, сравнить их между собой и выбрать наименьшее значение. Поэтому мы ограничимся задачей поиска локального минимума.
Поиск минимума сравнивают с поиском самого глубокого места в озере. Находясь на поверхности озера, мы не знаем рельефа дна, но можем в выбранных нами точках проводить замеры глубины. При однофакторной зависимости F (x) замеры производятся только вдоль некоторого направления x.
При каждом замере появляется новая информация. Если в последующем замере глубина оказалась больше, то это означает, что мы двигаемся в правильном направлении, если меньше, то необходимо сменить направление движения.
Разрабатывая методы оптимизации, стремятся создать алгоритмы, обеспечивающие нахождение экстремума за наименьшее количество измерений.
Для рассматриваемой задачи будем считать, что целевая функция F (x) унимодальна, т.е. на участке 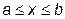 , включая концы интервала, имеет только один локальный минимум. Будем считать также, что погрешностью вычисления или экспериментального определения значений функции F (x) можно пренебречь. Построим итерационный процесс, сходящийся к этому минимуму.
, включая концы интервала, имеет только один локальный минимум. Будем считать также, что погрешностью вычисления или экспериментального определения значений функции F (x) можно пренебречь. Построим итерационный процесс, сходящийся к этому минимуму.
Интервал значений [ a, b ], в котором находится оптимум, называется интервалом неопределенности. В начале поиска длина интервала составляет 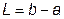 . Необходимо сузить этот интервал до требуемой величины e.
. Необходимо сузить этот интервал до требуемой величины e.
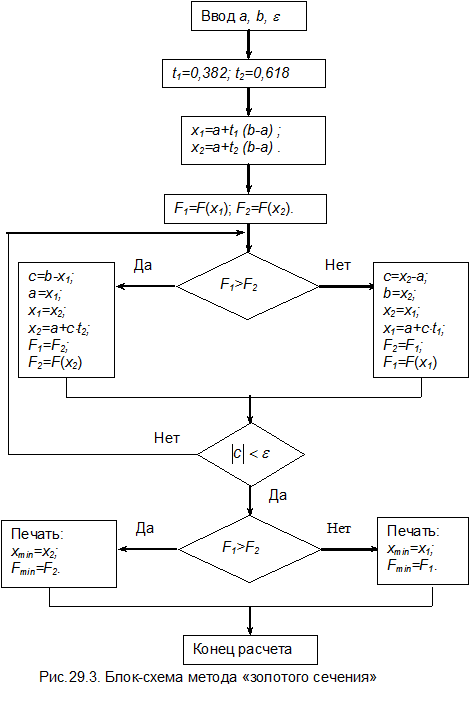
Метод «золотого сечения».
Одним из наиболее экономичных методов поиска является метод «золотого сечения». Идея метода представлена на рис. 29.2. Вычислим значения целевой функции на концах отрезка, а также в двух внутренних точках x 1 и x 2, сравним все четыре значения функции между собой и выберем среди них наименьшее. Предположим, что наименьшее значение имеет функция в точке x 1. Тогда очевидно, что минимум функции F (x) может находиться либо на отрезке [ a, x 1], либо на отрезке [ x 1, x 2]. На отрезке [ x 2, b ] минимума быть не может, поэтому этот отрезок отбрасываем и в дальнейшем рассматриваем только отрезок [ a, x 2].
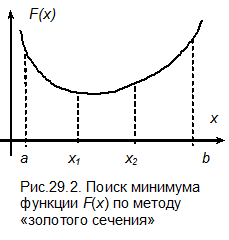 |
Первый шаг процесса сделан, интервал неопределенности уменьшился на длину отрезка [ x 2, b ]. Для дальнейшего сокращения интервала неопределенности необходимо снова выбрать на нем четыре точки (две на концах интервала и две внутри его), вычислить в них значения целевой функции, найти участок, на котором не может быть минимума, и исключить его. Эта операция должна продолжаться до тех пор, пока длина участка неопределенности не будет меньше заданной погрешности, т.е. будет выполнено условие 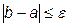 .
.
На втором шаге из четырех точек значения целевой функции известны в трех из первого шага, поэтому требуется определить значение функции только в одной точке. Это сокращает объем вычислений на одном шаге измерения. Более того, поскольку на каждом шаге всегда отбрасывается один из крайних интервалов, то для сокращения интервала неопределенности достаточно знать значения функции только в двух внутренних точках и поэтому на первом шаге значения целевой функции на краях интервала можно не вычислять.
Наиболее быстрое гарантированное сокращение интервала неопределенности достигается в том случае, когда разделение нового интервала на участки подобно предыдущему разделению. В силу симметрии должно быть выполнено условие:
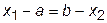 ,
,
а для подобия необходимо, чтобы длина большего интервала [ x 2, a ] относилась к длине меньшего интервала [ x 1, a ], как длина всего интервала [ a, b ] относилась к длине большего интервала [ x 2, a ], то есть
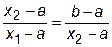 . (29.1)
. (29.1)
Это соотношение, называемое «золотым сечением» или «гармоничным делением», было сформулировано Леонардо да Винчи применительно к задачам архитектуры и изобразительного искусства. Поэтому и метод поиска экстремума функции, использующий те же пропорции разбиения интервала неопределенности на участки, носит название метода «золотого сечения».
Примем, что длина всего интервала неопределенности равна 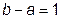 , и обозначим длину большего интервала
, и обозначим длину большего интервала 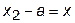 . Тогда длина меньшего интервала будет равна
. Тогда длина меньшего интервала будет равна 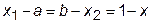 . Согласно пропорции «золотого сечения» получим
. Согласно пропорции «золотого сечения» получим
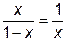 ,
,
откуда найдем длины участков:
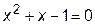 .
.
Учитывая, что длина участка есть положительная величина, имеем
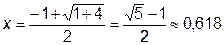 ,
, 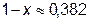 .
.
В соответствии с рис.7.2 при выборе области, в которой находится минимум функции F (x), на первом шаге определяются значения функции в во внутренних точках F 1= F (x 1)и F 2= F (x 2). При F 1> F 2 из дальнейшего анализа исключается интервал [ a,x 1], при этом точка а переносится в точку x 1, общая ширина интервала неопределенности становится равной c = b - x 1, точка x 2 становится точкой x 1, координаты новой точки x 2 рассчитываются по формуле
 . (29.2)
. (29.2)
При F 1< F 2 минимум функции отсутствует на интервале [ x 2, b ], поэтому точка b переносится в точку x 2, точка x 1 становится точкой x 2, а координаты новой точки x 1 определяются по формуле
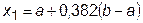 . (29.3)
. (29.3)
Так как на каждом шаге отбрасывается участок длиной 0,382 от первоначального, то для сокращения участка неопределенности в 10 раз необходимо сделать 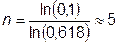 шагов, в 100 раз ®
шагов, в 100 раз ® 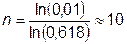 шагов, в 1000 раз ®
шагов, в 1000 раз ® 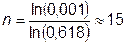 шагов.
шагов.
Блок-схема метода приведена на рис.29.3. Метод «золотого сечения» является наиболее экономичным деления отрезков применительно к задачам на минимум. Он применим даже к недифференцируемым функциям и всегда сходится; сходимость его линейна. Если на отрезке [ a, b ] целевая функция имеет несколько локальных минимумов, то процесс обязательно сойдется к одному из них, но необязательно к наименьшему.
Метод рассчитан на детерминированные задачи. В стохастических задачах, когда значения целевой функции зависят не только от фактора x, но и от других неконтролируемых и изменяющихся случайных факторов y, z, w …, можно неправильно определить значения целевой функции во внутренних точках и неправильно выбрать направление движения к минимуму.
 |
Лекция 30. Многофакторная оптимизация
Как правило, целевая функция оказывается зависимой не от одного, а от нескольких факторов x 1, x 2, …, x n. Многомерное пространство качественно отличается от одномерного. Прежде всего, с увеличением числа факторов возрастает вероятность появления локальных экстремумов. Кроме того, объем вычислений, необходимых для сужения интервала (в многомерном случае – области) неопределенности, значительно больше, чем при одномерной оптимизации.
Методы оптимизации в многомерном пространстве делятся на две большие группы: прямые и косвенные. Прямые методы основаны на сравнении вычисляемых значений целевой функции в различных точках, а косвенные – на использовании необходимых и достаточных условий математического определения минимума и максимума функции. Стратегия прямых методов – постепенное приближение к оптимуму. Прямые методы основаны на сравнении только значений целевой функции в различных точках. При использовании косвенных методов стремятся найти решение, не исследуя неоптимальные точки. Для этого анализируются не только значения целевой функции, но и ее производные.
 |
 |
 |
Основные проблемы многомерной оптимизации рассмотрим на примере функции двух переменных F (x, y). Эта функция описывает некоторую поверхность в трехмерном пространстве с координатами x, y, F (x, y). Задача 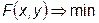 означает поиск низшей точки этой поверхности.
означает поиск низшей точки этой поверхности.
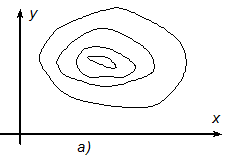
Как на топографических картах, изобразим рельеф этой поверхности линиями уровня. Проведем линии F (x, y)= const. Проекции этих линий на плоскость x, y называют линиями уровня. По виду этих линий условно выделяют три типа рельефа: котловинный, овражный и неупорядоченный.
При котловинном рельефе (рис.7.4.а) линии уровня напоминают эллипсы. Овражный тип рельефа (рис.7.4.б) имеет кусочно-гладкие линии с точками излома. Неупорядоченный тип рельефа (рис.7.4.в) характеризуется наличием многих максимумов, минимумов и седловин.
 |
Этот метод является наиболее простым. Идея метода показана на рис.30.1. Выберем начальное приближение x 0, y 0. Зафиксируем значение y = y 0, тогда функция F (x, y) будет зависеть только от одной переменной x. Обозначим через 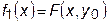 . Используя метод одномерного поиска, например метод «золотого сечения», найдем минимум функции f 1(x) и зафиксируем x = x 1. Затем зафиксируем новую точку (x 1, y 0) и из этой точки при постоянном x = x 1 для функции
. Используя метод одномерного поиска, например метод «золотого сечения», найдем минимум функции f 1(x) и зафиксируем x = x 1. Затем зафиксируем новую точку (x 1, y 0) и из этой точки при постоянном x = x 1 для функции 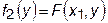 определим ее минимум. Найдя точку минимума функции f 2(x 1, y 1), из этой точки повторяем спуск сначала по x, затем по y и так до тех пор, пока не остановимся в некоторой точке
определим ее минимум. Найдя точку минимума функции f 2(x 1, y 1), из этой точки повторяем спуск сначала по x, затем по y и так до тех пор, пока не остановимся в некоторой точке 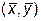 . Эту точку будем считать точкой локального минимума.
. Эту точку будем считать точкой локального минимума.
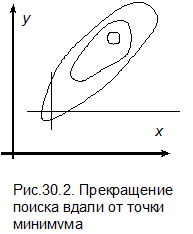 |
Вопрос о том, сойдутся ли спуски к минимуму и как быстро, зависит от целевой функции и выбора начальной точки приближения. Существуют случаи сходимости спуска по координатам к искомому минимуму и случаи, когда этот спуск не сходится. При овражном или сильно вытянутом котловинном рельефе можно попасть в такую точку, где спуск по любой координате ведет на подъем, в то время как минимум не достигнут. Эта ситуация показана на рис.30.2.
Вблизи минимума достаточно гладкой функции спуск по координатам линейно сходится к минимуму. Для эллипсов, сильно вытянутых под углом к осям координат, сходимость метода очень медленная. При овражном рельефе спуск по координатам практически не сходится. Поэтому этот метод применяется в сочетании с другими для поиска первого приближения.
Метод наискорейшего спуска.
Основная идея метода, представленная на рис.30.3, – движение к минимуму не по координатным осям, а по направлению наибольшего уменьшения целевой функции.
 |
Этот метод был предложен Коши в 1845 г. Поиск минимума производится по следующей схеме. Сначала задается начальная точка x 0(x 1 ,x 2 ,…,x n). Для определения направления скорейшего спуска используется понятие градиента функции
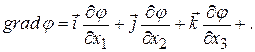 , (30.1) где
, (30.1) где  - частные производные по факторам.
- частные производные по факторам.
Градиент – это вектор, направленный в сторону наибольшего возрастания функции. Длина вектора пропорциональна скорости изменения функции. Если какая либо составляющая становится равной нулю, то это означает, что в этом направлении функция не изменяется.
Координаты новых точек выбираются по формулам
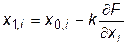 , (30.2)
, (30.2)
где i=1…n – порядковый номер фактора; k – некоторый масштабный коэффициент, постоянный для всех координат одной точки.
Как правило, целевые функции бывают достаточно сложными, поэтому частные производные рассчитываются по приближенным разностным формулам:
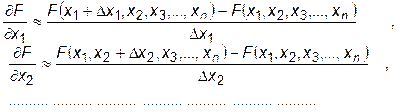 . (30.3)
. (30.3)
Спуск по этому направлению продолжается до достижения минимума целевой функции. Поиск этого минимума может быть осуществлен одним из методов однофакторной оптимизации, например, методом «золотого сечения». В точке минимума снова вычисляется значение градиента, определяется новое направление поиска и проводится однофакторная оптимизация. Процесс повторяется до тех пор, пока изменение координат локальных минимумов не станет пренебрежимо малым, т.е. будет выполнено условие
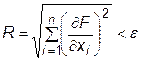 , (30.4)
, (30.4)
где e - наперед заданная малая величина.
Поскольку спуск в одном направлении кончается в точке, где его направление касается линии или поверхности постоянного уровня, то направление нового спуска будет перпендикулярно предыдущему.
В двумерном случае это означает, что мы совершаем спуск по координатам, повернутым так, что одна ось параллельна градиенту в начальной точке.
Этот метод значительно сложнее спуска по координатам, так как требуется вычислять производные и градиент и переходить к новым переменным. По сходимости он несколько лучше, но в практических задачах со сложным рельефом целевой функции также редко приводит к удовлетворительному результату.
Метод поиска по градиенту.
 |
Этот метод является модификацией метода наискорейшего спуска. Идея метода показана на рис.30.4, блок-схема – на рис.30.5. Здесь в начальной точке рассчитывается градиент целевой функции, делается всего один шаг в наилучшем направлении без проведения одномерной оптимизации, в новой точке снова выбирается наилучшее направление, делается снова шаг и т.д. до достижения минимума.
Достаточно сложным является вопрос о выборе величины шага. Такой выбор весьма ответственен: если величина шага слишком большая, значение целевой функции на следующем шаге может даже увеличиваться, если шаг слишком мал, процесс оптимизации будет чрезвычайно долгим. При приближении к точке минимума величина шага должна быть очень небольшой, в противном случае в конце оптимизации появятся колебания около точки минимума. Обычно в начале задают некоторое значение шага, которое затем постепенно уменьшают по некоторому правилу.
В таком виде метод применяется редко. Его слабое место – зависимость от выбора масштаба оптимизируемых параметров. Если мно  гомерное пространство очень вытянуто по некоторым переменным, то образуется овраг. Траектория поиска состоит из шагов поперек оврага, а сходимость к минимуму слишком медленна. Подобная ситуация показана на рис.30.6. Иногда точное решение невозможно получить за приемлемое время.
гомерное пространство очень вытянуто по некоторым переменным, то образуется овраг. Траектория поиска состоит из шагов поперек оврага, а сходимость к минимуму слишком медленна. Подобная ситуация показана на рис.30.6. Иногда точное решение невозможно получить за приемлемое время.
 |
Методы наискорейшего спуска и поиска по градиенту требуют вычисления частных производных. Если целевая функция недостаточно гладкая или имеют место погрешности в вычислении ее значений, то резко возрастают погрешности в вычислении производных или вообще теряется их смысл. В таком случае могут возникнуть ситуации, когда процесс поиска минимума потребует неприемлемо большого времени или вообще закончится вдалеке от истинного минимума.
Для этих случаев более пригодны прямые методы поиска, в которых используются только значения целевой функции в нескольких близлежащих точках. Эти методы малочувствительны к погрешностям вычисления целевой функции и часто позволяют получить хорошие результаты, когда другие методы оказываются неработоспособными.
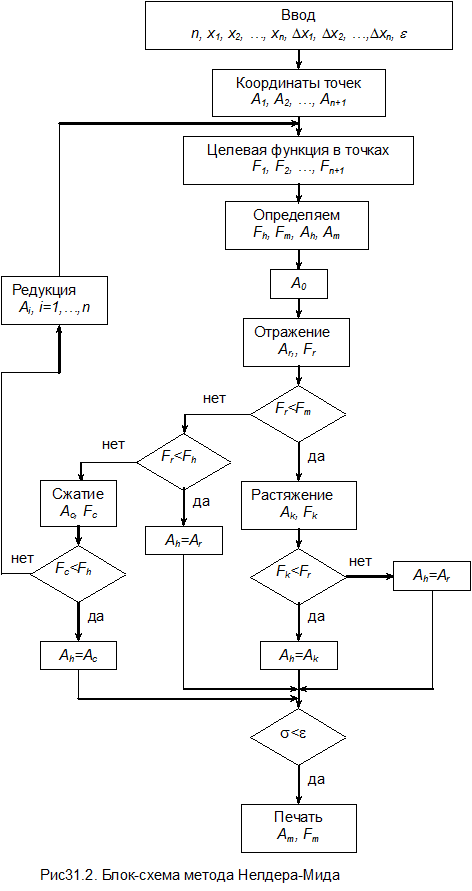
Лекция 31. ПРЯМЫЕ МЕТОДЫ ПОИСКА. МЕТОД НЕЛДЕРА-МИДА
(ПОИСК ПО ДЕФОРМИРУЕМОМУ МНОГОУГОЛЬНИКУ).
Идея метода состоит в сравнении значений целевой функции с n независимыми переменными функции в n+ 1 точках и перемещение поиска в направлении оптимальной точки с помощью итераций.
Рассмотрим последовательность поиска на примере двухпараметрической функции F (x,y), для которой процесс поиска можно представить графически.
1. Задаем начальную точку A1, (x1,y1).
2. Задаем начальное изменение координат по осям D x, D y.
3. Вычисляем координаты остальных n точек. Для двухфакторной задачи это A2 (x1+ D x,y), A3 (x1,y+Dy).
4. Вычисляем значения целевой функции в этих точках F1, F2, F3.
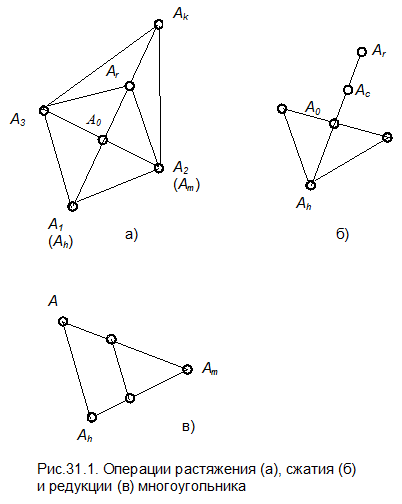
5. Находим точки, в которых целевая функция имеет наибольшее и наименьшее значения. Допустим, что наибольшее значение в точке A1, а наименьшее – в точке A2. Обозначим координаты точки A1 как Ah, а значение функции F1 – как Fh. Соответственно для точки A2 ® Am и Fm.
6. Находим координаты центра тяжести всех точек за исключением самой «плохой» точки Ah:
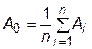 . (31.1)
. (31.1)
Для двухфакторной задачи координаты центра тяжести будут находиться на середине отрезка A2A3.
7. Вероятнее всего минимум будет находиться в наибольшем отдалении от наиболее «плохой» точки Ah, поэтому проведем прямую из точки Ah через центр тяжести точку A0 и произведем операцию отражения, определив координаты точки Ar из выражения
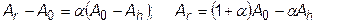 . (31.2)
. (31.2)
Здесь a - коэффициент растяжения. Далее находим значение целевой функции в точке Ar ® Fr.
8. Сравниваем значения функций Fr и Fm.
8.1. Если Fr<Fm, то мы получили наилучшую точку. Это означает, что направление из точки A0 через точку Ar наиболее удобно для перемещения. В этом случае производится растяжение многоугольника вдоль линии A0-Ar и находим точку Ak из условия
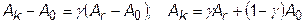 , (31.3)
, (31.3)
где g - коэффициент растяжения; g > 1.
В точке Ak вычисляем значение целевой функции Fk.
8.1.1. Если Fk < Fm, то заменяем точку Ah на точку Ak и проверяем сходимость многоугольника к минимуму. Если сходимость достигнута, то процесс останавливается, в противном случае возвращаемся к п.5.
8.1.2. Если Fk > Fm, то отбрасываем точку Ak. Очевидно, что мы переместились слишком далеко от точки A0 к точке Ar. Поэтому заменяем точку Ah на точку Ar и проверяем сходимость. Если сходимость не достигнута, то возвращаемся к п.5.
8.2. Если Fr > Fm, но Fr < Fh, то Ar является лучшей точкой по сравнению с наиболее «плохой» точкой многоугольника. Поэтому заменяем точку Ah на точку Ar и проверяем сходимость. Если сходимость не достигнута, то возвращаемся к п.5.
8.3. Если Fr > Fh, то точка Ar является наихудшей. В этом случае проводим операцию сжатия многоугольника и находим новую точку Ac.
Координаты точки определяются из выражения
 . (31.4)
. (31.4)
8.3.1. Если Fc< Fh, то заменяем точку Ah на точку Ac и проверяем сходимость. Если сходимость не достигнута, то возвращаемся к п.5.
8.3.2. Если Fc > Fh, то это означает, что новая точка хуже остальных. В этом случае производим операцию сокращения многоугольника. Уменьшение производится в сторону вершины с наименьшим значением целевой функции (к точке Am).
Координаты новых вершин рассчитываются по формуле
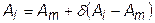 , (31.5)
, (31.5)
где d - коэффициент редукции; 0<d<1. Затем возвращаемся к п.4.
Операции растяжения, сжатия и редукции многоугольника показаны на рис.31.1, блок-схема метода – на рис.31.2.
В процессе расчета деформируемый многоугольник вытягивается вдоль длинных наклонных плоскостей, сжимается в окрестности минимума и в области минимума стягивается в точку.
Проверка на сходимость проводится по выражению
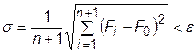 , (31.6)
, (31.6)
где e - наперед заданное небольшое число;
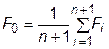 . (31.7)
. (31.7)
Скорость расчета и, возможно, результат, зависят от коэффициентов a, b, g, d и начальной точки, с которой стартует расчет. Авторы рекомендуют брать a=1; b=0,5; g=2; d=0,5.
 |
 |
Лекция 32. ПОИСК С ОГРАНИЧЕНИЯМИ. КОМПЛЕКСНЫЙ МЕТОД БОКСА.
Довольно часто встречаются задачи, в которых требуется найти оптимальное решение при условии, что определяющие факторы xi должны находиться внутри некоторого диапазона
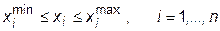 (32.1)
(32.1)
и при этом обеспечено выполнение неявных ограничений в виде
 , (32.2)
, (32.2)
где gk – некоторая функция, зависящая от всех или некоторых факторов xi.
Для решения подобных задач иногда можно использовать рассмотренные выше методы оптимизации, вводя штрафные функции. В этом случае при последующем шаге и несоблюдении условий (32.1) или (32.2) значение целевой функции искусственно увеличивается, причем это увеличение должно быть тем больше, чем дальше вышла рассматриваемая точка из допустимого диапазона. Такой прием препятствует продвижению поиска в запрещенном направлении и возвращает процесс оптимизации в допустимую область.
Однако для некоторых задач такой подход может оказаться неприемлемым. Налагаемые на область поиска ограничения могут быть связаны с физической сущностью задачи. Например, если один из факторов оптимизации связан с геометрическими характеристиками (длина или диаметр рабочей камеры) или массовыми потоками (расход топлива или воздуха), то перемещение этих параметров в область отрицательных значений лишает смысла само решение и обычно не позволяет даже вычислить целевую функцию в этой точке. Как правило, это приводит к зависанию или аварийному прекращению вычислительной программы и не позволяет проводить дальнейший поиск.
Для подобных задач очень эффективным является комплексный метод, предложенный в 1964 г. М. Боксом. По существу этот метод является модификацией метода Нелдера-Мида, позволяющего учесть наличие ограничений до вычисления целевой функции. Процесс поиска сводится к последовательному выполнению следующих операций:
1. Для начала расчета задаются явные в виде (32.1) и неявные в виде (32.2) ограничения на область поиска и указывается допустимые погрешности поиска e1 и e2.
2. Вводятся координаты начальной точки B 1(x 1, x 2,…, x n), удовлетворяющей всем ограничениям и вычисляется значение целевой функции в этой точке F 1.
3. Задается количество точек комплекса m. Это число должно быть больше, чем количество факторов оптимизации n. Бокс предлагает выбирать 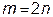 .
.
Определяются координаты остальных m- 1 точек комплекса, удовлетворяющие всем ограничениям. Для этого в диапазоне 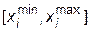 случайным образом определяется координата точки B i. Для подобной операции в Турбо-Паскале существует функция random, обеспечивающая получение псевдослучайного числа в диапазоне [0,1]. При этом, чтобы исключить повторение цепочки случайных чисел при повторном запуске программы, необходимо подключить процедуру randomize.
случайным образом определяется координата точки B i. Для подобной операции в Турбо-Паскале существует функция random, обеспечивающая получение псевдослучайного числа в диапазоне [0,1]. При этом, чтобы исключить повторение цепочки случайных чисел при повторном запуске программы, необходимо подключить процедуру randomize.
Блок случайного выбора координат m- 1 точек комплекса может быть представлен следующим образом:
randomize;
for k:= 2 to m do
for i:= 1 to n do
B [ k,i ]:= xmin [ i ]+ random* (xmax [ i ]- xmin [ i ]);
Выбор координат точки внутри интервала [ xmin,xmax ] гарантирует выполнение ограничений (7.15). Если при этом выполняются неравенства (7.16), то эта точка включается в начальный комплекс. При невыполнении условий (7.16) производится корректировка координат. Для этого вычисляется центр тяжести координат (среднее арифметическое) множества k- 1 уже принятых точек
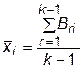 (32.3)
(32.3)
и затем координаты k -той точки смещаются на половину расстояния до центра
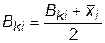 . (32.4)
. (32.4)
Пересчет координат по формуле (32.3) производится до тех пор, пока не будет обеспечено выполнение всех условий (32.4).
После формирования начального комплекса вычисляются значения целевых функций Fi в каждой из m точек.
4. Далее производится ранжирование точек комплекса по возрастанию значений целевых функций. На первое место устанавливается точка с наименьшим значением целевой функции («лучшая» точка), на последнее m – точка с наибольшим значением целевой функции (самая «плохая» точка).
5. Затем по формуле (32.3) определяется центр тяжести m- 1 «наилучших» точек B 0 и вычисляется значение целевой функции в центре F0. Если окажется, что найденная точка не обеспечивает выполнение условий (7.16) или является «наихудшей» точкой, т.е. F0>Fm, то координаты нового центра пересчитываются по (32.3) для m- 2 «наилучших» точек. Эта операция выполняется до тех пор, пока не будет выполнено условие F0<Fm. Выбор центра тяжести «наилучших» точек при условии, что центр будет не самой «плохой» точкой, позволяет обходить локальные вершины при движении к оптимуму и исключить зацикливание вычислительной программы.
6. От наиболее «плохой» точки Bm через центр тяжести B 0производится отражение (поиск координат) новой точки Br по формуле
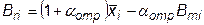 , (32.5)
, (32.5)
где a отр – коэффициент отражения, a отр >1. Автор метода предлагает принимать a отр =1,3.
Найденная таким образом точка Br проверяется на выполнение условий (32.1) и (32.2). Если значение Bri выходит за границы допустимой области, то соответствующие координаты точки смещаются на границу: при 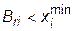 принимается
принимается 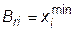 , при
, при 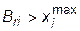
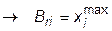 . При невыполнении условий (32.2) точка смещается к центру области, ее координаты рассчитываются по формулам (32.3), (32.4), в которых положение центра определяется по всем n точкам комплекса.
. При невыполнении условий (32.2) точка смещается к центру области, ее координаты рассчитываются по формулам (32.3), (32.4), в которых положение центра определяется по всем n точкам комплекса.
После того, как новая точка будет признана допустимой, для нее вычисляется значение целевой функции Fr. Если Fr > Fm, т.е. эта точка оказывается «хуже» самой «плохой» точки комплекса, то она перемещается к центру комплекса, ее координаты пересчитываются по (7.17) и (7.18). При Fr £ Fm в комплексе самая «плохая» точка заменяется на новую.
7. После операции отражения по схеме п.4. проводится ранжирование точек.
8. Далее вычисляются параметры s1 и s2. Величина s1 соответствует среднему квадратичному отклонению значений целевых функций комплекса от их средней величины и рассчитывается по формуле
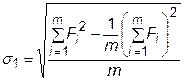 . (32.6)
. (32.6)
Величина s2 равна расстоянию между самой «лучшей» и самой «плохой» точками комплекса. Она рассчитывается по формуле
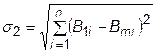 . (32.7)
. (32.7)
9. По параметрам s1 и s2 проверяется сходимость комплекса к оптимуму. При одновременном выполнении условий
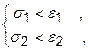 (32.8)
(32.8)
оптимум считается найденным и поиск прекращается. В том случае, если хотя бы одно из условий (32.8) не выполняется, поиск продолжается, начиная с п.5.
10. По








