 2015-01-30
2015-01-30 4649
4649Проследим, как происходило обращение к отдельно взятой ячейке ОЗУ у различных поколений ЭВМ.
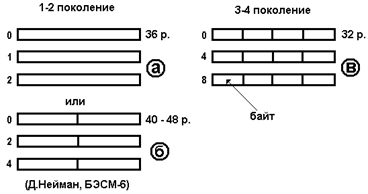
Cамые первые ЭВМ использовали всего два типа информации — числа и программу их обработки. Чаще всего их длина выбиралась одинаковой (см. рис. а), типичное значение составляло 36-40 двоичных разрядов. Каждая такая ячейка ОЗУ получала свой собственный номер, так что адреса соседних чисел (или команд) отличались на единицу. Вся память, таким образом, состояла из абсолютно одинаковых ячеек, любая из которых могла вместить в себя ровно одно число или команду.
Примечание. Гораздо реже использовалась архитектура, где длина команды составляла половину числа (рис. б), как, например, в известной машине БЭСМ-6. Интересно, что классическая работа Д. Неймана с соавторами 1946 года предлагала реализовать именно такой формат команд и данных.
По мере развития вычислительной техники (при переходе от второго поколения к третьему) и расширения сферы ее применения появилась дополнительная потребность работать с текстовой информацией. Возникло существенное противоречие между использовавшимся «большим» размером ячеек ОЗУ и количеством разрядов, необходимым для хранения одного символа (для символа согласно стандарту ASCII выделяется 1 байт, т.е. 8 разрядов). Наиболее разумным выходом из положения явилось дробление ячеек памяти на более мелкие так, чтобы появилась возможность извлекать один отдельно взятый символ. В результате возникла байтовая структура памяти, изображенная на рис. в. В новой системе числа занимали 4 байта, так что номера двух соседних из них отличались уже не на единицу, а на четыре. Такова «плата» за введение возможности обработки текстов и прочих видов информации, требующих для хранения различного объема ОЗУ.
Примечание. Объем памяти 32 разряда, который требовался для хранения одного числа, в ЕС ЭВМ третьего поколения стал называться машинным словом. Подчеркнем, что в тот момент оно не было связано с разрядностью какого-либо устройства и являлось чисто логической характеристикой обрабатываемой информации. С переходом к четвертому поколению, которое базируется на микропроцессорах, машинное слово обрело связь с аппаратной частью, а именно с разрядностью процессора.
При сохранении многобайтовых данных в последовательные байты ОЗУ возможно два равноценных варианта: сохранять байты, начиная либо с самого старшего, либо с самого младшего. Первый способ сохранения называется прямым порядком байтов (английский эквивалентный термин big endian), а второй — обратным (little endian). Процессоры фирмы Intel, использующиеся в компьютерах семейства IBM PC, всегда используют обратный порядок байт.
Байтовая структура памяти оказалась гибкой и удобной, так что она без изменений сохранилась не только в машинах третьего, но и в современных компьютерах четвертого поколения.








