 2015-01-30
2015-01-30 883
883Понимание типа объектов. Будем считать, что у нас задан некоторый номинальный признак Y – отвечающий, например, рассматриваемому выше вопросу в анкете: За кого Вы собираетесь голосовать? – с 5-ю альтернативами – вариантами ответов: Е, Ж, З, Л, Я.. Для каждой проверяемой группы объектов будем вычислять распределение входящих в нее респондентов по этому признаку, подсчитывать соответствующее модальное значение и определять долю его встречаемости. Соответствующий процент будет служить оценкой качества группы с точки зрения возможности рассматривать ее как тип.
Приведем примеры. Предположим, что распределения в каких-то двух группах выглядят следующим образом.
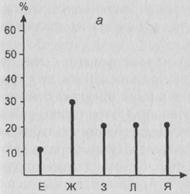
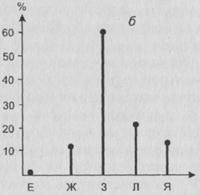
Рис. 18 Примеры частотных распределений, отражающих электоральное поведение двух групп респондентов
Модальное значение для первой совокупности – Ж, его доля – 30 %. Для второй же совокупности мода – З. Ее доля – 60%. Качество второй совокупности выше. Однако, вероятно, мы ни ту, ни другую группу не можем рассматривать как тип, поскольку оба процента не достаточно высоки для того, чтобы можно было считать группу “олицетворяющей” определенный тип поведения. Отметим, что содержательные типы тут в принципе будут разными – каждая группа будет ассоциироваться со своим “модальным” политическим лидером.
Алгоритм перебора сочетаний значений предикторов. Как мы уже отметили, алгоритм придуман именно для того, чтобы некоторые сочетания значений предикторов заведомо не просматривались машиной. Социологу важно знать, какие именно. Чтобы это понять, рассмотрим алгоритм.
Первый шаг. Работаем с каждым признаком отдельно. Перебираем следующие варианты разбиения всех его альтернатив на две части: (первая – все остальные); (первая и вторая – все остальные); (первая,вторая, третья – все остальные) и т.д. до последнего варианта: (все, кроме последней, – последняя). Подчеркнем, что перебираются не все возможные варианты сочетаний значений одного признака: множество значения разбивается только на две части и “склеиваются” только соседние градации. Если мы полагаем, что, например, один тип не могут составлять люди с высшим и начальным образованием, то этот алгоритм должен быть отвергнут.
Оцениваем качество (в описанном выше смысле - как долю модальной частоты признака-функции) каждой из двух групп, получающихся при одном разбиении одного признака (имеются в виду группы респондентов, отметивших альтернативы той или иной группы; мы как бы отождествляем группу альтернатив и группу отвечающих им респондентов). Пусть первая группа включает n1 человек и доля модальной частоты для нее составляет P1 %, а вторая группа состоит из n2 человек и доля модальной частоты составляет P2 %. Тогда вычислим показатель качества всего разбиения:
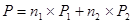
Заметим, что здесь мы по существу имеем дело с взвешенным средним. Такой способ усреднения очень распространен в социологии.
Итак, каждое разбиение совокупности альтернатив каждого признака получило свою оценку качества. Выберем наилучшее. Скажем, таковым оказало разбиение совокупности альтернатив признака “образование” на группы (1,2) и (3,4,5). Далее будем изучать респондентов каждой группы отдельно.
Второй шаг. Берем респондентов с низким образованием (отметивших альтернативы 1 и 2, означающие, скажем, начальное и неполное среднее образование) и делаем для них то же самое, что только что делали для всех респондентов (естественно, отличие будет состоять в том, что признак “образование уже не будет рассматриваться). Получим самое хорошее разбиение совокупности респондентов - скажем, это будет разбиение по признаку “семейное положение”, группы альтернатив (1, 2) и (3).
Далее будем изучать отдельно тех людей с низким образованием, которые женаты или неженаты (альтернативы 1 и 2 соответственно) и тех людей с низким образованием, которые разведены (альтернатива 3). И будет это делаться на третьем шагу. А на втором мы должны рассмотреть людей с высоким образованием (отметивших альтернативы 3,4,5 - среднее, неполное высшее и высшее образование соответственно) и реализовать для них ту же процедуру. Допустим, для них наилучшим оказалось разбиение по социальному происхождению, группы альтернатив (1) и (2 и 3). Тогда на третьем шаге мы будем изучать отдельно группы людей с высоким образованием, из семей рабочих (альтернатива 1) и людей с высоким образованием из семей служащих или военных (альтернативы 2 и 3).
Таким образом, у нас уже образовались цепочки, изображенные на рис. 19.
 |
Рис. 19. Пример результата работы алгоритма THAID
На третьем шаге каждая из четырех получившихся групп разделится еще на две. И каждый раз мы будем получать группы с увеличивающейся долей модальной частоты по нашему признаку-функции. Каждую “цепочку” можно считать описанием той группы людей, которая “висит” на конце этой “цепочки”.
Чтобы понять,чем дело кончится, перечислим причины останова действия машины. Сразу отметим, что они довольно типичны для анализа социологических данных, действуют при решении очень многих задач, при работе многих, весьма различных алгоритмов.








