 2015-01-30
2015-01-30 1720
1720Основными задачами при кодировании являются следующие:
а)обеспечить однозначное соответствие кода с объектом;
б)обеспечить минимальное число символов, приходящихся на сообщение.
Задачу минимизации среднего числа символов, приходящихся на одно сообщение при кодировании, впервые решил К.Шеннон.Им доказана основная теорем кодирования:
При заданном ансамбле Х из N сообщений с энтропией Н(х) и алфавитом, состоящем из D символов, возможно так закодировать сообщения ансамбля посредством последовательности символов, принадлежащих заданному алфавиту, что среднее число символов на сообщение n удовлетворяет неравенству:
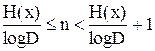 (6.1)
(6.1)
Нижняя граница неравенства 6.1 объясняется следующим.
Мы уже знаем, что энтропия Н(х) представляет собой среднее количество информации, необходимое для однозначного определения сообщения из этого ансамбля. Знаем также, что символы несут максимальное количество информации, равное log D, когда они равновероятны. Поэтому можно утверждать, что
nlogD≥H(x),где 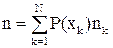 ,
,
где nk – число символов в кодовом обозначении x k-го сообщения.
Другими словами, среднее число символов на сообщение не может быть меньше энтропии ансамбля, делённой на пропускную способность алфавита.
Для бинарных алфавитов D=2 и нижняя граница среднего числа символов определяется из условия
H(x)≤n.
Вывод верхней границы подсказан леммой:
Для существования множества кодовых слов со средней длинной
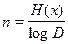 необходимо и достаточно, чтобы для каждого сообщения xk выполнялось условие
необходимо и достаточно, чтобы для каждого сообщения xk выполнялось условие
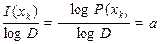 ,где а – целое число.
,где а – целое число.
Когда это условие выполнено, то
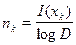
На практике правая часть редко бывает целым числом. Поэтому число элементов nk приходиться брать равным наименьшему целому числу, большему, чем правая часть этого равенства. Из-за этого среднее число символов увеличивается на единицу.
Произведённые рассуждения позволили К.Шеннону сформулировать два правила кодирования:
1.В каждой из позиций кодового слова различные символы алфавита должны использоваться с равными вероятностями.
2.Вероятности появления символов в каждой позиции кодового слова должны не зависеть от всех предыдущих символов.
К.Шеннон предложил процедуры кодирования, основанные на приведённых правилах. Они сводятся к следующему:
1-й шаг: все сообщения ансамбля записываются в столбец по мере убывания априорных вероятностей появления их.
2-й шаг: всё множество сообщений разбивается на две равновероятные группы, одной из них присваивается символ “1”,а другой “0”.
3-й шаг: в каждой из полученных групп реализуются процедуры 2-го шага. Процесс повторяется до тех пор, пока останется в каждой группе по одному сообщению.
Кодовые комбинации каждому сообщению формируются из полученных символов 0” и “1” при делении ансамбля на части. Этот метод удобно представить в виде кодового дерева. Ветвям после узлом разветвления присваиваются символы “0” и ”1”.
Сообщениям присваиваются кодовые слова, образованных на концевых узлах, символов ведущих к ним ветвей.
Автором другого метода кодирования является Д.Хафман. Процедура кодирования:
1-й шаг: все N сообщений располагаются в порядке убывания вероятностей.
2-1 шаг: группируют вместе два сообщения
с минимальными вероятностями и определяют суммарную вероятность группы.
Верхней ветви объединения присваивают “1”,а нижней “0”.
3-й шаг: образуют новый ансамбль с учётом объединения т выполняют в нём процедуры 1-го и 2-го шагов.
Процесс продолжается до тех пор, пока в ансамбле не останется единственное сообщение с вероятностью 1.
Сообщениям присваиваются кодовые слова, образованные символами, стоящими на ветвях, ведущих к ним. Причём, сообщения оказываются на концевых узлах, а начало дерева находиться в конце последней операции. Поэтому слева в кодовом слове должны быть символы начала дерева(корень),а справа – символы последних ветвей.
Полученные кодовые слова по методам К.Шеннона и Д.Хафмана могут передаваться в канал связи без разделительных знаков между ними.
Эффективность кода оценивается величиной отношения
δ=Н(х)/n. (6.2)
Возникают попытки уменьшить среднее число символов на сообщение за счёт объединения сообщений в группы по ν сообщений. Тогда в новом ансамбле будет N^ν сообщений. Энтропия нового ансамбля 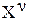 будет равна Н()=νH(X).
будет равна Н()=νH(X).
Среднее число символов на новое кодовое слово обозначим через nν.Среднее число символов на исходное сообщение составит величину n= nν/ν.
По основной теореме кодирования имеем
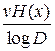 ≤nν< +1,
≤nν< +1,
после деления на ν всех элементов неравенства получаем
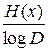 ≤n< + 1/ν.
≤n< + 1/ν.
Выходит, что объединение сообщений несколько уменьшает верхнюю границу. Для бинарных систем этот метод может привести к уменьшению среднего числа символов на сообщение, но не более, чем на один символ.

