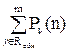2015-01-30
2015-01-30 834
834Требования к повышению достоверности передаваемых сообщений непрерывно повышаются. Одним из методов удовлетворения этих потребностей является помехоустойчивое кодирование. Идея метода состоит в том, чтобы на передающей стороне в кодовые комбинации (кодовые слова),состоящие из некоторого числа символов (информационные символы),внести несколько дополнительных (проверочных) символов и установить между всеми символами определённые логические связи. На приёмной стороне на основе анализа указанных логических связей делаются выводы о наличии или отсутствии ошибок, о возможности исправить их.
Простейшим примером реализации данного метода является кодирование на нечётность (или чётность),когда добавляется один символ, которому придаётся значение 1 или 0 с тем, что общее число единиц было нечётное (или чётное).Это позволяет обнаруживать нечётные сочетания ошибочных символов.
Большее число добавочных символов позволяет устанавливать более сложные логические связи и решать задачи не только обнаружения ошибок, но и исправления их.
Основная забота разработчиков систем кодирования состоит в том, чтобы при малом числе дополнительных символов обнаруживать и исправлять большее число ошибок. Кроме того, желательно, чтобы техническая реализация процедур кодирования и декодирования была простой.
Математическим аппаратом для исследования является высшая алгебра (теория групп, полей). Группой здесь называют множество элементов, удовлетворяющих определённым условиям. Отсюда пошло название групповых кодов, в которых кодовые комбинации обладают определёнными свойствами и их можно формировать по общему правилу, что облегчает техническую реализацию. Ещё они имеют название систематических кодов и обозначаются как (n,k)-коды, где n – общее число символов в кодовой комбинации, а k – число информационных символов. Тогда разность n-k=r - число избыточных (проверочных) символов. Отношение r/n – называют коэффициентом избыточности кода.
Большую и очень важную группу систематических кодов составляют циклические коды. Их основное свойство, определяющее название, состоит в том, что в результате циклического сдвига любой разрешённой кодовой комбинации на любое число символов (разрядов) вновь получается разрешённая кодовая комбинация.
Общее число кодовых комбинаций равно 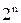 ,а число разрешённых из них составляет
,а число разрешённых из них составляет 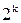 .
.
Циклические коды принято описывать при помощи полиномов:
1) производящего полинома g(x)=g0 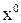 + g1
+ g1 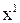 + … + gr
+ … + gr 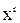
степени r и
2) проверочного полинома
h(x)=h0 + h1 + … + hk 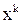
степени k.
Зная эти полиномы, можно строить схемы кодирования и декодирования, определять все характеристики кодов.
Основное требование к полиномам, определяющее пригодность их для построения кодов, выражается зависимостью
h(x)=(1+ 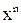 )/g(x). (6.11)
)/g(x). (6.11)
Наибольшее применение на практике получили схемы кодирования и декодирования, построенные на базе производящего полинома g(x).На рис. 5.12 представлена схема кодирования для общего случая. Она состоит из r ячеек памяти на два состояния (0 и 1) каждая, сумматоров по модулю (m2),переключателей (Кл1 и Кл2).Кружочки с обозначениями gi выполняют различные функции.
Если в полиноме g(x) символ gi=1,то данный кружочек следует рассматривать как замкнутый контакт в этом месте схемы, если gi=0,то в данном месте разрыв и эта цепочка не нужна и сумматор m2,к которому ведёт она, тоже не нужен.
Действие схемы кодирования таково. Вначале Кл1 и Кл2 находятся в положении 1.Информационные символы, подаваемые от источника данных, идут непосредственно в канал связи и, параллельно, на кодирующее устройство, где за k шагов образуется r проверочных разрядов в ячейках памяти. После этого ключи Кл1 и Кл2 переводятся в положение 2,цепь обратной связи в кодирующем устройстве разрывается и за последующие r тактов выводятся в канал проверочные разряды. Затем схема возвращается в исходное состояние для передачи следующего сообщения.

 2 Вх
2 Вх

|








 1
1


 Кл2
Кл2


 g0 g1 g2 gr-1
g0 g1 g2 gr-1


|

|

|
1






|





2 Вых.
Рис. 5.12
Для кода – (7.4) производящий полином g(x)=1 + x + 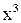 .
.
Можно убедится, что этот полином действительно производящий, разделив на него двучлен (1 + 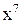 ).
).
Схема кодирующего устройства принимает вид, как показано на
рис. 5.13
 2
2

|


 1 Вх
1 Вх









 Кл2
Кл2
 1
1

|
 Кл1
Кл1
 |  |  | |||
2 Вых.
Рис.5.13
Пусть на вход схемы подаётся последовательность информационных символов 1001.В таблице 1 показано шаг за шагом формирование проверочных разрядов. Исходное состояние ячеек регистра определяется тремя нулями. Левый столбец “a” показывает последовательность информационных символов. Правый столбец “b” - символы, вытесняемые из регистра. В цепь обратной связи поступает сумма c=b+a.
Табл.1
| Ячейки регистра | ||||||||||||
| № такта | a | b | ||||||||||
  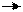
   В конце 4-го такта сформированы проверочные разряды 011. Они выходят в канал связи вслед за информационными: 0111001 – правый символ – первый, а левый – последний, седьмой. В конце 4-го такта сформированы проверочные разряды 011. Они выходят в канал связи вслед за информационными: 0111001 – правый символ – первый, а левый – последний, седьмой.
Схемы декодирования строятся методом незначительной модернизации схемы кодирования. На рис.5.14 представлена схема декодирования для рассматриваемого примера. Буф. Рг. Вход из канала связи Вых. |









Рис.5.14
Принимаемое сообщение вводиться в декодирующее устройство последовательными тактами. Параллельно оно поступает в буферный регистр приёмника. К концу приёма n-го символа (в примере n=7) в ячейках декодера сформируется какая-то кодовая комбинация. Если в ней буду одни нули, то это будет означать отсутствие ошибок. Присутствие единиц в любой из позиций указывает на наличие ошибок в символах. Анализатор может иногда определить, в каких разрядах сообщения произошли ошибки. Тогда их можно исправить. В большинстве случаев ограничиваются обнаружением ошибок, а исправление организуется по обратному каналу методом запроса повторных передач ошибочных сообщений.
Наибольше применение получили циклические код типы БЧХ (по фамилиям авторов Боуза, Чоудхури, Хоквингем).
При избыточности в r разрядов они обнаруживают 1)все пакеты ошибок длиной r и менее;2)[1 – 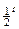 ]-ую часть пакетов длиной r+1 и 3)[1 –
]-ую часть пакетов длиной r+1 и 3)[1 – 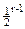 ]-ую часть пакетов длиной более r+1.
]-ую часть пакетов длиной более r+1.
Важную роль в определении обнаруживающей и исправляющей способности кода играет кодовое расстояние d – минимальное расстояние из всех расстояний dij между кодовыми комбинациями i и j в данном коде. Для обнаружения σ ошибочных символов необходимо, чтобы соблюдалось условие: d≥ σ + 1.Для исправления t ошибочных символов требуется d≥2t+1.
Формула Варшамова: 2r≥1+ i=1∑d-2 Ci n-
Вероятность наличия ошибки в ν символах кодовой комбинации из n разрядов определяется по формуле Бернулли.
Pν(m)= 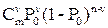 (5.12)
(5.12)
где p0 – вероятность искажения одного символа.
Вероятность правильного приёма сообщений вычисляется по этой формуле при ν=0.
Вероятность обнаруженных ошибок
Pобн=