 2015-02-27
2015-02-27 1025
1025Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются алгоритм Лемпеля-Зіва (алгоритм LZ) и его модификация алгоритм Лемпеля-Зіва-Велча (алгоритм LZW). Словарем в данном алгоритме является потенциально бесконечный список фраз. Алгоритм начинает работу с почти пустым словарем, который содержит только одну закодированную строку, так называемая NULL-строка. При считывании очередного символа входной последовательности данных, он прибавляется к текущей строке. Процесс продолжается до тех пор, пока текущая строка соответствует какой-нибудь фразе из словаря. Но рано или поздно текущая строка перестает соответствовать какой-нибудь фразе словаря. В момент, когда текущая строка представляет собой последнее совпадение со словарем плюс только что прочитанный символ сообщения, кодер выдает код, который состоит из индекса совпадения и следующего за ним символа, который нарушил совпадение строк. Новая фраза, состоящая из индекса совпадения и следующего за ним символа, прибавляется в словарь. В следующий раз, если эта фраза появится в сообщении, она может быть использована для построения более длинной фразы, что повышает меру сжатия информации.
Алгоритм LZW построен вокруг таблицы фраз (словаря), которая заменяет строки символов сжимаемого сообщения в коды фиксированной длины. Таблица имеет так называемое свойством опережения, то есть для каждой фразы словаря, состоящей из некоторой фразы w и символа К, фраза w тоже заносится в словарь. Если все части словаря полностью заполнены, кодирование перестает быть адаптивным (кодирование происходит исходя из уже существующих в словаре фраз).
Алгоритмы сжатия этой группы наиболее эффективны для текстовых данных больших объемов и малоэффективны для файлов маленьких размеров (за счет необходимости сохранение словаря).
Название алгоритм получил по первым буквам фамилий его разработчиков — Lempel, Ziv и Welch. Сжатие в нем, в отличие от RLE, осуществляется уже за счет одинаковых цепочек байт.
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами таблице строк такая строка. Если строка есть, то мы считываем следующий символ, а если строки нет, то мы заносим в поток код для предыдущей найденной строки, заносим строку в таблицу и начинаем поиск снова. LZW реализован в форматах GIF и TIFF.
LZW - это способ сжатия данных, который извлекает преимущества при повторяющихся цепочках данных. Поскольку растровые данные обычно содержат довольно много таких повторений, LZW является хорошим методом для их сжатия и раскрытия.
В данный момент давайте рассмотрим обычное кодирование и декодирование с помощью LZW-алгоритма. В GIF используется вариация этого алгоритма.
Первой вещью, которую мы делаем при LZW-сжатии является инициализация нашей цепочки символов. Чтобы сделать это, нам необходимо выбрать код размера (количество бит) и знать сколько возможных значений могут принимать наши символы. Давайте положим код размера равным 12 битам, что означает возможность запоминания 0FFF, или 4096, элементов в нашей таблице цепочек. Давайте также предположим, что мы имеем 32 возможных различных символа. (Это соответствует, например, картинке с 32 возможными цветами для каждого пиксела.) Чтобы инициализировать таблицу, мы установим соответствие кода #0 символу #0, кода #1 символу #1, и т.д., до кода #31 и символа #31. На самом деле мы указали, что каждый код от 0 до 31 является корневым. Больше в таблице не будет других кодов, обладающих этим свойством.
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами таблице строк такая строка. Если строка есть, то мы считываем следующий символ, а если строки нет, то мы заносим в поток код для предыдущей найденной строки, заносим строку в таблицу и начинаем поиск снова.
Пусть мы сжимаем последовательность 45, 55, 55, 151, 55, 55, 55. Тогда, согласно изложенному выше алгоритму, мы поместим в выходной поток сначала код очистки <256>, потом добавим к изначально пустой строке “45” и проверим, есть ли строка “45” в таблице. Поскольку мы при инициализации занесли в таблицу все строки из одного символа, то строка “45” есть в таблице. Далее мы читаем следующий символ 55 из входного потока и проверяем, есть ли строка “45, 55” в таблице. Такой строки в таблице пока нет. Мы заносим в таблицу строку “45, 55” (с первым свободным кодом 258) и записываем в поток код <45>. Можно коротко представить архивацию так: “45” — есть в таблице; “45, 55” — нет. Добавляем в таблицу <258>“45, 55”. В поток: <45>; “55, 55” — нет. В таблицу: <259>“55, 55”. В поток: <55>; “55, 151” — нет. В таблицу: <260>“55, 151”. В поток: <55>; “151, 55” — нет. В таблицу: <261>“151, 55”. В поток: <151>; “55, 55” — есть в таблице; “55, 55, 55” — нет. В таблицу: “55, 55, 55” <262>. В поток: <259>;
Последовательность кодов для данного примера, попадающих в выходной поток: <256>, <45>, <55>, <55>, <151>, <259>.
Особенность LZW заключается в том, что для декомпрессии нам не надо сохранять таблицу строк в файл для распаковки. Алгоритм построен таким образом, что мы в состоянии восстановить таблицу строк, пользуясь только потоком кодов.
Мы знаем, что для каждого кода надо добавлять в таблицу строку, состоящую из уже присутствующей там строки и символа, с которого начинается следующая строка в потоке.
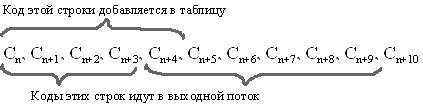
Следует отметить, что в целях экономии памяти ЭВМ таблицу цепочек можно эффективно представлять, учитывая следующую ее особенность: если, например, цепочка ASDFK входит в таблицу цепочек, то ASDF тоже входит в нее. Это обстоятельство наводит на мысль, что вместо запоминания в таблице всей цепочки, достаточно запомнить код для ASDF, за которым следует замыкающий символ K.
Для повышения степени сжатия изображений данным методом часто используется одна «хитрость» реализации этого алгоритма. Некоторые изображения, подвергаемые сжатию с помощью LZW, имеют часто встречающиеся цепочки одинаковых значений, например 12 12 12 … или 32 32 32 … и т. п. Их непосредственное сжатие будет генерировать выходной код 12 12 258 и т.д. Спрашивается, можно ли в этом частном случае повысить степень сжатия? Оказывается да, если мы оговорим следующие действия по кодированию и декодированию. Кодирование таких цепочек будем осуществлять следующим образом. Первый цвет 12 записывает с его же кодом из таблицы 12. Следующий цвет тоже 12, тогда добавляем в таблицу строку 12 12 с кодом 258 и в выходной поток сразу заносим этот код, т.е. 258. Смотрим входной поток дальше. Если на вход опять поступает цвет 12, он есть в таблице, смотрим следующий – 12, последовательность 12 12 тоже есть в таблице, смотрим дальше – 12, последовательности 12 12 12 присваиваем код 259 и заносим его в выходной поток. В результате на выходе получаем последовательность 12 258 259 …, которая гораздо короче прямого кодирования стандартным методом LZW.
Можно показать, что такая последовательность будет корректно восстановлена. Декодировщик сначала читает первый код – это 12, которому соответствует цвет 12. Затем читает код 258, но этого кода в его таблице нет. Но мы уже знаем, что такая ситуация возможна только в том случае, когда добавляемый символ равен первому символу только что считанной последовательности, т.е. 12. Поэтому он добавит в свою таблицу строку 12 12 с кодом 258, а в выходной поток поместит 12 12. И так может быть раскодирована вся цепочка кодов.
Мало того, описанное выше правило кодирования мы можем применять в общем случае не только к подряд идущим одинаковым цветам точек, но и к последовательностям, у которых очередной добавляемый символ равен первому символу цепочки.








