 2015-02-18
2015-02-18 4444
4444Под корректирующей способностью кода понимается его свойство обнаруживать и/или исправлять ошибку максимальной кратности q. Корректирующая способность кода связана с его кодовым расстоянием.
Расстоянием dij между кодами (кодовыми комбинациями) i и j называется число различных разрядов в кодовых комбинациях i и j. Например, если есть коды 01 и 10, расстояние между ними равно 2: они различаются в двух разрядах.
Кодовым расстоянием d для кода, содержащего m кодовых комбинаций, является минимальное расстояние между всеми парами кодовых комбинаций, т.е.
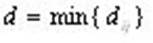 ,
,
где i≠j, i=1, m; j=1, m.
Пусть есть кодовая таблица:
| Исходные символы | Двоичные коды |
| a | |
| b | |
| c | |
| d |
Тогда расстояния между кодовыми комбинациями имеют значения:
dab = 1; dad = 2; dbd = 1; dac = 1; dbc = 2; dcd = 1.
Отсюда следует:
d = min{1, 2, 1, 1, 2, 1} = 1.
Это означает, что всякая ошибка кратности 1 (и более) переводит исходную кодовую комбинацию в другую кодовую комбинацию, которая также принадлежит коду.
Увеличить кодовое расстояние можно, введя в кодовые комбинации дополнительный разряд (или разряды). Тогда исходные разряды называют информационными, а дополнительный (или дополнительные) – проверочным (проверочными).
Значение одного проверочного разряда в простейшем случае определяется как результат суммирования по модулю 2 информационных разрядов.
Для кодов из приведенной выше таблицы введем дополнительный разряд и сформируем его значение. Результат показан ниже:
| Исходные символы | Информационные разряды кода | Проверочный разряд кода | Результирующий код |
| a | |||
| b | |||
| c | |||
| d |
Таким образом, полученный код является трехразрядным.
Определим кодовое расстояние полученного кода. Для этого вначале выясним расстояния между кодовыми комбинациями:
dab = 2; dad = 2; dbd = 2; dac = 2; dbc = 2; dcd = 2.
Тогда d = min{2, 2, 2, 2, 2, 2} = 2.
Пусть передается кодовая комбинация, соответствующая символу c, – 101. Пусть на нее накладывается ошибка кратности 1. Возможные результаты искажения приведены в таблице:
| Передаваемая кодовая комбинация | Ошибка | Принимаемая кодовая комбинация | Результат декодирования |
| Невозможно декодировать | |||
| То же | |||
| "-" |
В результате данной ошибки получаемые кодовые комбинации невозможно декодировать, так как они отсутствуют в результирующем коде (см. таблицу выше).
Обнаружение ошибки
Корректирующая способность кода основана также на понятиях разрешенных и запрещенных кодовых комбинаций.
Разрешенными кодовыми комбинациями называются те, которые присутствуют в исходной кодовой таблице. Например, если сформирован код
| Исходные символы | Информационные разряды кода | Проверочный разряд кода | Результирующий код |
| a | |||
| b | |||
| c | |||
| d |
то кодовые комбинации из графы Результирующий код являются разрешенными кодовыми комбинациями. Их количество равно числу исходных символов (m).
Запрещенные кодовые комбинации – это те, которые отсутствуют в исходной кодовой таблице. Их количество определяется по формуле: 2r – m, где r – общее число двоичных разрядов (информационные плюс проверочные) в коде.
Сформируем все разрешенные и запрещенные кодовые комбинации для кода из приведенной выше таблицы, при этом используем схему формирования кода Грея:
| a | ||
| b | ||
| d | ||
| c |
Здесь обозначения строк – значения графы Информационные разряды кода, обозначения столбцов – значения проверочных разрядов. Пустые ячейки означают запрещенные кодовые комбинации.
Как видно из последней таблицы, отстояние кодовых комбинаций для исходных символов a, b, c, d равно двум разрядам:
· символы, находящиеся в одном столбце (a и d, b и c), имеют одинаковый проверочный разряд, но находятся в несмежных строках, которые различаются двумя разрядами;
· символы, находящиеся в смежных строках (a и b, b и d, d и c), которые различаются одним разрядом, расположены попарно в разных столбцах, имеющих различное обозначение.
Поэтому при наличии ошибки кратности 1 кодовая комбинация переходит в соседнюю запрещенную.
Очевидно, коды, построенные по схеме рис. 4.3, не позволяют обнаружить ошибку кратности 2: в самом деле, при этом кодовая комбинация переходит в другую разрешенную кодовую комбинацию.
Существует связь между кодовым расстоянием d и минимальной кратностью ошибки q, которую код может обнаруживать:
d ≥ q + 1.
Пример 1. На базе кода из таблицы построить код, обнаруживающий ошибки кратности 2.
Для решения задачи воспользуемся схемой формирования кода Грея с некоторыми модификациями.
Поскольку код для обнаружения ошибки кратностью 1 построен, используем его для обозначения строк схемы, причем с каждой строкой свяжем символ, который соответствует данной кодовой комбинации: так с первой строкой свяжем символ a, со второй – b и т.д. Очевидно, кодовые комбинации в обозначении строк схемы различаются двумя разрядами.
Поскольку в ячейках этой схемы следует расположить символы, расстояние между кодовыми комбинациями которых должно быть не меньше 3, они должны быть расположены в соседних столбцах, чтобы обеспечивать различимость кодовых комбинаций еще как минимум в одном разряде (строки расположения символов обговорены выше).
С учетом сделанных замечаний схема имеет 4 столбца и 4 строки и представлена ниже:
| a | ||||
| b | ||||
| d | ||||
| c |
Таким образом, построен следующий код:
00000 → a, 01101 → b, 11011 → d, 10110 → c.
Определим кодовое расстояние d построенного кода. Поскольку dab = 3; dad = 4; dbd = 3; dac = 3; dbc = 4; dcd = 3, dmin = {3, 4, 3, 3, 4, 3} = 3.
Проверим, обнаруживает ли построенный код ошибку кратности 2. Для этого зададимся произвольной кодовой комбинацией, например, 01101 (символ b). Результат проверок приведен в таблице:
| Передаваемая кодовая комбинация | Ошибка | Принимаемая кодовая комбинация | Результат декодирования |
| Невозможно декодировать | |||
| То же | |||
| "-" | |||
| "-" | |||
| "-" | |||
| "-" | |||
| "-" | |||
| "-" | |||
| "-" | |||
| "-" |
Таким образом, задача решена.

