 2015-02-24
2015-02-24 345
345Все сказанное относительно этих пяти кнопок справедливо и для работы на других вкладках. Разумеется, в этом случае будет искаться не текст, а отдельные символы или объекты.
Кнопка Case Sensitive (С учетом регистра) позволяет искать написание слова, точно совпадающее с запросом по регистру написания букв. При нажатой кноп ке и запросе вася слова «Вася» и «ВАСЯ» найдены не будут.
При нажатой кнопке Whole Word (Целое слово) можно находить только законченные слова, соответствующие критерию поиска. Так, к примеру, программа по запросу «лук» с нажатой кнопкой не найдет слова «лука» и «луковый», поскольку в них с критерием совпадает только часть слова.
Однако «полезность» функции поиска и замены заключается не столько в возможности находить точно заданные фрагменты текста, сколько в возможности использования масок поиска или регулярных выражений (второй термин пришел из программирования). Говоря проще, вы можете задать неточный критерий поиска и найти все попадающие под него фрагменты. Соответственно, найденные фрагменты можно заменить или оформить каким-то образом.
Понять сущность поиска и замены с использованием масок поиска проще на очень легком примере. Предположим, что мы хотим найти в тексте все даты формата «1950 г.», «1951 г.», «1980 г.» и т. д. Нам нужно найти эти даты и выделить их красным цветом. Конечно же, эту задачу можно выполнить вручную – по очереди искать каждое новое число. Однако если диапазон дат в тексте – от 1950 до 1999 года, то нам придется повторить операцию поиска 50 раз, что, конечно же, несколько утомительно.
Внимание!
Здесь и далее будет использоваться написание в квадратных скобках и выделение курсивом для обозначения специальных символов.
Вместо этого можно отдать команду: найти все фрагменты текста, начинающиеся с цифр «1» и «9» и заканчивающиеся символами «[пробел] г.». Правда, такой поиск может найти все что угодно, например число «19» в начале текста и сокращение «г.» в конце. Поэтому нужно еще больше конкретизировать запрос и оформить его так: «19 [любой-символ][любой-символ][пробел] г.». Отдав команду найти все фрагменты текста, попадающие под запрос, и выделить их цветом, мы решим поставленную задачу.
Следует заметить, что созданный запрос все же не настолько точен, как хотелось бы. Например, если текст будет содержать последовательность символов «195, г. Москва», то текст «195, г.» будет найден и выделен (ведь и цифра «5», и запятая попадают под определение «любой символ»). Поэтому программы часто содержат несколько разных специальных символов для создания масок – чем их больше и чем они разнообразней, тем более точный запрос вы можете создать.
Например, запрос формата «19 [любая-цифра][любая-цифра][пробел] г.» будет более точным. А если бы мы исхитрились использовать определение вида «19 [любая-цифра-от-5-до-9][любая-цифра][пробел] г.», то ошибки были бы исключены, и даже «1915 год» не был бы выделен, поскольку третья цифра (единица) не попадет под заданное определение. Такие сложные запросы позволяет ис пользовать архитектура запросов POSIX и раздел поиска GREP, о котором мы в этой книге не говорим; приведем только пример записи подобного запроса, чтобы вы могли убедиться, что это действительно непросто (рис. 16.16); возможности же вкладки Text (Текст) скромнее, и с ее помощью такого запроса составить нельзя. При работе с вкладкой Text (Текст) Adobe InDesign позволяет использовать четыре символа для образования масок поиска, которые находятся в подменю поля поиска Wildcards (Переменные): Any Digit (Любая цифра), Any Letter (Любая буква), Any Character (Любой символ), White Space (Любой пробельный символ, включая табуляции).
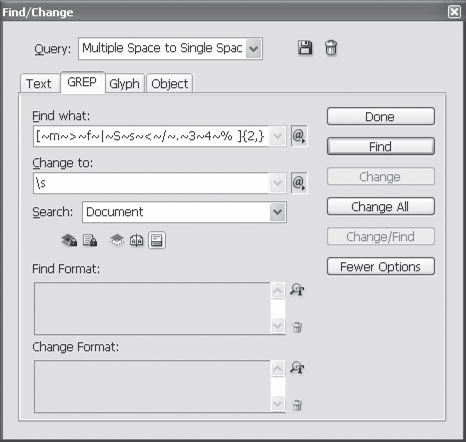
Рис. 16.16. Диалоговое окно Find/Change (Найти/Заменить), вкладка GREP
Процедуру поиска и замены можно и нужно использовать в процессе подготовки текста к верстке. В идеальном случае, как это уже говорилось, следует подготавливать текст перед импортом в Adobe InDesign в программе, где создавался текстовый файл; однако принципы использования масок поиска идентичны во всех редакторах, потому вы всегда сможете найти аналоги в других программах.
Рассмотренные в предыдущем разделе часто встречающиеся проблемы в тексте можно удалить проверенными способами. В большинстве случаев для этого потребуется несколько операций по поиску и замене, выполненных над одним текстом.
Если в тексте не используются специальные символы конца абзаца, то абзацы можно определить по пустой строке между ними или по пробелам или символу табуляции в начале абзаца. В обоих случаях задача – найти и удалить все символы конца абзаца, кроме правильных.
Если абзацы разделены пустой строкой, то сначала мы должны убедиться, что эта строка действительно пустая. В частности, в ней не должно быть пробелов – а они там часто могут встретиться. Следовательно, первым делом мы должны найти все строки, начинающиеся с пробела, и удалить этот пробел. В этом случае формат поиска будет выглядеть так – ^p^w, замены – ^p.
Поиск и замену следует повторить многократно, до тех пор, пока количество найденных и замененных случаев не будет равно нулю (если бы мы знали, сколько пробелов в пустых строках, можно было бы справиться быстрее, но мы не знаем этого точно – не считать же их по всему тексту).
Следующим шаг – найти все пустые строки. Теперь, когда они совсем пустые, в тексте они выглядят как знак «конец абзаца» сразу после другого знака «конец абзаца». Мы находим все двойные знаки абзаца (формат поиска – ^p^p) и заменяем их чем-нибудь таким, что никогда и ни при каких условиях не встретится в тексте (например, вот таким сочетанием: ==((АБЗАЦ))==) – чтобы потом случайно не заменить чем-нибудь нужным.
Следующий шаг – удаление всех знаков «конец абзаца» и замена их знаком «пробел». Просто удалять знаки «конец абзаца» нельзя, потому что это может привести к тому, что слова «сольются»; если же возникнут двойные пробелы, то их легко найти и удалить. В результате проведенной операции весь текст сольется в одну строку, но настоящие абзацы отмечены в тексте нашим сложным набором символов. Найдя его и заменив знаком «конец абзаца», мы закончим исправление абзацев в тексте.
Если абзацы отмечены пробелами или знаком табуляции, то алгоритм действий будет похож на предыдущий. Только в этом случае мы найдем все знаки табуляции (или цепочки пробелов) в начале абзаца и заменим их каким-нибудь набором символов, не встречающимся в тексте. Затем нужно удалить все знаки «конец абзаца» и заменить использованный набор символов знаком «конец абзаца».
Знаки кавычек можно исправить при использовании поиска и замены. В то время, как уникальный признак закрывающей кавычки придумать нельзя (перед ней может быть любой символ, а после нее пробел или знак препинания), открывающие кавычки всегда стоят после пробела. Найдя и заменив все знаки «фут» или «дюйм» после пробела открывающейся кавычкой, следующим шагом мы можем найти все оставшиеся знаки «фут» или «дюйм» и заменить закрывающейся кавычкой.
Знаки «тире» можно найти и исправить в несколько приемов. Тире использу ется при оформлении диалогов или как знак препинания. В первом случае найти и заменить легко: достаточно найти все знаки «дефис», стоящие в начале абзаца. Знак «тире» как знак препинания принято отделять от слов пробелами, и это подскажет, как его найти. Однако следует помнить, что иногда комбинация знаков «запятая» и «тире» пишется без пробела, поэтому может возникнуть необходимость искать отдельно знаки «дефис» после пробела и отдельно – знаки «дефис» перед пробелом. В обоих случаях желательно добавить пробелы вокруг знака «тире»; появляющиеся двойные пробелы убрать очень легко, зато добавление пробелов может исправить некоторые ошибки, например «прилипшие» к словам знаки.
Знаки переносов можно попытаться убрать нахождением и удалением (не заменой пробелом!) всех дефисов в конце строки (абзаца, если это текст в формате TXT). Однако при этом могут быть удалены и знаки «тире», поэтому нужно оформить запрос как «[любая-буква][дефис]». Тем не менее, после этого необходимо внимательно просмотреть весь текст на предмет неудаленных пробелов или случайно внесенных ошибок.








