2015-04-01
2015-04-01 2912
2912Индексирование текстов заключается в обработке документов, которые представлены в виде строк символов. Документы должны быть переведены в форму представления, пригодного для обработки алгоритмами классификации. Первичная подготовка текстов обычно происходит в следующей последовательности:
Сканируется документ, выделяются лексемы. Удаляются html-теги и другие присутствующие виды разметки
Удаляются стоп-слова.
Выделяются уникальные термы для всех документов.
Для каждого документа подсчитываем количество вхождений слов.
Используя эвристические критерии, удаляем слова, которые встречаются очень редко или очень часто, и несут мало информации о содержании документа.
После последней фильтрации, остается m термов, которым присваиваются идентификаторы от 1 до m, и n документов, которым присваиваются идентификаторы от 1 до n.
Стоп-слова – это часто встречающиеся слова, которые не несут полезной информации (местоимения, предлоги, союзы).
Вышеперечисленные шаги представляют простую схему обработки. Дополнительно, можно извлекать словосочетания, например, нижний новгород. Также можно уменьшать все слова до их корня или основы, это позволяет привести множество словоформ, имеющих различные суффиксы и окончания, к одному виду. Слова группируются в соответствии с их смысловым значением, например, слова работа, работать, работал, работая. Для выделения основ английского языка во многих работах используется алгоритм портера и другие подобные стеммеры. Русский язык имеет более развитую и сложную морфологию, поэтому актуальной является задача создания эффективного, в контексте информационного поиска, алгоритма выделения словарных основ для русского языка.
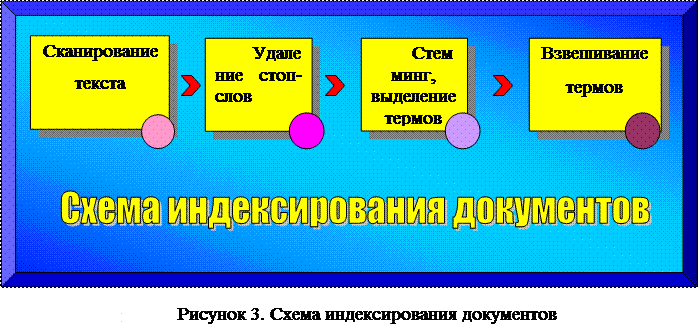
модели индексирования в целом похожи друг на друга и, как правило, имеют одинаковые блоки. Предлагается использовать следующую схему индексации (рис. 3).