 2015-05-05
2015-05-05 513
513Системы автоматического рубрицирования, основанные на обучении по примерам, рассматривают в качестве понятий, которым нужно обучиться, рубрики. Машинное обучение производится на основе примеров текстов, которые были заранее отрубрицированы экспертом вручную.
Можно выделить статистические и нейросетевые методы рубрицирования.
Идея статистического рубрицирования состоит в определении степени соответствия терминологического портрета документа и терминологического портрета рубрик на основе статистических характеристик субъектов сравнения. Под терминологическим портретом документа понимают совокупность наиболее важных терминов, содержащихся в тексте документа. В качестве показателя важности термина в документе чаще всего используется частота его встречаемости. Под терминологическим портретом рубрики понимается набор наиболее характерных для этой рубрики терминов с их весами (в работах 'по статистическим моделям рубрицирования под терминологическим портретом рубрики часто понимается множество ее характеристических терминов и частоты их встречаемости в рубрике). Таким образом, семантика рубрики задается однозначно только ее терминологическим портретом.
Отметим, что терминологический портрет можно рассматривать как частный случай тезауруса, имеющего более простую модель и допускающего его автоматическое построение и корректировку. Формирование терминологических портретов каждой рубрики производится экспертом не вручную, а с помощью одной из технологий обучения рубрикатора. При этом роль эксперта сводится к формированию для каждой рубрики обучающей выборки - совокупности максимально коротких фрагментов текстов, содержащих полное и минимально избыточное лингвистическое наполнение одной обучаемой рубрики.
Выделение характеристических терминов для рубрики производится автоматически, на основе их
весов, которые могут быть получены в процессе анализа обучающей выборки. Например, log rtrtrN wdf =
где r N - количество документов в обучающей выборке, принадлежащих рубрике r, tr df количество документов в обучающей выборке, принадлежащих рубрике r и содержащих термин t. Список характеристических терминов рубрики упорядочен по убыванию весов терминов в ней. Таким образом, единую модель для всех рубрик одного рубрикатора можно представить в виде двухмерной матрицы весов { } tk w. Рубрицирование выполняется по некоторому решающему правилу, учитывающему как важность терминов в документе, так и их веса для рубрик. Например, можно считать, что документ принадлежит рубрике r, если t tr r t tf w k > е
где t tf - частота встречаемости термина t в документе, r k - пороговое значение для рубрики r. Значение левой части указанного выражения может использоваться в качестве количественной оценки релевантности документов рубрикам.
Пороговые значения для каждой из рубрик определяются таким образом, чтобы при применении решающего правила ко всей обучающей выборке к данной рубрике было отнесено максимальное количество релевантных и минимальное количество не релевантных ей текстов. Вычисление может производиться как при помощи различных математических методов, так и эмпирическим путем. К достоинствам такого подхода относятся:
1. простота определения семантики рубрики, что дает возможность организовать автоматическое обучение рубрик;
2. универсальность подхода, заключающаяся в том, что таким способом может быть определена семантика очень широкого класса рубрик из любой предметной области;
3. наличие аппарата количественной оценки релевантности документов рубрикам;
4. высокое быстродействие.
Главным недостатком данной группы методов является более низкое по сравнению с методами, основанными на знаниях, качество рубрицирования.
Основой нейросетевых методов рубрицирования текстов является использование нейронной сети (НС) в качестве обучаемого классификатора. Считается, что в наличии имеется подборка примеров текстов, каждый из которых помечен как релевантный или нерелевантный определенной рубрике. Задача НС, обученной на этих примерах, состоит в определении степени релевантности любого нового текста данной рубрике. Данный подход предполагает, что семантика рубрики однозначно задается примерами принадлежащих ей текстов.
Поскольку НС оперирует векторами, для представления текста используется одна из векторных моделей, например: () 1,,: 1 0, 1,, a iD iiv d Tt t td T i D vN Ы О мп= н = = Ы П поK,
где D - мощность словаря;
i d — лексическая единица из словаря;
T - текст, рассматриваемый как неупорядоченное множество лексических единиц;
N - количество i d T О.
Поскольку обучающая выборка состоит из примеров с заранее известной принадлежностью текстов рубрикам, то имеет смысл использовать НС, в которых реализована парадигма обучения с учителем. Так, предлагается использовать вероятностную нейросеть (ВНС). НС имеет D входов и 2 выхода, один из которых отражает вероятность принадлежности предъявляемого текста к классу релевантных запросу текстов (Ррел), другой - к классу нерелевантных. На практике имеет смысл использовать лишь первый, поскольку сумма значений на выходах равна 1. Схематично описываемый процесс представлен на рис. 8 и рис. 9.
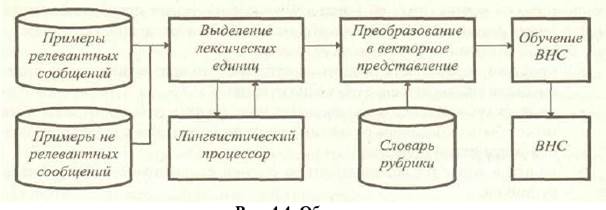
Рис. 8. Обучение
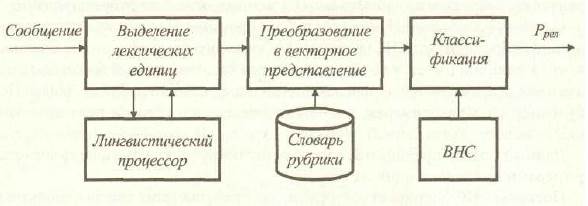
Рис. 9. Определение вероятности релевантности текста рубрике
Словарь рубрики могут составлять как простые, так и составные термины. Его формирование производится так же, как и в статистических методах, с той лишь разницей, что веса терминов в дальнейшем не используются.
По качеству рубрицирования нейросетевые методы рубрицирования занимают среднее положение между статистическими методами и методами, основанными на знаниях.
К основным недостаткам нейронных сетей чаще всего относят два факта:
1.Экспертам непонятно, как нейронная сеть работает.
2.На обучение сети требуется очень много времени.
Однако ВНС выгодно отличается тем, что имеет:
1.строгое математическое обоснование (по сути ВНС представляет собой оптимальный по Байесу классификатор);
2.огромное (в тысячи раз большее) по сравнению с другими нейросетевыми парадигмами быстродействие.
Кроме того, характер решаемой задачи позволяет существенно оптимизировать ВНС, а также устранить зависимость объема вычислений от мощности словаря. Этот факт позволяет полностью отказаться от усечения словаря, опасного тем, что в ходе его могут быть отброшены существенные для классификации термины. В целом, выбор данной нейросетевой парадигмы позволяет свести к минимуму указанные недостатки








