 2015-04-23
2015-04-23 3530
3530Потребность в использовании выборочного метода, выработке вероятностных суждений в современной отечественной практике непрерывно расширяется. В государственной статистике основными направлениями использования выборочного метода традиционно являются бюджетные обследования домохозяйств, выборочные переписи населения, контрольные обходы и проверки после проведения сплошных обследований.
Создание ЕГРПО, в котором фиксируются все хозяйствующие субъекты на территории Российской Федерации всех форм собственности, открывает возможность проведения разнообразных выборочных обследований в области экономики.
В области социальных исследований для государственной статистики главным является бюджетное обследование, которое охватывает примерно 45 тыс. домохозяйств. Оно основано на многоступенчатом отборе. Общий объем выборки распределяется по сферам занятости (для работающих) и территориям. Затем для работающих проводится отбор предприятий в пределах каждой отрасли в отобранной территории. Если, например, нужно отобрать 100 рабочих, занятых в определенной отрасли, для обследования семейных бюджетов так, чтобы на каждом отобранном предприятии было не менее 20 бюджетов, включающих рабочих с разным уровнем заработной платы, то, значит, должно быть отобрано: 100: 20 = 5 предприятий. Отбор предприятий проводят по списку, в котором предприятия располагаются в порядке убывания средней заработной платы рабочих, указываются общее число рабочих, их суммарная заработная плата. Шаг отбора определяется делением общего числа рабочих на предприятиях данной отрасли на число отбираемых предприятий. Если всего на предприятиях данной отрасли в области занято 30525 человек, то шаг отбора равен: 30525: 5 = 6105. По данным кумулятивной численности рабочих с рассчитанным шагом отбора проводится отбор предприятий, которые затем проверяются на репрезентативность по показателю средней месячной заработной платы. Следующая стадия связана с отбором рабочих на выбранных предприятиях: среди 20 бюджетов должны быть пропорционально представлены бюджеты семей малоквалифицированных и высококвалифицированных рабочих, а среди этих категорий отбор проводится механически по спискам рабочих, составленным в порядке убывания средней месячной заработной платы. Выборочная совокупность при бюджетных обследованиях включает и семьи неработающих (пенсионеров, студентов, инвалидов) и одиночек.
Задачей статистики в области бюджетных обследований являются обеспечение представительства всех социальных групп и учет всех источников дохода. Наиболее общим показателем уровня благосостояния населения являются денежные доходы, поступающие в семью в виде заработной платы, премий, единовременных выплат, гонораров, предпринимательского дохода или дохода от собственности, компенсационных выплат и дотаций. В совокупные доходы семьи включаются также натуральная оплата труда, доходы, полученные от реализации и потребления продукции личного подсобного хозяйства (садового участка, коллективного огорода). Для характеристики обеспеченности семей следует учитывать их накопления, а также валютные поступления. Возрастает значение анализа личного потребления.
Для изучения структуры рабочего времени работников разных категорий, особенно рабочих, а также для характеристики использования машин и оборудования используется метод моментных наблюдений, предложенный в 1938 г. Типпетом. Сущность метода моментных наблюдений состоит в периодической фиксации состояний наблюдаемых единиц в заранее установленные или случайно выбранные моменты времени.
Различают моментное наблюдение со случайным отбором мо ментов и периодическое моментное наблюдение. В первом случае момент наблюдения (час и минуту) выбирают с помощью таблиц случайных чисел. Периодическое моментное наблюдение организуется по аналогии с механическим отбором: наблюдение состояний процесса осуществляется через определенные промежутки времени.
При подготовке к проведению моментных наблюдений необходимо разработать перечень различных возможных состояний наблюдаемых объектов (например, элементов сменного фонда рабочего времени). Степень детализации элементов затрат рабочего времени или причин простоев и видов работы оборудования зависит от поставленной задачи. Если требуется получить общую информацию, достаточно выделить 3-4 вида простоев и работ.
В тех случаях, когда требуется детальная разработка данных о причинах простоев, необходима более развернутая классификация элементов фонда рабочего времени. Элементы классификации должны быть четко сформулированы, не повторяться и иметь достаточный удельный вес, чтобы представлять интерес для анализа. В практике применения моментных наблюдений следует выделять только те элементы затрат времени, которые имеют удельный вес не менее 5%, поскольку в противном случае резко увеличивается необходимый объем наблюдений.
Число моментов, в которые производится фиксация состояний процесса, определяется на основе формулы предельной ошибки доли
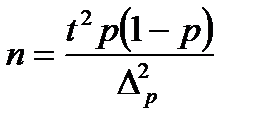 (9.1)
(9.1)
где р - доля данного вида потерь в сменном фонде времени[1],
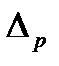 - абсолютная величина предельной ошибки выборочной доли.
- абсолютная величина предельной ошибки выборочной доли.
Величину предельной ошибки чаще задают в относительной форме, т.е. задаются величиной:
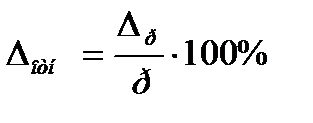 (9.2а)
(9.2а)
откуда
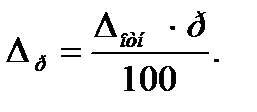 (9.2б)
(9.2б)
Тогда необходимое число наблюдений определится по формуле
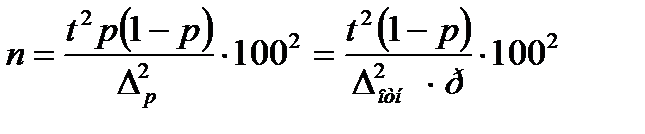 (9.2в)
(9.2в)
В соответствии с рассчитанным числом человеко-моментов и численностью обследуемых рабочих в данной группе устанавливается необходимое число обходов как частное от деления количества наблюдений на число рабочих, подлежащих обследованию.
Далее встает вопрос о количестве смен, на которые должно быть распределено общее количество обходов. Для ответа на этот вопрос нужно знать продолжительность одного обхода. Так как наблюдатель должен обходить все рабочие места по заранее установленному маршруту, продолжительность одного обхода может быть установлена с достаточной точностью с учетом затрат времени на соответствующие записи и перемещение наблюдателя.
Допустим, что наблюдение проводится на участке цеха, где в смену работает 30 человек. Поставлена задача - выявить важнейшие причины потерь рабочего времени. По данным фотографий рабочего дня известно, что удельный вес потерь рабочего времени по различным причинам составляет не менее 5%, т.е. р = 0,05. Приняв 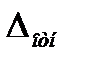 равной 10%, получим, что необходимое число моментов наблюдения равно 7600.
равной 10%, получим, что необходимое число моментов наблюдения равно 7600.
Отсюда общее количество обходов равно 254 (7600:30=253,3). Выполнить указанное количество обходов за одну смену практически невозможно, так как это означало бы, что каждая последующая запись должна быть сделана примерно через 2,0 минуты [(8,0·60):254=1,89].
В действительности, затраты времени на один обход составляют по предварительным прикидкам примерно 7 мин, таким образом за смену может быть сделано не более 69 обходов (480:7=68,6). Если принять во внимание, что в некоторых случаях наблюдателю потребуется дополнительное время на выяснение причин простоя, то минимально необходимое время на один обход следует принять равным 10 мин.
Тогда за смену наблюдатель сможет сделать 48 обходов (480:10=48,0), а чтобы выполнить все необходимое число обходов, потребуется не менее 5 смен (254:48=5,3). Таким образом, в нашем примере наблюдение целесообразно проводить ежедневно на протяжении всей рабочей недели (иногда целесообразно провести наблюдение и за более длительный период времени, уменьшив ежедневное число обходов).
Выбор сроков проведения наблюдения обычно должен опираться на дополнительную информацию о закономерностях хода процесса. Наличие известной неравномерности в загрузке оборудования и рабочих всегда имеет место на протяжении рабочих дней недели, а потому выбор пятидневки в качестве периода наблюдения позволит получить более достоверную картину распределения затрат рабочего времени.
Следующим этапом в организации моментного наблюдения является составление графика проведения наблюдений, т.е. речь идет о выборе моментов времени, в которые должны быть сделаны соответствующие записи по наблюдаемым единицам.
С организационной точки зрения часто более удобно использование периодического моментного наблюдения. В этом случае наблюдение состояний процесса осуществляется через определенные промежутки времени. В нашем примере наблюдатель должен подходить к одному и тому же рабочему месту через каждые 10 мин. В случайном порядке отбирается только момент времени, в который должно начинаться наблюдение. Допустим, что смена начинается в 7 час. 30 мин. С помощью жеребьевки установили, что первый обход начинается в 7 час. 34 мин., тогда второй обход в 7 час. 44 мин. третий - в 7 час. 54 мин. и т.д.
Применение периодического моментного наблюдения позволяет получить сведения об использовании рабочего времени на данном участке на протяжении всей смены, тогда как при применении случайного отбора моментов принципиально возможны случаи, когда какой-то из часов смены совсем выпадает из рассмотрения. Для выявления же, например, случаев нарушения трудовой дисциплины (в связи с поздним началом работы и ранним окончанием ее) особенно важно получить сведения и в начале, и в конце смены.
Выборочный метод применяется в аудиторской практике при проверке бухгалтерских документов. При этом решаются две задачи: 1) оценка количества документов в данной фирме (предприятии, объединении и т.д.), в оформлении которых не соблюдались принятые правила; 2) оценка правильности указанных в документах сумм денежных средств. Первую задачу решают с помощью так называемой атрибутивной выборки, вторую — монетарной выборки. В первой выборке единицей отбора является учетный документ, во второй — денежная единица.
При организации атрибутивной выборки в качестве генеральной совокупности выступает вся совокупность расчетных документов фирмы за проверяемый период. Обычно она предварительно разбивается на однородные массивы — по характеру документов, по центрам ответственности, по географическому признаку, по временной последовательности, по интенсивности запросов на данный вид информации и т.д. Каждому документу присваивается числовая метка, и по таблице случайных чисел проводится отбор номеров в количестве, соответствующем объему выборки. Можно провести и механический отбор с шагом отбора, равным N: n, где N — объем генеральной совокупности, n — объем выборки. Обычно начинают отбор не с первого документа, а отступив полшага.
Объем атрибутивной выборки находится из соотношения

Коэффициент надежности определяется по таблице распределения Пуассона, поскольку появление ошибки в оформлении расчетных документов относится к классу редких событий. При этом предполагаемая средняя частота ошибок закрепляется на определенном уровне, например 1, 1,5 или 2.
Если фактическая частота несоответствий в оформлении документов меньше максимально допустимой, то вычисляют коэффициент надежности как произведение объема выборки на величину фактической частоты несоответствий, после чего по таблице распределения Пуассона определяют вероятность, соответствующую рассчитанной величине коэффициента надежности, чтобы убедиться, что доверительная вероятность результатов выборки достаточно высока.
Если фактически выявленная частота несоответствия превышает максимально допустимую величину, то обязательно проводят монетарную выборку.
При монетарной выборке генеральной совокупностью является сумма денежных средств, зафиксированных во всех проверяемых документах. В качестве единицы отбора выступает денежная единица (1 руб.), а единицей наблюдения является расчетный документ. Требуемая точность результатов задается как допустимая относительная сумма ошибки. Объем монетарной выборки рассчитывается как
 .
.
Например, если аудитор исходит из 1%-ного риска (при односторонней критической области из опасения, что суммарная ошибка будет не больше принятой величины), т.е. при 98%-ной доверительной вероятности наличия суммарной ошибки 50000 руб., при объеме генеральной совокупности, равном 60 млн руб., то объем выборки
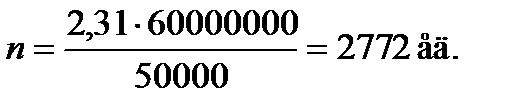
Определяется шаг отбора, равный N: п = 60000000: 2772 = = 21645 руб. Все расчетные документы, в которых зафиксирована сумма, равная или превышающая величину шага отбора, обязательно попадут в выборку. Начало отбора устанавливается произвольно.
Пример. Рассмотрим записи по счету «Расчеты с покупателями» (табл. 9.1).
Приведенный пример показывает, что число отобранных документов может быть значительно меньше объема выборки по числу отбираемых денежных единиц. Если сумма операций многократно превышает шаг отбора, мы получаем несколько раз указание на необходимость проверки этой операции (в примере операция № 5 получила представительство в выборке шесть раз), и, наоборот, если сумма операции меньше шага отбора, она может не попасть в выборку (операция № 4). В целом чем крупнее операции по сравнению с шагом отбора, тем меньше будет совокупность отобранных документов — единиц наблюдения по сравнению с числом отобранных единиц.
Таблица 9.1
Формирование монетарной выборки, руб.
(в качестве начала отбора принято 25000 руб.,
шаг отбора равен 21645 руб.)
| Номер операции | Сумма | Нарастающий итог | Отбираемая единица |
| . . . | . . . | . . . | − − . . . |
Решение вопросов по определению репрезентативности выборки и распространению ее результатов на генеральную совокупность зависит от того, были ли выявлены ошибки в выборке или нет. Это влияет на значение коэффициента надежности: сохранится оно или не сохранится. Исходя из этого проводится проверка соответствия фактической точности тому значению максимально допустимой суммарной величины ошибки, которое закладывалось при проектировании выборки. Если фактическая ошибка меньше или равна принятой, то выборка признается репрезентативной, если превышает ее, то применяются специальные методы оценки данных. Проверка проводится на основе соотношения
 ,
,
отсюда: 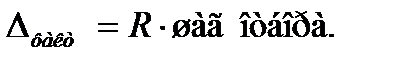
Если при проверке отобранных документов ошибок не обнаружено, то с принятой доверительной вероятностью мы можем распространить результаты выборки на всю генеральную совокупность и считать, что итог по генеральной совокупности завышен не более чем на величину предельно допустимой ошибки. Если же обнаружена по крайней мере одна ошибка, то первоначальная гипотеза относительно отсутствия ошибок, которая закладывалась при планировании выборки, оказывается несостоятельной. В этом случае должны быть пересмотрены либо значение коэффициента надежности, либо величина предельно допустимой ошибки (точность), либо и то, и другое. Если ошибки выявлены в операциях, значение которых превышает величину шага отбора, то можно быть уверенным в отношении абсолютного размера ошибок в таких операциях, так как каждая из них проверялась полностью. В этом случае нужно решить вопрос о распространении абсолютного размера выявленных ошибок на операции, значение которых меньше шага отбора.
Все ошибки группируются в два класса: завышение суммы и ее занижение. Для всех операций, значение которых превышает шаг отбора, выявленная ошибка является точным размером завышения или занижения. Для операций, значение которых меньше шага отбора, размер выявленной ошибки относится к значению операции, и полученная относительная ошибка умножается на шаг отбора, т.е. распространяется на весь интервал (табл. 9.2).
После определения суммарного размера ожидаемой ошибки по всем интервалам выборки (т.е. шагам отбора) проводится сравнение с допустимым размером суммарной ошибки, и если рассчитанная суммарная ошибка превосходит допустимую величину, то, подставляя последнюю в формулу объема выборки, определяют, с каким коэффициентом надежности и соответственно с какой доверительной вероятностью могут гарантироваться результаты данного выборочного исследования:
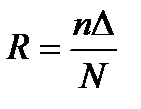 .
.
Таблица 9.2
Расчет суммарной ошибки на основе распространения результатов
выборки, руб.
| Характер и размер ошибки | Шаг отбора | Значение операции | Ожидаемый размер ошибки в интервале выборки |
| Завышение | 291,21 (установленный размер ошибки 1,35% распространен на весь интервал) | ||
| Итого 2750 | 2791,21 | ||
| Занижение . . . | . . . | . . . | 432,90 . . . |
Как известно, в экономических исследованиях обычно принимают доверительную вероятность не ниже 90%.
Использование выборочного метода в работе аудитора резко повышает эффективность получения результатов и приводит к экономии финансовых и трудовых затрат.
Еще одним объектом применения выборочного метода является малый бизнес. В нашей стране работа по организации и проведению выборочного наблюдения малых предприятий включает следующие основные этапы.
1. Создание базы данных как основы выборки (базовой совокупности). Базовая совокупность (БС) включает список предприятий, определяемый рамками обследования малых предприятий, с набором показателей, полученных из единой генеральной совокупности (ГС). Начиная с 1998 г. для проведения выборочных обследований субъектов малого бизнеса формируется одна базовая совокупность единиц наблюдения (на основе генеральной совокупности объектов статистического наблюдения). Базовая совокупность создается раз в год и фиксируется по состоянию на 31 декабря предшествующего года. Базовая совокупность включает актуализированные в части фактического основного вида деятельности признаки титульно-адресной части зарегистрированных в ЕГРПО малых предприятий, за исключением прекративших или приостановивших свою деятельность, и показатель выручки из бухгалтерской отчетности за год t = 2 (в 2006г. за 2004 г. и т.д.).
2. Формирование выборочной совокупности. Выборочная совокупность формируется на основе БГС методом стратифицированного случайного отбора с оптимизацией по Нейману. Выборочная совокупность формируется раз в год и фиксируется. При планировании выборок расслоение на региональном уровне (разделение на подсовокупности) базовой совокупности осуществляется по следующим признакам:
• ОКОНХ (на 62 страты);
• КФС (на 4 страты);
• ВЫРУЧКА (на 5 страт).
Показателем оптимизации является выручка. Если число единиц наблюдения в БГС невелико, то число страт по переменной «выручка» может быть уменьшено, и, наоборот, если в БГС значительное число единиц наблюдения (более 5000— 7000), то число страт по переменной «выручка» может быть увеличено.
Объем выборки рассчитывается вычислительным комплексом автоматически при условии, что предельная ошибка по показателю «выручка» не должна превышать 5%-ный уровень.
3. Сбор и ввод (импорт) текущих данных отчетности по выборке. Собранные данные вводятся и контролируются средствами электронных версий формы № - ПМ с последующим вводом в вычислительный комплекс выборочного наблюдения.
4. Обработка полных неответов (восстановление пропусков). Практически при всех обследованиях предприятий имеются неответы респондентов опросного списка. Очень редко неответы бывают случайными. Систематические неответы могут вызвать смещение в оценках показателей в конкретном обследовании. При проведении статистических обследований различают два вида пропусков в данных: полные неответы — если в составе бланков форм отчетности с данными полностью отсутствуют результаты обследования по единице наблюдения. Частичный неответ или пропуск — при отсутствии данных не в целом по единице наблюдения, а лишь по некоторым пунктам формуляра наблюдения. К частичным пропускам относят также ошибочные и некорректные ответы, которые могут быть внесены в бланк с данными в силу непонимания вопроса, неточности или просто невнимательности. Для обработки полных неответов респондентов совокупность неответивших предприятий должна быть разделена на три следующие группы:
• первая — предприятия, данные по которым восстанавливаться не будут. К ним относятся предприятия, ликвидированные или находящиеся в стадии ликвидации, так называемые спящие, т.е. приостановившие свою деятельность в силу различных причин;
• вторая — предприятия, о которых достоверно известно, что они, несмотря на отсутствие отчета, активны, ведут финансово-хозяйственную деятельность;
• третья — предприятия, по которым нет никаких данных и даже сведений, действующие они или нет.
К каждой группе полных неответов применяется свой метод коррекции и восстановления данных. Используются следующие методы восстановления пропусков:
• заполнение с пристрастным подбором;
• заполнение по предыдущему значению;
• заполнение без подбора;
• заполнение средними;
• заполнение с помощью регрессии;
• замена.
Заполнение с пристрастным подбором означает поиск данных, относящихся к единицам определенного типа.
Заполнение по предыдущему значению часто используется в современной практике. Но этот метод не рекомендуется применять при большом количестве пропусков, а также при наличии тенденции изменения показателя и значительном сроке со дня последней регистрации значения.
Заполнение безусловными средними. По имеющимся наблюдениям рассчитываются средние, и существующий пропуск заполняется средними значениями. Этот метод эффективен при однородности анализируемой совокупности и небольшом количестве пропусков.
Заполнение с помощью регрессии состоит в заполнении пропусков значениями, предсказываемыми регрессией пропущенных для данного объекта переменных на основе присутствующих. Регрессия вычисляется по объектам с полной информацией. Этот метод выдвигает ряд серьезных требований к данным: однородность, поскольку известно, что при использовании метода наименьших квадратов небольшое число грубых ошибок может весьма существенно исказить значение характеристики распределения; подчинение теоретическому нормальному распределению, что требует дополнительной обработки информации.
5. Досчет на вновь зарегистрированные предприятия. Записи о вновь зарегистрированных предприятиях добавляются к выборочной совокупности, и коэффициент увеличения численности используется как коэффициент досчета по всем показателям.
6. Распространение результатов выборочного наблюдения на генеральную совокупность проводится по методике, рассмотренной выше.
7. Анализ и экспертная корректировка полученных результатов. За качество передаваемой на федеральный уровень информации отвечает соответствующая территория (субъект РФ или федеральный округ). Достоверность отчетности зависит только от квалификации исполнителя и желания добросовестно сделать свою работу.
Решению проблем, связанных прежде всего с проблемами организации и проведения выборочных обследований малых предприятий на региональном уровне, посвящена разработка подпроекта Программы TACIS «Статистика-3». Особое внимание уделялось вопросам подготовки анкеты выборочного наблюдения, составу и структуре содержащихся в ней показателей, а также концепциям формирования выборки на региональном уровне.
Большая проблема для российской статистики состоит в выявлении и обработке данных нетипичных единиц наблюдения. Несмотря на достаточно эффективный план выборки проводимого обследования, при детальном анализе данных на региональном и федеральном уровнях неоднократно выявлялись единицы, включение (или исключение) которых в выборочную совокупность сильно влияет на итоговое значение получаемых оценок показателей и в конечном счете отражается на качестве результатов обследования.
Нетипичные единицы определяются как:
• имеющие экстремальные значения показателей;
• влияющие на конечную оценку из-за своего большого выборочного веса;
• имеющие сложную структуру или находящиеся в процессе структурной перестройки.
Для выявления и оценки влияния нетипичных единиц на конечные значения показателей обследования используются следующие методы:
• графический метод — прост в исполнении, но может применяться только в случае небольших объемов совокупности единиц наблюдения;
• квартильный метод — удобный и широко используемый на практике. Суть его заключается в построении с помощью медианы межквартильных рангов границ предельно допустимого интервала. Единицы, значения признаков которых попадают за рамки этого интервала, являются нетипичными;
• агрегированный контроль — этап обработки индивидуальных данных, проводимый перед распространением результатов наблюдения на исследуемую совокупность. В качестве показателей для агрегированного контроля в обследовании малых предприятий по форме №-ПМ выбираются: выручка, численность занятых, фонд заработной платы, а также выручка/численность, фонд заработной платы/численность. Если предприятие не прошло агрегированный контроль, то оно заносится в перечень для представления руководителю обследования, исправляющему или подтверждающему данные по этому предприятию. Далее осуществляется индивидуальный контроль только за выявленными единицами.
Агрегированный контроль можно назвать макроэкономическим, так как в процессе его проведения используются соотношения показателей не на индивидуальном уровне, а на уровне страны, отрасли.
При больших объемах первичной информации методика выявления нетипичных единиц с применением пакета SPSS, разработанная Госкомстатом России, может служить дополнительным контролем при разработке итогов обследований малых предприятий.
Таблица 9.3
Демография организаций
в сентябре 2009 года
| Количество вновь зарегистрированных организаций | Количество официально ликвидированных организаций | |||
| всего | на 1000 организаций, учтенных в Статистическом регистре Росстата | всего | на 1000 организаций, учтенных в Статистическом регистре Росстата | |
| Российская Федерация | 7,6 | 3,0 | ||
| Центральный федеральный округ | 7,8 | 2,5 | ||
| Белгородская область | 8,0 | 2,8 | ||
| Брянская область | 6,0 | 4,5 | ||
| Владимирская область | 7,1 | 2,5 | ||
| Воронежская область | 6,5 | 3,1 | ||
| Ивановская область | 9,0 | 4,4 | ||
| Калужская область | 7,0 | 1,8 | ||
| Костромская область | 4,7 | 1,4 | ||
| Курская область | 5,7 | 3,6 | ||
| Липецкая область | 8,0 | 5,7 | ||
| Московская область | 7,3 | 1,1 | ||
| Орловская область | 6,4 | 6,2 | ||
| Рязанская область | 5,9 | 3,9 | ||
| Смоленская область | 6,2 | 4,4 | ||
| Тамбовская область | 8,0 | 5,4 | ||
| Тверская область | 6,6 | 3,0 | ||
| Тульская область | 6,3 | 3,3 | ||
| Ярославская область | 7,7 | 2,8 | ||
| г.Москва | 8,4 | 2,4 |
Значительной сферой применения выборочного наблюдения являются маркетинговые исследования, проводимые с целью оценки мощности рынков товаров и услуг, определения специфических сегментов рынка.
Применяется выборочный метода и при изучении общественного мнения, в ряде стран он уже имеет свою историю. С 1935 г. в США организацией опросов общественного мнения с применением научных методов занимается Американский институт общественного мнения, который основал Джордж Гэллап. Опросы Гэллапа проводятся два раза в неделю по разнообразным политическим, социальным и экономическим проблемам. Результаты национальных обследований, регулярно проводимых Институтом Гэллапа, основываются, как правило, на персональных интервью с минимумом опрашиваемых (примерно 1500 человек). После разбивки страны по территориальному признаку и по числу проживающих в целях соответствия выборки фактическому распределению населения в случайном порядке отбираются районы в пределах города или округа. В каждом случайно отобранном пункте проводится приблизительно пять интервью в определенных, отобранных на случайной основе домах. В каждом доме интервьюер обращается к самому молодому мужчине или же, если таковой отсутствует, к самой пожилой женщине.
В нашей стране также действуют различные центры но изучению общественного мнения, в частности население широко знакомится с результатами опросов в ходе различных выборных кампаний. Вместе с тем нужно отметить, что практика проведения подобных опросов населения нуждается в совершенствовании и необходимо более четкое их теоретическое обоснование, так как результаты выборов и прогнозы различных центров имели нередко весьма существенные расхождения.
Приложение 1
Таблица значений функции Лапласа при разных значениях t
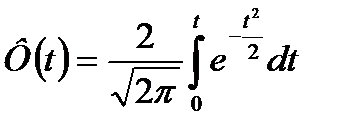
| t | Ф(t) | t | Ф(t) | t | Ф(t) | t | Ф(t) | t | Ф(t) | t | Ф(t) |
| 0,00 | 0,0000 | 0,50 | 0,1915 | 1,00 | 0,3413 | 1,50 | 0,4332 | 2,00 | 0,4772 | 3,00 | 0,49865 |
| 0,01 | 0,0040 | 0,51 | 0,1950 | 1,01 | 0,3438 | 1,51 | 0,4345 | 2,02 | 0,4783 | 3,20 | 0,49931 |
| 0,02 | 0,0080 | 0,52 | 0,1985 | 1,02 | 0,3461 | 1,52 | 0,4357 | 2,04 | 0,4793 | 3,40 | 0,49966 |
| 0,03 | 0,0120 | 0,53 | 0,2019 | 1,03 | 0,3485 | 1,53 | 0,4370 | 2,06 | 0,4803 | 3,60 | 0,499841 |
| 0,04 | 0,0160 | 0,54 | 0,2054 | 1,04 | 0,3508 | 1,54 | 0,4382 | 2,08 | 0,4812 | 3,80 | 0,499928 |
| 0,05 | 0,0199 | 0,55 | 0,2088 | 1,05 | 0,3531 | 1,55 | 0,4394 | 2,10 | 0,4821 | 4,00 | 0,499968 |
| 0,06 | 0,0239 | 0,56 | 0,2123 | 1,06 | 0,3554 | 1,56 | 0,4406 | 2,12 | 0,4830 | 4,50 | 0,499997 |
| 0,07 | 0,0279 | 0,57 | 0,2157 | 1,07 | 0,3577 | 1,57 | 0,4418 | 2,14 | 0,4838 | 5,00 | 0,499997 |
| 0,08 | 0,0319 | 0,58 | 0,2190 | 1,08 | 0,3599 | 1,58 | 0,4429 | 2,16 | 0,4846 | ||
| 0,09 | 0,0359 | 0,59 | 0,2224 | 1,09 | 0,3621 | 1,59 | 0,4441 | 2,18 | 0,4854 | ||
| 0,10 | 0,0398 | 0,60 | 0,2257 | 1,10 | 0,3643 | 1,60 | 0,4452 | 2,20 | 0,4861 | ||
| 0,11 | 0,0438 | 0,61 | 0,2291 | 1,11 | 0,3665 | 1,61 | 0,4463 | 2,22 | 0,4868 | ||
| 0,12 | 0,0478 | 0,62 | 0,2324 | 1,12 | 0,3686 | 1,62 | 0,4474 | 2,24 | 0,4875 | ||
| 0,13 | 0,0517 | 0,63 | 0,2357 | 1,13 | 0,3708 | 1,63 | 0,4484 | 2,26 | 0,4881 | ||
| 0,14 | 0,0557 | 0,64 | 0,2389 | 1,14 | 0,3729 | 1,64 | 0,4495 | 2,28 | 0,4887 | ||
| 0,15 | 0,0596 | 0,65 | 0,2422 | 1,15 | 0,3749 | 1,65 | 0,4505 | 2,30 | 0,4893 | ||
| 0,16 | 0,0636 | 0,66 | 0,2454 | 1,16 | 0,3770 | 1,66 | 0,4515 | 2,32 | 0,4898 | ||
| 0,17 | 0,0675 | 0,67 | 0,2486 | 1,17 | 0,3790 | 1,67 | 0,4525 | 2,34 | 0,4904 | ||
| 0,18 | 0,0714 | 0,68 | 0,2517 | 1,18 | 0,3810 | 1,68 | 0,4535 | 2,36 | 0,4909 | ||
| 0,19 | 0,0753 | 0,69 | 0,2549 | 1,19 | 0,3830 | 1,69 | 0,4545 | 2,38 | 0,4913 | ||
| 0,20 | 0,0793 | 0,70 | 0,2580 | 1,20 | 0,3849 | 1,70 | 0,4554 | 2,40 | 0,4918 | ||
| 0,21 | 0,0832 | 0,71 | 0,2611 | 1,21 | 0,3869 | 1,71 | 0,4564 | 2,42 | 0,4922 | ||
| 0,22 | 0,0871 | 0,72 | 0,2642 | 1,22 | 0,3883 | 1,72 | 0,4573 | 2,44 | 0,4927 | ||
| 0,23 | 0,0910 | 0,73 | 0,2673 | 1,23 | 0,3907 | 1,73 | 0,4582 | 2,46 | 0,4931 | ||
| 0,24 | 0,0948 | 0,74 | 0,2703 | 1,24 | 0,3925 | 1,74 | 0,4591 | 2,48 | 0,4934 | ||
| 0,25 | 0,0987 | 0,75 | 0,2734 | 1,25 | 0,3944 | 1,75 | 0,4599 | 2,50 | 0,4938 | ||
| 0,26 | 0,1026 | 0,76 | 0,2764 | 1,26 | 0,3962 | 1,76 | 0,4608 | 2,52 | 0,4941 | ||
| 0,27 | 0,1064 | 0,77 | 0,2794 | 1,27 | 0,3980 | 1,77 | 0,4616 | 2,54 | 0,4945 | ||
| 0,28 | 0,1103 | 0,78 | 0,2823 | 1,28 | 0,3997 | 1,78 | 0,4625 | 2,56 | 0,4948 | ||
| 0,29 | 0,1141 | 0,79 | 0,2852 | 1,29 | 0,4015 | 1,79 | 0,4633 | 2,58 | 0,4951 | ||
| 0,30 | 0,1179 | 0,80 | 0,2881 | 1,30 | 0,4032 | 1,80 | 0,4641 | 2,60 | 0,4953 | ||
| 0,31 | 0,1217 | 0,81 | 0,2910 | 1,31 | 0,4049 | 1,81 | 0,4649 | 2,62 | 0,4956 | ||
| 0,32 | 0,1255 | 0,82 | 0,2939 | 1,32 | 0,4066 | 1,82 | 0,4656 | 2,64 | 0,4959 | ||
| 0,33 | 0,1293 | 0,83 | 0,2967 | 1,33 | 0,4082 | 1,83 | 0,4664 | 2,66 | 0,4961 | ||
| 0,34 | 0,1331 | 0,84 | 0,2995 | 1,34 | 0,4099 | 1,84 | 0,4671 | 2,68 | 0,4963 | ||
| 0,35 | 0,1368 | 0,85 | 0,3023 | 1,35 | 0,4115 | 1,85 | 0,4678 | 2,70 | 0,4965 | ||
| 0,36 | 0,1406 | 0,86 | 0,3051 | 1,36 | 0,4131 | 1,86 | 0,4686 | 2,72 | 0,4967 | ||
| 0,37 | 0,1443 | 0,87 | 0,3078 | 1,37 | 0,4147 | 1,87 | 0,4693 | 2,74 | 0,4969 | ||
| 0,38 | 0,1480 | 0,88 | 0,3106 | 1,38 | 0,4162 | 1,88 | 0,4699 | 2,76 | 0,4971 | ||
| 0,39 | 0,1517 | 0,89 | 0,3133 | 1,39 | 0,4177 | 1,89 | 0,4706 | 2,78 | 0,4973 | ||
| 0,40 | 0,1554 | 0,90 | 0,3159 | 1,40 | 0,4192 | 1,90 | 0,4713 | 2,80 | 0,4974 | ||
| 0,41 | 0,1591 | 0,91 | 0,3186 | 1,41 | 0,4207 | 1,91 | 0,4719 | 2,82 | 0,4976 | ||
| 0,42 | 0,1628 | 0,92 | 0,3212 | 1,42 | 0,4222 | 1,92 | 0,4726 | 2,84 | 0,4977 | ||
| 0,43 | 0,1664 | 0,93 | 0,3238 | 1,43 | 0,4236 | 1,93 | 0,4732 | 2,86 | 0,4979 | ||
| 0,44 | 0,1700 | 0,94 | 0,3264 | 1,44 | 0,4251 | 1,94 | 0,4738 | 2,88 | 0,4980 | ||
| 0,45 | 0,1736 | 0,95 | 0,3289 | 1,45 | 0,4265 | 1,95 | 0,4744 | 2,90 | 0,4981 | ||
| 0,46 | 0,1772 | 0,96 | 0,3315 | 1,46 | 0,4279 | 1,96 | 0,4750 | 2,92 | 0,4982 | ||
| 0,47 | 0,1808 | 0,97 | 0,3340 | 1,47 | 0,4292 | 1,97 | 0,4756 | 2,94 | 0,4984 | ||
| 0,48 | 0,1844 | 0,98 | 0,3365 | 1,48 | 0,4306 | 1,98 | 0,4761 | 2,96 | 0,4985 | ||
| 0,49 | 0,1879 | 0,99 | 0,3389 | 1,49 | 0,4319 | 1,99 | 0,4767 | 2,98 | 0,4986 |
Приложение 2
Значение t-критерия Стьюдента при уровне значимости 0,10, 0,05, 0,01
| Число степеней свободы d.f. | P | d.f. | P | ||||
| 0,10 | 0,05 | 0,01 | 0,10 | 0,05 | 0,01 | ||
| 6,3138 | 12,706 | 63,657 | 1,7341 | 2,1009 | 2,8784 | ||
| 2,9200 | 4,3027 | 9,9248 | 1,7291 | 2,0930 | 2,8609 | ||
| 2,3534 | 3,1825 | 5,8409 | 1,7247 | 2,0860 | 2,8453 | ||
| 2,1318 | 2,7764 | 4,6041 | 1,7207 | 2,0796 | 2,8314 | ||
| 2,0150 | 2,5706 | 4,0321 | 1,7171 | 2,0739 | 2,8188 | ||
| 1,9432 | 2,4469 | 3,7074 | 1,7139 | 2,0687 | 2,8073 | ||
| 1,8946 | 2,3646 | 3,4995 | 1,7109 | 2,0639 | 2,7969 | ||
| 1,8595 | 2,3060 | 3,3554 | 1,7081 | 2,0595 | 2,7874 | ||
| 1,8331 | 2,2622 | 3,2498 | 1,7056 | 2,0555 | 2,7787 | ||
| 1,8125 | 2,2281 | 3,1693 | 1,7033 | 2,0518 | 2,7707 | ||
| 1,7959 | 2,2010 | 3,1058 | 1,7011 | 2,0484 | 2,7633 | ||
| 1,7823 | 2,1788 | 3,0545 | 1,6991 | 2,0452 | 2,7564 | ||
| 1,7709 | 2,1604 | 3,0123 | 1,6973 | 2,0423 | 2,7500 | ||
| 1,7613 | 2,1448 | 2,9768 | 1,6839 | 2,0211 | 2,7045 | ||
| 1,7530 | 2,1315 | 2,9467 | 1,6707 | 2,0003 | 2,6603 | ||
| 1,7459 | 2,1199 | 2,9208 | 1,6577 | 1,9799 | 2,6174 | ||
| 1,7396 | 2,1098 | 2,8982 |  | 1,6449 | 1,9600 | 2,5758 |
Приложение 3
| f | p | ||||
| 0,80 | 0,90 | 0,95 | 0,98 | 0,99 | |
| 3,0770 | 6,3130 | 12,7060 | 31,8200 | 63,6560 | |
| 1,8850 | 2,9200 | 4,3020 | 6,9640 | 9,9240 | |
| 1,6377 | 2,3534 | 3,1820 | 4,5400 | 5,8400 | |
| 1,5332 | 2,1318 | 2,7760 | 3,7460 | 4,6040 | |
| 1,4759 | 2,0150 | 2,5700 | 3,6490 | 4,0321 | |
| 1,4390 | 1,9430 | 2,4460 | 3,1420 | 3,7070 | |
| 1,4149 | 1,8946 | 2,3646 | 2,9980 | 3,4995 | |
| 1,3968 | 1,8596 | 2,3060 | 2,8965 | 3,3554 | |
| 1,3830 | 1,8331 | 2,2622 | 2,8214 | 3,2498 | |
| 1,3720 | 1,8125 | 2,2281 | 2,7638 | 3,1693 | |
| 1,3630 | 1,7950 | 2,2010 | 2,7180 | 3,1050 | |
| 1,3562 | 1,7823 | 2,1788 | 2,6810 | 3,0845 | |
| 1,3502 | 1,7709 | 2,1604 | 2,6503 | 3,1123 | |
| 1,3450 | 1,7613 | 2,1448 | 2,6245 | 2,9760 | |
| 1,3406 | 1,7530 | 2,1314 | 2,6025 | 2,9467 | |
| 1,3360 | 1,7450 | 2,1190 | 2,5830 | 2,9200 | |
| 1,3334 | 1,7396 | 2,1098 | 2,5668 | 2,8982 | |
| 1,3304 | 1,7341 | 2,1009 | 2,5514 | 2,8784 | |
| 1,3277 | 1,7291 | 2,0930 | 2,5395 | 2,8609 | |
| 1,3253 | 1,7247 | 2,0860 | 2,5280 | 2,8453 | |
| 1,3230 | 1,7200 | 2,0790 | 2,5170 | 2,8310 | |
| 1,3212 | 1,7117 | 2,0739 | 2,5083 | 2,8188 | |
| 1,3195 | 1,7139 | 2,0687 | 2,4999 | 2,8073 | |
| 1,3178 | 1,7109 | 2,0639 | 2,4922 | 2,7969 | |
| 1,3163 | 1,7081 | 2,0595 | 2,4851 | 2,7874 | |
| 1,3150 | 1,7050 | 2,0590 | 2,4780 | 2,7780 | |
| 1,3137 | 1,7033 | 2,0518 | 2,4727 | 2,7707 | |
| 1,3125 | 1,7011 | 2,0484 | 2,4671 | 2,7633 | |
| 1,3114 | 1,6991 | 2,0452 | 2,4620 | 2,7564 | |
| 1,3104 | 1,6973 | 2,0423 | 2,4573 | 2,7500 |
Список использованной литературы
1. Елисеева И. И., Юзбашев М. М. Общая теория статистики: Учебник/ Под ред. И. И. Елисеевой. – 5-е изд., перераб. и доп. – М.: Финансы и статистика, 2006. – 656 с.
2. Ефимова М. Р., Петрова Е. В., Румянцев В. Н. Общая теория статистики: Учебник. – 2-е изд., испр. и доп. – М.: ИНФРА-М, 2007. – 416 С. – (Высшее образование).
3. Статистика: учеб. / И. И. Елисеева [и др.]; под ред. И. И. Елисеевой.- М.: ТК Вебли, Изд-во Проспект, 2006. – 448 с.
4. Теория статистики: Учебник / Под. ред. профессора Г. Л. Громыко – 2-е изд. перераб. и доп. – М.: ИНФРА – М, 2009 – 476 с.
5. https://www.gks.ru.
[1] Величина р определяется по данным предыдущих наблюдений или по данным предварительно проведенного пробного обследования. Следует также отметить, что во всех случаях соблюдается условие 0< p <1. Поэтому максимум произведения р(1-р) составит 0,25, что соответствует р = 0,5. Поэтому приведенную формулу можно применять и тогда, когда информация о генеральной доле полностью отсутствует: 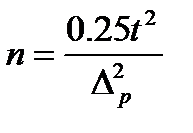 , причем величина требуемого для обеспечения заданной предельной ошибки объема выборки окажется завышенной.
, причем величина требуемого для обеспечения заданной предельной ошибки объема выборки окажется завышенной.

