2015-04-30
2015-04-30 692
692Основным содержанием функции общения является процедура понимания ЭВМ вводимых в нее текстов, К сожалению, ни в лингвистике, ни в психологии, ни в философии термин «понимание» не получил точной интерпретации.
Поэтому ниже дадим его интерпретацию, удобную для разработчиков интеллектуальных систем. Эта интерпретация является развитием той, которая была опубликована в [1], Введем семь уровней понимания, характерных для интеллектуальных интерфейсов, точно поясняя на каждом уровне его содержание.
|
|
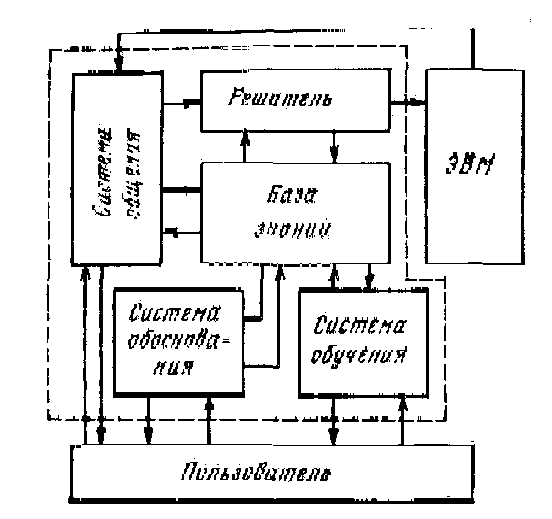
Рис.1. Структура интеллекту-
ального интерфейса
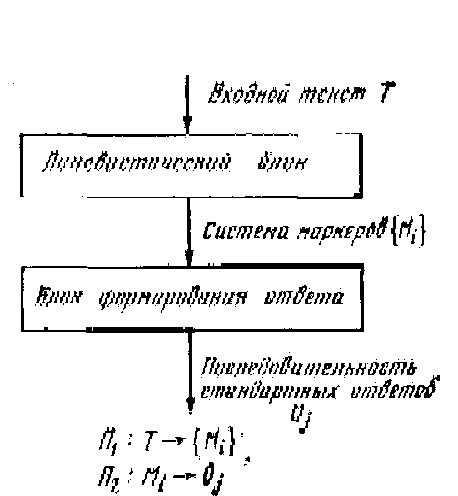
Рис.2. Интерфейс «нулевого» уровня
0. На нулевом уровне понимания система способна отвечать на сообщения пользователя безо всякого анализа их сути. На этом уровне понимание как таковое у системы отсутствует. В общении людей между собой нулевому уровню понимания соответствует так называемый фатическия диалог, когда разговор поддерживается без анализа сути высказываний собеседника за счет чисто внешних форм поддержки диалога. Например, разговаривая с кем-то по телефону, когда содержание самого разговора вас абсолютно не интересует, можно, не слушая того, что говорит собеседник, вставлять периодически ничего не значащие реплики типа: «Очень интересно», «я слушаю» и т. п. Можно «зацеплять?» свои реплики чисто формально за те или иные слова в сообщениях собеседника. Если собеседник сказал о чем-то, что это важно, то можно синтезировать реплику: «Это, действительно, очень важно», даже не давая себе труда понять, о чем идет речь. Интересно, что подобный способ общения внешне опознается далеко не сразу. Первые программы общения для ЭВМ (например, знаменитая программа ЭЛИЗА [2]) неоднократно приводили собеседника в изумление. Казалось, что эти программы ведут с партнерами настоящий интеллектуальный разговор. Тем не менее, организация системы общения с таким уровнем понимания весьма проста. Она показана на рис.2. На вход лингвистического блока поступает входной текст. В этом тексте выделяются заранее заданные маркеры, которыми могут быть конкретные слова или выражения, или стандартные компоненты, в синтаксической структуре предложения. На каждый такой маркер в памяти ЭВМ хранится конструкция ответного сообщения. Оно может быть стандартным или иметь «пустые» места, заполняемые стандартным образом выделенными в тексте маркерами. При вводе в ЭВМ фразы: «Мне нравится хорошая погода», ответная реплика может звучать: «А почему?» И эта же самая реплика будет ответной для введенной в ЭВМ фразы: «Мне не нравится, когда я болею», ибо маркером, вызывающим подобную реплику со стороны ЭВМ, может быть слово «нравится» С функциональной точки зрения нулевой уровень понимания характеризуется двумя процедурами: П 1– выделение маркеров по входном сообщении и П 2 – формирование стандартных ответных реплик.
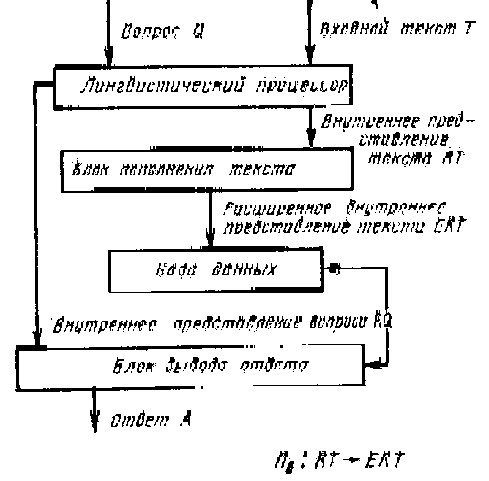
1. На первом уровне понимания система становится способной отвечать на все вопросы, ответы на которые есть во введенном в нее тексте Если система способна давать любые такие ответы, то она «овладела» первым уровнем понимания. Например, если в ЭВМ введен текст: «В аэропорту Внуково в 20 часов приземлился самолет ИЛ-62, прилетевший из Баку. В 21 час пассажиры этого рейса получили свой багаж, а в 22 часа этот же самолет улетел в Баку», то на первом уровне понимания ЭВМ обязана отвечать правильно на вопросы типа: «Откуда прилетел самолет, приземлившийся в 20 часов в аэропорту Внуково?» или «В каком аэропорту приземлился в 20 часов ИЛ-62, прилетевший из Баку?».
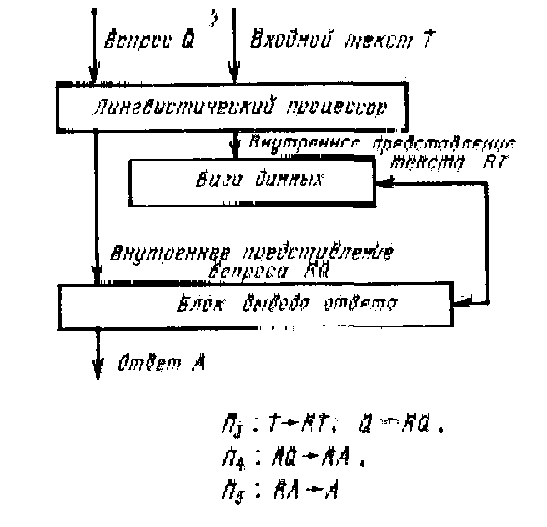
Для того чтобы в системе общения была реализована возможность подобной работы с текстом, необходима структура, показанная на рис.3. На этом рисунке приведены лингвистический процессор, блок вывода ответа и база данных. В базу данных вводится входной текст, преобразованный в лингвистическом процессоре в некоторое внутреннее представление. Это внутреннее представление может быть любым, но важно, чтобы в лингвистическом процессоре были реализованы процедуры, позволяющие выявить глубинную синтаксическую структуру вводимых в ЭВМ предложений, а также структуру межфразовых связей в тексте [3, 4]. На современном уровне наших знаний об анализе предложений н текста эти процедуры достаточно хорошо известны и реализованы в ряде практически действующих систем [б]. Знание глубинной синтаксической структуры позволяет блоку вывода ответа соотнести внутреннее представление вопроса RQ с внутренним представлением текста RТ и найти то предложение, в котором содержится ответ на введенный вопрос, либо убедиться, что такого предложения нет. Во втором случае пользователь получает отказ, а в первом случае за счет трансформации найденного предложения (или без нее) формируется ответ, нужный пользователю. Три процедуры, характерные для первого уровня понимания текста, – это процедура П3, реализуемая в лингвистическом процессоре и осуществляющая перевод текста и вопросов во внутренние представления, передаваемый в базу данных и блок формирования ответа; процедура П4, характеризующая поиск того фрагмента текста, который соответствует вопросу, и процедура П5, которая переводит внутреннее представление ответа во внешнее представление. Две последние процедуры характеризуют работу блока вывода ответа.
|
|
Рис.3. Интерфейс «первого» уровня Рис. 4. Интерфейс «второго» уровня
2. На втором уровне понимания используется структура, показанная не рис.4. Новым в этой структуре является блок пополнения текста. В его функции входит автоматическое пополнение текста за счет хранящихся в памяти ЭВМ процедур пополнения. Примерами подобных процедур могут служить правила вывода псевдофизических логик [б], к которым относятся логики времени, пространства, причинно-следственных связей и т.п. Если в память ЭВМ введен тот же текст, который мы использовали для иллюстрации функционирования системы с первым уровнем понимания, то на втором уровне система может отвечать на вопросы типа; «Получили ли пассажиры багаж, когда в 22 часа самолет ИЛ-62, прилетевший из Баку, улетел обратно?». Для формирования ответа на такой вопрос необходимо, используя правила логики времени, спроецировать события, упомянутые в исходном тексте, на порядковую (в данном случае, метрическую) школу времени и тем самым упорядочить их, а используя правила логики пространства, отождествить «обратно» с «Баку»,
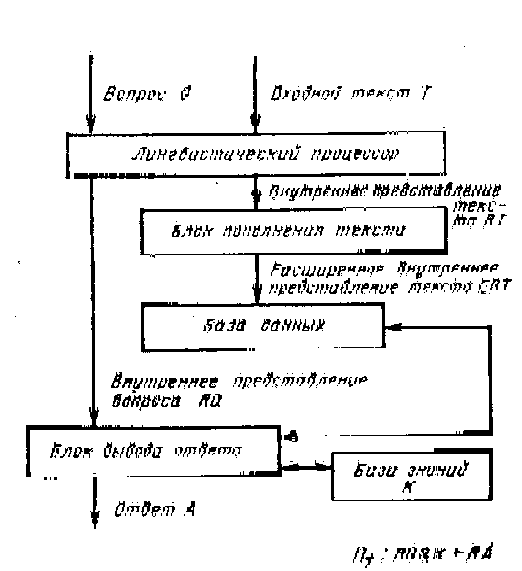
3. Третий уровень понимания реализуется структурой системы, похожей на структуру, показанную на рис. 4. Отличие состоит в процедурах, реализуемых блоком вывода ответа. Формируя ответы, этот блок использует теперь не только информацию, хранящуюся в базе данных, куда введено расширенное внутреннее представление исходного текста, но и некоторую дополнительную информацию, хранящуюся в базе знаний (рис.5). Эта априорно хранимая в памяти системы дополнительная информация есть знание системы о типовых сценариях ситуаций и процессов, характерных для той предметной области, с которой работает система.
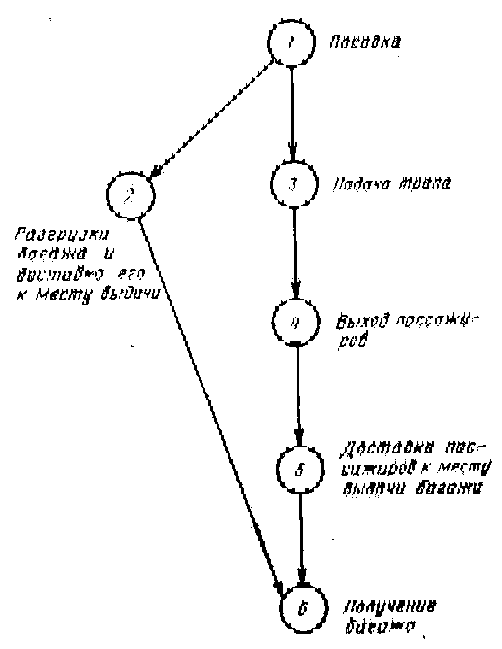
Используя все тот же иллюстративный пример, введем в базу знаний типовой сценарий процесса прилета пассажирского самолета и процесса его отлета. Сценарий прилета такого самолета может выглядеть, например, так, как это показано на рис.6. Вершины сценарий соответствуют определенным событиям, а дуги характеризуют последовательность событий во времени, задавая на них частичный порядок. Наличие сценария позволяет пользователю получить, например, ответ на вопрос: «Когда пассажиры покинули самолет?». Об этом факте в исходном тексте нет никакой информации. И система, уровень понимания которой ниже третьего, оказывается не в состоянии понять подобный вопрос. В системе с третьим уровнем понимания блок вывода ответа по внутреннему представлению вопроса RQ производит поиск нужного для формирования ответа фрагмента текста. При ненахождении такого фрагмента блок вывода ответа обращается к содержимому базы знаний. Если там ответ также не найден, то пользователю выдается отказ, а если нужная информация имеется, то с помощью процедур, хранимых в блоке вывода ответа, эта информация извлекается из сценария и участвует в формировании ответа.
В нашем примере обнаруживается, что событие «Выход пассажиров» (в описании этого событии, хранящемся также в базе знаний, имеется информация о перефразах, характерных для данного события, так что «покинули самолет» будет отождествлено с «выходом пассажиров из самолета») расположено по времени между событиями «Посадка» и «Получение багажа». Используя правила псевдофизической логики, система расширила исходный текст. Поэтому здесь возможно формирований ответа: «Пассажиры покинули самолет между 20 и 21 часами».
На третьем уровне понимания сохраняются процедуры П3, П5 и П6. Процедура П4, которая ранее реализовалась в блоке вывода ответа, усложняется и заменяется на процедуру П7, учитывающую необходимость работы с базой знаний.
|
|
Рис.5. Интерфейс «третьего» уровня Рис. 6. Пример сценария
Сценарии могут иметь самую разную форму. Дуги, входящие в них, могут интерпретироваться не только как маркеры временных упорядочений, но и как причинно-следственные связи. Конечно, могут браться и связи, характеризующие такие отношения, как «род–вид», «часть–целое», аргумент–функция» и т.п. [6]. В искусственном интеллекте сценариям отводится центральная роль в процессах понимания текстов на естественном языке[7, 8],
4. Для четвертого уровня понимания общая структура системы остается такой же, как и на рис.5. Меняется только процедура, реализуемая блоком вывода ответа. Эта процедура обогащается за счет введения в нее эффективных средств дедуктивного вывода. В базе знаний, кроме сценариев хранится и иная информация, отражающая свойства отдельных объектов, фактов и явлений, характерных для предметной области, с которой работает система, а также совокупность различных закономерностей, характерных для процессов, протекающих в ней. Вся эта информация априорно закладывается в виде некоторых внутренних формализованных представлений в базу знаний. Специалисты, которые этим занимаются, в последнее время все чаще называются инженерами знаний или инженерами по знаниям.
Сейчас используется несколько форм представления знаний в базах знаний [9]. Наиболее популярны продукционные системы и фреймы. Продукционные системы особенно удобны для дедуктивного вывода, так как каждая продукция по сути представляет собой некоторое правило вывода вместе с условиями его применения, Общий вид продукции:
S; Р; Ecли Н, то L, W.
Здесь «Ecли Н, то L» определяет собственно продукцию, или, как часто говорят, ядро продукции. Ее интерпретация может быть различной. В логических системах вывода эта интерпретация такова: «Если Н является выведенным, то выводимо L»- Элемент продукции Р описывает условия применимости ядра. Это, как правило, совокупность некоторых предикатов, которые должны быть истинными для возможности применения правила, описываемого ядром продукции. Проблемная область естественным образом разбивается на отдельные сферы, внутри каждой из которых существуют свои продукции. Например, проблемная область, относящаяся к функционированию аэропорта, в качестве такой сферы может содержать сведения об обслуживании пассажиров, об обслуживании самолетов, об аэродромной службе и т.п. Поэтому при поиске в базе знаний нужных продукций, чтобы не затрачивать на этот поиск лишнего времени, желательно воспользоваться естественной структуризацией проблемной области. Элемент S представляет собой имя некоторой определенной сферы проблемной области. Наконец, W описывает последействие применения продукций, те изменения, которые необходимо внести в базу знаний после реализации продукции.
Организовывать дедуктивный вывод на продукциях достаточно естественно и просто. Шаги вывода могут идти от исходных данных к целям, выраженным в правых частях ядер некоторых продукций, или от целей к наличным исходным данным. Эти два метода соответствуют методам прямой и обратной волны [10] (второй метод реализуется, например, средствами языка Пролог). Именно поэтому продукционные представления столь широко распространены в экспертных системах [11, 12].
Фреймовые представления – это записи вида:
(Имя фрейма <Имя слота 1; Значение слота 1> <Имя слота 2; Значение слота 2>:...; <Имя слота N; Значение слота N». В качестве значений слота могут выступать имена других фреймов, что обеспечивает рекурсивное вложение фреймов; имена других фреймов с указанием имени связывающего их отношения, что обеспечивает организацию семантической сети из фреймов; константные (терминальные) значения; имена присоединенных процедур, специальные метки и сообщения и т. п.
Таким образом, фреймовые представления намного богаче продукционных. Но за это богатство приходится платить менее эффективными процедурами вывода, хотя в последнее время эта неэффективность начинает преодолеваться [9, 13]. Все большее число интеллектуальных систем использует фреймовые представления [14].
Между этими двумя основными формами представления знаний существует немало переходных смешанных форм, которые многим исследователям кажутся наиболее удобными[11, 14, 15].
Если вернуться к нашему иллюстративному примеру, то четвертый уровень понимания может, например, обеспечить ответ на вопрос: «Когда доставляют пассажиров к месту выдачи багажа?». Ответ на него требует не только обращения к сценарию, показанному на рис. 6, как на третьем уровне понимания, но и вывода по этому сценарию (в данном случае методом обратной волны). В результате этого вывода возникает ответ: «Пассажиров доставляют к месту выдачи багажа после посадки самолета, подачи к нему трапа и выхода пассажиров».
На четвертом уровне понимания процедура П7 усложняется, так как в ней появляются средства дедуктивного вывода. Эта новая процедура может быть обозначена как П8.
5. На пятом уровне понимания процедура П8 еще более расширяется. К дедуктивному выводу добавляются средства правдоподобного вывода. Среди них вывод по нечетким схемам, вероятностный вывод, вывод по аналогии и вывод по ассоциации. Эти «экзотические» схемы вывода в последнее время активно изучаются в работах по ИИ [16-19]. Сейчас уже можно говорить о том, что подобные методы, моделирующие особенности человеческих рассуждений и, прежде всего, рассуждений специалистов в данной проблемной области [20], начинают внедряться в практику построения интеллектуальных систем.
Для иллюстрации правдоподобного вывода используем все тот же иллюстративный пример. Пусть текст его введен в базу данных, а в базе знаний хранится сценарий, показанный на рис.6, Однако пользователь интересуется проблемой, близкой к той, которая обсуждается во введенном тексте, а не самим этим текстом. Он задает вопрос: «Улетел ли самолет, прибывший из Еревана в 12 часов?». Система, не находя информации в сноси памяти по этому поводу, вольна ответить пользователю отказом. Но на пятом уровне понимания она может обратиться к механизмам правдоподобных рассуждений. Если считать, что общие закономерности прилета и отлета самолетов существуют, то она может воспользоваться текстом в базе данных для рассуждений по аналогии. Общая схема таких рассуждений приведена на рис.7. На этой схеме G 1 и G2 означают некоторые гомоморфизмы. Предполагая, что гомоморфизм G3 есть G 1, можно «вычислить» вид утверждения F 4. Для нашего иллюстративного примера F 4(технику вывода мы опускаем) будет звучать примерно так: «Самолет, прибывший из Еревана в 12 часов, улетел обратно приблизительно в 14 часов»,
Процедура, реализуемая на пятом уровне понимания в блоке вывода ответа, содержит в качестве своей составляющей П8 и новую составляющую П9 – совокупность разнообразных процедур правдоподобного вывода.
6. На шестом уровне понимания схема несколько видоизменяется. Она показана на рис. 8. В нее добавляется блок пополнения базы знаний. До сих пор считалось, что заполнение базы знаний происходит до начала работы системы. В течение ее функционирования содержимое базы знаний самой системой изменено быть не может. Всякое изменение этого содержимого связано с деятельностью инженера знаний.
На шестом уровне понимания это условие снимается. Здесь база знаний становится открытой. Система становится способной пополнять ее, извлекая новые закономерности и знания из наблюдений за содержимым базы данных и обработки этих наблюдений. Другими словами, система становится способной к индуктивному выводу, Сейчас разработаны мощные практические процедуры индуктивного вывода [21-23], которые с успехом могут быть использованы при пополнении базы знаний новыми закономерностями. Так, наблюдая во вводимых о базу данных текстах разницу между временем посадки самолета и временем получения багажа, система индуктивного вывода сможет установить закономерность, согласно которой эта разница в большинстве случаев (понятие «большинство» в системе индуктивного вывода формализуется) составляет около 1 часа. В результате система становится способной ответить на вопрос, ответ на который ранее в базе данных и базе знаний отсутствовал: «Какое время проходит между посадкой самолета и получением багажа?» На подобный вопрос система может дать ответ типа «В большинстве случаев между этими событиями проходит один час». Процедура индуктивного пополнения базы знаний на рис. 8 обозначена как П10.