 2015-04-30
2015-04-30 1104
1104Основные элементарные операции при работе с данными – поиск, чтение, корректировка, добавление, удаление логической записи. Поскольку логические и физические записи каждого файла БД имеют одинаковую длину, то чтение, корректировка, удаление и добавление в конец записи требуют минимального количества обращений к ВП. Основная сложность возникает при поиске нужной записи и при добавлении новой записи на заданное место. Поэтому охарактеризуем основные структуры хранения, заострив внимание именно на этих операциях.
Последовательное размещение физических записей
В этой структуре хранения записи в памяти размещаются последовательно друг за другом.
Поиск возможен только полным перебором.
При добавлении логической записи в произвольное место таблицы приходится переписывать в памяти (сдвигать на одну позицию) физические записи, соответствующие логическим записям таблицы, расположенным ниже места вставки добавляемой строки.
Размещение физических записей в виде списковой структуры
Физические записи представлены в виде связного списка. Кроме этого, в ВП формируется список свободных элементов ("пустых" физических записей), которые используются при вводе новой записи


Поиск возможен только полным перебором.
При добавлении записи в произвольное место, если в соответствующей физической записи есть запись, помеченная как удаленная, то новая записывается на ее место. В противном случае в цепочку физических записей вставляется новая запись, и происходит замена адресов.
Использование индексов (индексирование)
Упорядочение записей позволяет использовать бинарный метод поиска нужной записи и тем самым существенно сократить одну из основных составляющих времени поиска – число обращений к ВП. Однако при этом возникают проблемы с добавлением записей, связанные с необходимостью перезаписи части физических записей (сдвига).
Для того чтобы использовать бинарный поиск и не перемещать физические записи при добавлении новых записей, используется так называемое логическое упорядочение физических записей (индексирование). Основная структура хранения содержит записи исходной таблицы и представлена в виде неупорядоченной последовательности физических записей. Для возможной реализации бинарного поиска по определенному ключу создается дополнительная структура хранения - так называемый индекс. Число записей в индексе равно числу записей исходной таблицы (числу физических записей в основной структуре хранения). Каждая запись индекса имеет два поля: ключевое поле записи основной структуры и указатель – адрес записи основной структуры с соответствующим значением ключа.
Записи индекса (индексного файла) упорядочены по значению ключа. Адреса связи этих записей определяют логическое упорядочение записей основной структуры хранения.
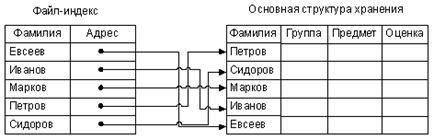
Рис.14. Индексирование
Поиск нужной записи по заданному значению ключа осуществляется в индексном файле методом половинного деления. Суммарный объем записей индекса невелик, поэтому индекс, как правило, целиком считывается для обработки в ОП за одно обращение к ВП. После того как в индексном файле обнаружена искомая запись, по адресу связи читается полная соответствующая запись основной структуры хранения. Если необходим поиск по другому ключу, строится еще один индекс по соответствующему ключу. Таким образом, по любому ключу поиск можно осуществлять бинарным методом.
Добавляемая запись заносится в конец основного файла. Формируется новая запись индекса, соответствующая добавляемой записи. Записи индекса переупорядочиваются по значениям ключа, и индекс заносится в ВП. Число обращений к ВП в этом случае, в основном, определяется чтением-записью индекса.
Таким образом, использование индексов позволяет ценой некоторого увеличения объема используемой памяти (за счет индекса) существенно сократить время реализации основных операций. В связи с этим индексирование используется во многих современных СУБД.

