2015-05-18
2015-05-18 701
701Уравнение однофакторной (парной) линейной регрессии имеет вид:
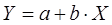
Для нашего примера:
Y – Валовый доход растениеводства, приходящийся на 100 га пашни, тыс. руб. (результативный признак);
Х – Доля трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, % (факторный признак).
Для нахождения параметров a и b линейной регрессии можно решить систему нормальных уравнений относительно a и b.
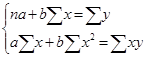

Для расчета параметров уравнения регрессии можно также воспользоваться готовыми формулами, полученными путем преобразования уравнений системы:
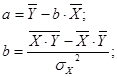
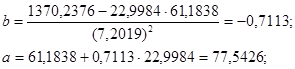
Уравнение принимает вид: 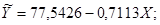
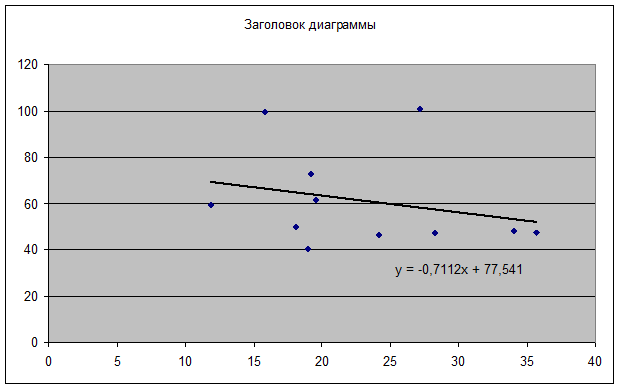
Рис. 2. Влияние доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на валовый доход растениеводства, приходящийся на 100 га пашни.
Коэффициент -0,7113 стоящий перед Х, называется коэффициентом регрессии. По знаку этого коэффициента судят о направлении связи. Если знак «+» – связь прямая; «-» – связь обратная. Величина коэффициента регрессии показывает, на сколько в среднем изменится величина результативного признака Y при изменении факторного признака Х на единицу. В данном случае с увеличением доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на 1 % валовый доход растениеводства, приходящийся на 100 га пашни, уменьшается в среднем на 0,7113 тыс. руб.
Коэффициент регрессии применяется для расчета среднего коэффициента эластичности, который показывает: на сколько процентов в среднем по совокупности изменится результат Y от своей средней величины при изменении фактора X на 1% от своего среднего значения.
Коэффициент эластичности рассчитывается по формуле:
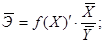
В нашем случае 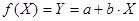
И формула коэффициента эластичности парной линейной регрессии принимает вид:
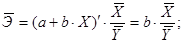
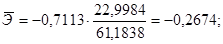
С увеличением доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на 1 % валовый доход растениеводства, приходящийся на 100 га пашни, уменьшается в среднем на 0,26749%.
При линейной корреляции между Х и Y исчисляют парный линейный коэффициент корреляции r. Он принимает значения в интервале –1 £ r £ 1. Знак коэффициента корреляции показывает направление связи: «+» – связь прямая, «–» – связь обратная. Абсолютная величина характеризует степень тесноты связи.
Коэффициент парной линейной корреляции рассчитаем по формуле:
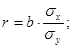
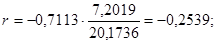
Линейный коэффициент парной корреляции показывает, что связь между долей трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, и валовым доходом растениеводства, приходящийся на 100 га пашни, обратная и слабая.
Изменение результативного признака Y обусловлено вариацией факторного признака X. Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака характеризует коэффициент детерминации D.
Коэффициент детерминации рассчитывается по формуле:
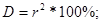
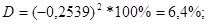
Следовательно, вариация валового дохода растениеводства, приходящийся на 100 га пашни, на 6,4% объясняется вариацией доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, а остальные 93,6% вариации валового дохода растениеводства, приходящийся на 100 га пашни, обусловлены изменением других, не учтенных в модели факторов.
Для практического использования корреляционно-регрессионных моделей большое значение имеет их адекватность, т.е. соответствие фактическим статистическим данным. Корреляционно-регрессионный анализ проводится обычно по ограниченному объему статистической совокупности. Поэтому показатели регрессии и корреляции – параметры уравнения регрессии, коэффициенты корреляции и детерминации могут быть искажены действием случайных факторов. Чтобы проверить насколько эти показатели характерны для генеральной совокупности, являются ли они результатом действия случайных величин, необходимо проверить адекватность построенных статистических моделей.
Оценим модель через среднюю ошибку аппроксимации.
Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:
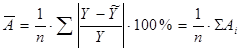
Допустимый предел значений 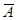 - не более 8 – 10%.
- не более 8 – 10%.
Выполним вспомогательные расчеты (табл.6).
Таблица 6. Исходные данные, необходимые для определения показателей аппроксимации.
| № хозяйства | Доля трактористов-машинистов в общей численности работников, занятых в сельскохозяйственном производстве, % | Валовый доход растениеводства, приходящийся на 100 га пашни, тыс.руб. | Расчетные величины | ||||
| 
| 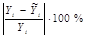
| 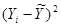
| 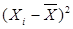
| |||
| 34,0426 | 48,2162 | 53,3288883 | -5,11268832 | 10,6036733 | 26,1395818 | 121,975157 | |
| 24,1935 | 46,3568 | 60,3337919 | -13,9769919 | 30,1508989 | 195,356302 | 1,42835093 | |
| 28,2486 | 47,4703 | 57,4497127 | -9,97941268 | 21,0224344 | 99,5886775 | 27,5649819 | |
| 18,9850 | 40,5136 | 64,0381953 | -23,5245953 | 58,0659219 | 553,406586 | 16,1070877 | |
| 27,1845 | 100,7356 | 58,2065248 | 42,52907524 | 42,2185158 | 1808,72224 | 17,5237377 | |
| 11,9266 | 59,4603 | 69,0582897 | -9,59798971 | 16,1418454 | 92,1214064 | 122,58395 | |
| 19,5652 | 61,4004 | 63,6255439 | -2,22514394 | 3,62398931 | 4,95126553 | 11,7866126 | |
| 18,1208 | 49,7596 | 63,9008582 | 8,871941755 | 12,1912882 | 78,7113505 | 14,5944143 | |
| 15,8228 | 99,1870 | 64,652834 | -14,893234 | 29,9303733 | 221,808419 | 23,790627 | |
| 19,1781 | 72,7728 | 66,2872238 | 32,89977621 | 33,1694438 | 1082,39527 | 51,4887135 | |
| 35,7143 | 47,1492 | 52,1399373 | -4,99073732 | 10,5849883 | 24,907459 | 161,695038 | |
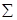
| 252,9819 | 673,0219 | 673,0218 | 267,703373 | 4188,10856 | 570,53867 | |
| сред. знач. | 22,9984 | 61,1838 | 61,1838 | 24,3366702 |
Средняя ошибка аппроксимации равна 24,3367%. т.е. в среднем расчетные значения валового дохода растениеводства, приходящийся на 100 га пашни, отличаются от фактических на 24,3367%, что не входит в допустимый предел.
Оценим модель через F-критерий Фишера. F-критерий Фишера необходим для проверки нулевой гипотезы о статистической незначимости уравнения регрессии и показателя тесноты связи (r).
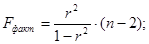
Выдвинем H0 о статистической незначимости полученного уравнения регрессии и показателя тесноты связи.
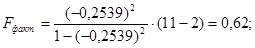
Сравним фактическое значение F-критерия с табличным. Для этого выпишем из таблицы «Значения F-Фишера при уровне значимости α=0,05» табличное значение.
k1 – число факторных признаков в модели
k2 = n- k1-1
n – число единиц совокупности
В нашем примере k1 =1, k2 = 11-1-1 = 9
Таким образом
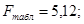
Так как Fфакт<Fтабл,то при заданном уровне вероятности α=0,05 следует принять нулевую гипотезу о статистической незначимости уравнения регрессии и показателя тесноты связи.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерий Стьюдента и доверительные интервалы для каждого из показателей.
Вероятностная оценка параметров корреляции производится по общим правилам проверки статистических гипотез, разработанным математической статистикой, в частности путем сравнения оцениваемой величины со средней случайной ошибкой оценки:
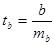 ;
; 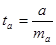 ;
; 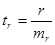
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
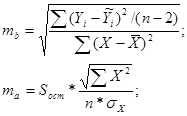
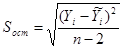 ;
;
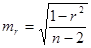
Выдвинем нулевую гипотезу о незначимости коэффициентов корреляции и регрессии.
Рассчитаем случайные ошибки параметров линейной регрессии и коэффициента корреляции:
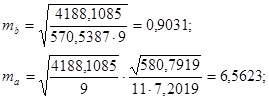
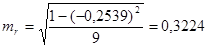
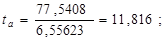
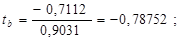
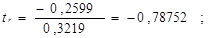
tтабл при уровне значимости α=0,05 и числе степеней свободы, равном n-2 = 11-2=9, равно 2,2622.
Так как | tb|<tтабл и | tr|<tтабл, следовательно, Н0 о незначимости коэффициентов корреляции и регрессии подтверждается.
Взаимосвязь между t-статистикой и F-статистикой:
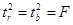
0.62=0.62=0.62
Рассчитаем доверительные интервалы для каждого показателя. Для этого определим предельную ошибку D для каждого из показателей.
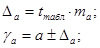
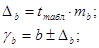
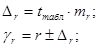
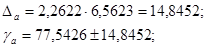
С вероятностью 95% можно утверждать, что показатель a находится в пределах:
62,6974<a<92,3878
Так как в пределы доверительного интервала не входит 0, то с вероятностью 95% можно судить о статистической значимости параметра a.
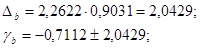
С вероятностью 95% можно утверждать, что коэффициент регрессии находится в пределах:
-2.7541<b<1,3317
Так как в пределы доверительного интервала входит 0, то с вероятностью 95% можно судить о незначимости коэффициента регрессии.
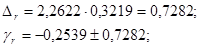
С вероятностью 95% можно утверждать, что коэффициент корреляции находится в пределах:
-0,9821<r<0,4743
Так как в пределы доверительного интервала входит 0, то с вероятностью 95% можно судить о статистической незначимости коэффициента корреляции.