 2015-05-18
2015-05-18 6050
6050Найдем доверительный интервал для оценки вероятности по относительной частоте, используя формулу:
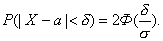
Если n достаточно велико и р не очень близка к нулю и единице, то можно считать, что относительная частота распределена приближенно по нормальному закону, причем М(W)= р. Заменив Х на относительную частоту, математическое ожидание - на вероятность, получим равенство:

Приступим к построению доверительного интервала (р1, р2), который с надежностью g покрывает оцениваемый параметр р Потребуем, чтобы с надежностью g выполнялось соотношение указанное выше равенство:
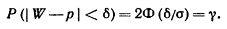
Заменив
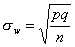 ,
,
получим:
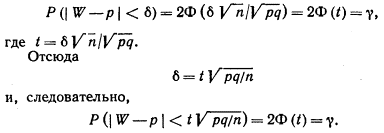
Таким образом, с надежностью g выполняется неравенство (чтобы получить рабочую формулу, случайную величину W заменим неслучайной наблюдаемой относительной частотой w и подставим 1- р вместо q):
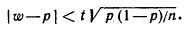
Учитывая, что вероятность р неизвестна, решим это неравенство относительно р. Допустим, что w > р. Тогда
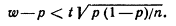
Обе части неравенства положительны; возведяих в квадрат, получим равносильное квадратное неравенство относительно р:
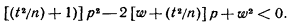
Дискриминант трехчлена положительный, поэтому корни действительные и различные:
меньший корень
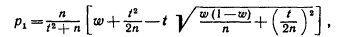
больший корень:
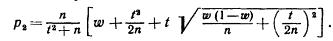
Замечание1: При больших значениях n, пренебрегая слагаемыми
 ,и
,и
учитывая
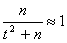
получим приближенные формулы для границ доверительного интервала:
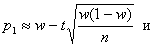
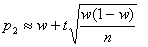
Пример1. Производят независимые испытания с одинаковой и неизвестной вероятностью появления события А в каждом испытании. Найти доверительный интервал для оценки вероятности с надежностью 0,95, если в 80 испытаниях событие А появилось 16 раз.
По условию n =80, m=16, g =0,95. Относительная частота
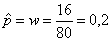 .
.
Из соотношения Ф(t)=0,95/2 = 0,475 по таблице находим t = 1,96. Т.к. n<100, то используем точные формулы, получим: р1= 0,128, р2= 0,299.
Замечание 2: Если n мало, то используем для определения концов доверительного интервала вероятности события при биноминальном распределении "Таблицу доверительных границ р1 и р2". Значения р1 и р2 находят в зависимости от n и m.
Пример. В пяти независимых испытаниях событие А произошло 3 раза. Найти с надежностью 0,95 интервальную оценку для вероятности события А в единичном испытании.
По условию задачи n=5, m=3. Имеет место схема повторных испытаний. Используя таблицу, находим доверительный интервал: 0,147<p<0,947.
11. Под статистической гипотезой понимают всякое высказывание о генеральной совокупности (случайной величине), проверяемое по выборке (по результатам наблюдений).
Не располагая сведениями о всей генеральной совокупности, высказанную гипотезу сопоставляют по определенным правилам, с выборочными сведениями и делают вывод о том, можно принять гипотезу или нет.
Нулевой (основной) называют выдвинутую гипотезу Н0.
Конкурирующей {альтернативной) называют гипотезу Hi, которая противоречит нулевой.
 Процедура сопоставления высказанной гипотезы с выборочными данными называется проверкой гипотезы.
Процедура сопоставления высказанной гипотезы с выборочными данными называется проверкой гипотезы.
Рассмотрим этапы проверки гипотезы и используемые при этом понятия.
Этап 1. Располагая выборочными данными и руководствуясь конкретными условиями рассматриваемой задачи, формулируют гипотезу Но, которую называют основной или нулевой, и гипотезу Н1 конкурирующую с гипотезой Н0. Термин «конкурирующая» означает, что являются противоположными следующие два события:
по выборке будет принято решение о справедливости для генеральной совокупности гипотезы Н0;
по выборке будет принято решение о справедливости для генеральной совокупности гипотезы Н1.
Гипотезу H1 называют также альтернативной. Например, если нулевая гипотеза такова: математическое ожидание равно 5,- то альтернативная гипотеза может быть следующей: математическое ожидание меньше 5, что записывается следующим образом:
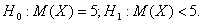
Этап 2. Задаются вероятностью a, которую называют уровнем значимости. Поясним ее смысл.
Решение о том, можно ли считать высказывание Н0 справедливым для генеральной совокупности, принимается по выборочным данным, т. е. по ограниченному ряду наблюдений, следовательно, это решение может быть ошибочным. При этом может иметь место ошибка двух родов:
отвергают гипотезу Н о, или, иначе, принимают альтернативную гипотезу H1, тогда как на самом деле гипотеза Н0 верна; это ошибка первого рода;
принимают гипотезу Н0 , тогда как на самом деле высказывание Н о неверно, т. е. верной является гипотеза Н1 это ошибка второго рода.
Так вот уровень значимости a—это вероятность ошибки первого рода, т. е.
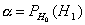
вероятность того, что будет принята гипотеза Н1 , если на самом деле в генеральной совокупности верна гипотеза Н о. Вероятность a задается заранее малым числом, используют некоторые стандартные значения: 0,05; 0,01; 0,005; 0,001. Например, a=0,05 означает следующее: если гипотезу Н о проверять по каждой из 100 выборок одинакового объема, то в среднем в 5 случаях из 100 мы совершим ошибку первого рода.
Вероятность ошибки второго рода обозначают b, т. е.
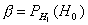
—вероятность того, что будет принята гипотеза Н о, если на самом деле верна гипотеза Н1.
Этап 3. Находят величину j такую, что:
ее значения зависят от выборочных данных, т. е. для которой справедливо равенство
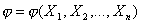
- ее значения позволяют судить о «расхождении выборки с гипотезой Н0»;
- и которая, будучи величиной случайной в силу случайности выборки, подчиняется при выполнении гипотезы Н о некоторому известному закону распределения.
Величину j называют критерием.
Этап 4. Далее рассуждают так. Так как значения критерия позволяют судить о «расхождении выборки с гипотезой Но», то из области допустимых значений критерия j следует выделить подобласть w таких значений, которые свидетельствовали бы о существенном расхождении выборки с гипотезой Но и, следовательно, о невозможности принять гипотезу Но.
Подобласть w называют критической областью.
Допустим, что критическая область выделена. Тогда руководствуются следующим правилом: если вычисленное по выборке значение критерия j попадает в критическую область, то гипотеза Но отвергается и принимается гипотеза Н1. При этом следует понимать, что такое решение может оказаться ошибочным:
на самом деле гипотеза Но может быть справедливой. Таким образом, ориентируясь на критическую область, можно совершить ошибку первого рода, вероятность которой задана заранее и равна a. Отсюда вытекает следующее требование к критической области w:
вероятность того, что критерий j примет значениеизкритической области w, должна быть равна заданному числу a, т. е.
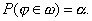
Но критическая область данным равенством определяется неоднозначно. Действительно, представив себе график функции плотности fj (х) критерия j, нетрудно понять, что наоси абсцисс существует бесчисленное множество областей-интервалов таких, что площади построенных на них криволинейных трапеций равны a. Поэтому кроме требования
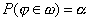
выдвигается следующее требование: критическая область w должна быть расположена так, чтобы при заданной вероятности a ошибки первого рода вероятность b ошибки второго рода была минимальной.
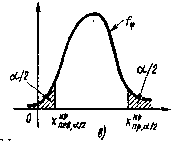
Возможны три вида расположения критической области (в зависимости от вида нулевой и альтернативной гипотез, вида и распределения критерия j):
правосторонняя критическая область (рис.а), где критическая точка
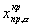
определяется из условия:
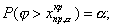
левосторонняя критическая область(рис.б), где критическая точка
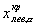
определяется из условия:
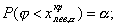
двусторонняя критическая область (рис.в), где критические точки
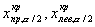 ,
,
называемые двусторонними, определяются из условий
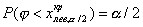
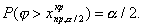
И называются двусторонними критическими точками.
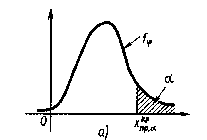
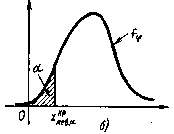
Этап 5. В формулу критерия
вместо Х1, Хг, …, Хп подставляют конкретные числа, полученные в результате п наблюдений, и подсчитывают числовое значение jчис критерия.
Если jчис попадает в критическую область w, то гипотеза Но отвергается и принимается гипотеза Н1.
Если jчис не попадает в критическую область, гипотеза Но не отвергается.
12. При проверке гипотезы может быть принято неправильное решение, т.е. могут быть допущены ошибки двух родов.
Ошибка первого рода состоит в том, что отвергается нулевая гипотеза 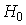 , когда на самом деле она верна.
, когда на самом деле она верна.
Ошибка второго рода состоит в том, что отвергается альтернативная гипотеза 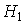 , когда она на самом деле верна.
, когда она на самом деле верна.
Вероятность ошибки 1-го рода (обозначается через  ) называется уровнем значимости критерия.
) называется уровнем значимости критерия.
Очевидно, 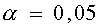 . Чем меньше , тем меньше вероятность отклонить верную гипотезу. Допустимую ошибку 1-го рода обычно задают заранее.
. Чем меньше , тем меньше вероятность отклонить верную гипотезу. Допустимую ошибку 1-го рода обычно задают заранее.
В одних случаях считается возможным пренебречь событиями, вероятность которых меньше 0,05 (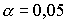 означает, что в среднем в 5 случаях из 100 испытаний верная гипотеза будет отвергнута), в других случаях, когда речь идет, например, о разрушении сооружений, гибели судна и т.п., нельзя пренебречь обстоятельствами, которые могут появиться с вероятностью, равной 0,001.
означает, что в среднем в 5 случаях из 100 испытаний верная гипотеза будет отвергнута), в других случаях, когда речь идет, например, о разрушении сооружений, гибели судна и т.п., нельзя пренебречь обстоятельствами, которые могут появиться с вероятностью, равной 0,001.
Обычно для используются стандартные значения: ; 0,01; 0,005; 0,001.
Вероятность ошибки 2-го рода обозначается через 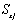 , т.е.
, т.е.  .
.
Величину 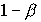 , т.е. вероятность недопущения ошибки 2-го рода (отвергнуть неверную гипотезу , принять верную ), называется мощностью критерия.
, т.е. вероятность недопущения ошибки 2-го рода (отвергнуть неверную гипотезу , принять верную ), называется мощностью критерия.
Очевидно,  .
.
Чем больше мощность критерия, тем вероятность ошибки 2-го рода меньше, что, конечно, желательно (как и уменьшение ).
Последствия ошибок 1-го, 2-го рода могут быть совершенно различными: в одних случаях надо минимизировать , в другом – . Так, применительно к судебной системе, ошибка 1-го рода приводит к оправданию виновного, ошибка 2-го рода – осуждению невиновного.
Отметим, что одновременное уменьшение ошибок 1-го и 2-го рода возможно лишь при увеличении объема выборок. Поэтому обычно при заданном уровне значимости отыскивается критерий с наибольшей мощностью.
Методика проверки гипотез сводится к следующему:
- Располагая выборкой
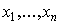 , формируют нулевую гипотезу и альтернативную .
, формируют нулевую гипотезу и альтернативную . - В каждом конкретном случае подбирают статистику критерия
 .
. - По статистике критерия
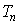 и уровню значимости определяют критическую область S (и
и уровню значимости определяют критическую область S (и 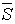 ). Для ее отыскания достаточно найти критическую точку
). Для ее отыскания достаточно найти критическую точку 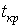 , т.е. границу (или квантиль), отделяющую область S от .
, т.е. границу (или квантиль), отделяющую область S от . - Границы областей определяются, соответственно, из соотношений:
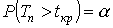 , для правосторонней критической области S (рис. 7);
, для правосторонней критической области S (рис. 7); 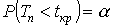 , для левосторонней критической области S (рис. 8);
, для левосторонней критической области S (рис. 8); 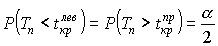 , для двусторонней критической области S (рис. 9).
, для двусторонней критической области S (рис. 9). - Для каждого критерия имеются соответствующие таблицы, по которым и находят критическую точку, удовлетворяющую приведенным выше соотношениям.
- Для полученной реализации выборки
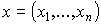 подсчитывают значение критерия, т.е.
подсчитывают значение критерия, т.е. 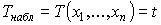 .
. - Если
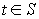 (например,
(например, 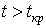 для правосторонней области S), то нулевую гипотезу отвергают; если же
для правосторонней области S), то нулевую гипотезу отвергают; если же 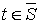 (
(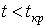 ), то нет оснований, чтобы отвергнуть гипотезу
), то нет оснований, чтобы отвергнуть гипотезу
13. уровень значимости – это вероятность ошибки первого рода при принятии решения (вероятность ошибочного отклонения нулевой гипотезы).
Альтернативные гипотезы принимаются тогда и только тогда, когда опровергается нулевая гипотеза. Это бывает в случаях, когда различия, скажем, в средних арифметических экспериментальной и контрольной групп настолько значимы (статистически достоверны), что риск ошибки отвергнуть нулевую гипотезу и принять альтернативную не превышает одного из трех принятых уровней значимости статистического вывода:
первый уровень — 5% (р=5%); где допускается риск ошибки в выводе в пяти случаях из ста теоретически возможных таких же экспериментов при строго случайном отборе испытуемых для каждого эксперимента;
второй уровень — 1%, т. е. соответственно допускается риск ошибиться только в одном случае из ста;
третий уровень — 0,1%, т. е. допускается риск ошибиться только в одном случае из тысячи.
Последний уровень значимости предъявляет очень высокие требования к обоснованию достоверности результатов эксперимента и потому редко используется. В педагогических исследованиях, не нуждающихся в очень высоком уровне достоверности, представляется разумным принять 5% уровень значимости.
Статистика критерия (Т) — некоторая функция от исходных данных, по значению которой проверяется нулевая гипотеза. Чаще всего статистика критерия является числовой функцией, но она может быть и любой другой функцией, например, многомерной функцией.
Всякое правило, на основе которого отклоняется или принимается нулевая гипотеза называется критерием для проверки данной гипотезы. Статистический критерий (критерий) – это случайная величина, которая служит для проверки статистических гипотез.
Критическая область – совокупность значений критерия, при котором нулевую гипотезу отвергают. Область принятия нулевой гипотезы (область допустимых значений) – совокупность значений критерия, при котором нулевую гипотезу принимают. При справедливости нулевой гипотезы вероятность того, что статистика критерия попадает в область принятия нулевой гипотезы должна быть равна 1-Ркр.
4.2 Общие принципы проверки статистических гипотез
Процедура проверки нулевой гипотезы в общем случае включает следующие этапы:
1. задается допустимая вероятность ошибки первого рода (Ркр=0,05)
2. выбирается статистика критерия (Т)
3. ищется область допустимых значений
4. по исходным данным вычисляется значение статистики Т
5. если Т (статистика критерия) принадлежит области принятия нулевой гипотезы, то нулевая гипотеза принимается (корректнее говоря, делается заключение, что исходные данные не противоречат нулевой гипотезе), а в противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза.[1] Это основной принцип проверки всех статистических гипотез.
Обычно первые три этапа выполняют профессиональные математики, а последние два – пользователи для своих частных данных.
В современных статистических пакетах на ЭВМ используются не стандартные уровни значимости, а уровни, подсчитываемые непосредственно в процессе работы с соответствующим статистическим методом. Эти уровни, обозначенные буквой P, могут иметь различное числовое выражение в интервале от 0 до 1, например, 0,7 0,23 0,012. Понятно, что в первых двух случаях полученные уровни значимости слишком велики и говорить о том, что результат значим нельзя. В последнем случае результаты значимы на уровне 12 тысячных. Это достоверный результат.
При проверке статистических гипотез с помощью статистических пакетов, программа выводит на экран вычисленное значение уровня значимости Р и подсказку о возможности принятия или неприятия нулевой гипотезы.
Если вычисленное значение Р превосходит выбранный уровень Ркр,
то принимается нулевая гипотеза, а в противном случае — альтернативная гипотеза. Чем меньше вычисленное значение Р, тем более исходные данные противоречат нулевой гипотезе.
Число степеней свободы у какого-либо параметра определяют как число опытов, по которым рассчитан данный параметр, минус количество одинаковых значений, найденных по этим опытам независимо друг от друга.
Величина Ф называется мощностью критерия и представляет собой вероятность отклонения неверной нулевой гипотезы, то есть вероятность правильного решения. Мощность критерия – вероятность попадания критерия в критическую область при условии, что справедлива альтернативная гипотеза. Чем больше Ф, тем вероятность ошибки 2-го рода меньше.
14. предположим, что по данным выборочной совокупности была построена линейная модель парной регрессии. Задача состоит в проверке значимости парного коэффициента корреляции между результативной переменной у и факторной переменной х.
Основная гипотеза состоит в предположении о незначимости парного коэффициента корреляции, т. е.
Н0:rxy=0.
Обратная или конкурирующая гипотеза состоит в предположении о значимости парного коэффициента корреляции, т. е.
Н1:rxy/=0.
Данные гипотезы проверяются с помощью t-критерия Стьюдента.
Наблюдаемое значение t-критерия (вычисленное на основе выборочных данных) сравнивают с критическим значением t-критерия, которое определяется по таблице распределения Стьюдента.
При проверке значимости парного коэффициента корреляции критическое значение t-критерия определяется как tкрит(a;n-h), где а – уровень значимости, (n-h) – число степеней свободы, которое определяется по таблице распределений t-критерия Стьюдента.
При проверке основной гипотезы вида Н0:rxy=0 наблюдаемое значение t-критерия Стьюдента рассчитывается по формуле:
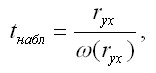
где ryx – выборочный парный коэффициент корреляции между результативной переменной у и факторной переменной х, который рассчитывается по формуле:
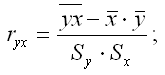
(ryx) – величина стандартной ошибки парного выборочного коэффициента корреляции.
Показатель стандартной ошибки парного выборочного коэффициента корреляции для линейной модели парной регрессии рассчитывается по формуле:
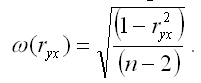
Если данное выражение подставить в формулу для расчёта наблюдаемого значения t-критерия для проверки гипотезы вида Н0:rxy=0, то получим:
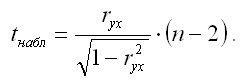
При проверке основной гипотезы возможны следующие ситуации:
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) по модулю больше критического значения t-критерия (определённого по таблице распределения Стьюдента), т. е.
tнабл|>t
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) по модулю меньше или равно критического значения t-критерия (определённого по таблице распреляционная зависимость между исследуемыми переменными отсутствует, и продолжение регрессионного анализа считается нецелесообразным.
Применение t-статистики Стьюдента для проверки гипотезы вида Н0:rxy=0 основано на выполнении двух условий:
1) если объём выборочной совокупности достаточно велик (n>=30);
2) коэффициент корреляции по модулю значительно меньше единицы:
0,45<=|ryx|<=0.75.
В том случае, если модуль парного выборочного коэффициента корреляции близок к единице, то гипотеза вида Н0:rxy=0 также может быть проверена с помощью z-статистики. Данный метод оценки значимости парного коэффициента корреляции был предложен Р. Фишером.
Между величиной z и парным выборочным коэффициентом корреляции существует отношение вида:
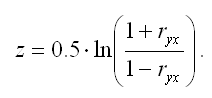
В связи с тем, что величина z является нормально распределённой величиной, то проверка основной гипотезы о незначимости парного коэффициента корреляции сводится к провреке основной гипотезы о незначимости величины z:
Н0:z=0.
Обратная или конкурирующая гипотеза состоит в предположении о значимости величины z, т. е.
Н1:z/=0.
Данные гипотезы проверяются с помощью t-критерия Стьюдента.
Наблюдаемое значение t-критерия (вычисленное на основе выборочных данных) сравнивают с критическим значением t-критерия, которое определяется по таблице распределения Стьюдента.
При проверке основной гипотезы вида Н0:z=0 наблюдаемое значение t-критерия Стьюдента рассчитывается по формуле:
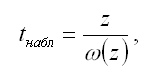
Показатель стандартной ошибки величины z для линейной модели парной регрессии рассчитывается по формуле:
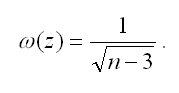
При проверке основной гипотезы возможны следующие ситуации:
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) по модулю больше критического значения t-критерия (определённого по таблице распределения Стьюдента), т. е. |tнабл|>t
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) по модулю меньше или равно критического значения t-критерия (определённого по таблице распреляционная зависимость между исследуемыми переменными отсутствует, и продолжение регрессионного анализа считается нецелесообразным.
15. Если с изменением значения одной из переменных вторая изменяется строго определенным образом, т.е. значению одной переменной обязательно соответствует одно или несколько точно заданных значений другой переменной, связь между ними является функциональной. Функциональная связь двух величин возможна лишь при условии, что вторая из них зависит только от первой и ни от чего более. Стохастически детерминированная связь не имеет ограничений и условий, присущих функциональной связи. Если с изменением значения одной из переменных вторая может в определенных пределах принимать любые значения с некоторыми вероятностями, но ее среднее значение или иные статистические (массовые) характеристики изменяются по определенному закону - связь является статистической. Иными словами, при статистической связи разным значениям одной переменной соответствуют разные распределения значений другой переменной. Корреляционной связью называют важнейший частный случай статистической связи, состоящий в том, что разным значениям одной переменной соответствуют различные средние значения другой. С изменением значения признака х закономерным образом изменяется среднее значение признака у; в то время как в каждом отдельном случае значение признака у (с различными вероятностями) может принимать множество различных значений.
16. Условное математическое ожидание M(Y|X=x) случайной переменной Y, рассматриваемое как функция x, т.е. M(Y|X=x)=f(x), называется функцией регрессии случайной переменной Y относительно X (или функцией регрессии Y по X). Точно также условное математическое ожидание M(X|Y=y), случайной переменной X, т.е. M(X|Y=y)=f(x), называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
Функции регрессии выражают математическое ожидание переменной Y (или X) для случая, когда другая переменная принимает определённое числовое значение, или, иначе говоря, функция M(Y|X=x) показывает, каково будет в среднем значение случайной переменной Y, если переменная X принимает значение x. Всё сказанное справедливо и для функции M(X|Y=y).
Становится очевидным, что функция регрессии имеет важное значение при статистическом анализе зависимостей между переменными и может быть использована для прогнозирования одной из случайных переменных, если известно значение другой случайной переменной. Точность такого прогноза определяется дисперсией условного распределения.
Несмотря на важность понятия функции регрессии, возможности её практического применения весьма ограничены. Для оценки функции регрессии необходимо знать аналитический вид двумерного распределения (X,Y). Только зная вид этого распределения, можно точно определить вид функции регрессии, а затем оценить его параметры. Однако для подобной оценки мы чаще всего располагаем лишь выборкой ограниченного объёма, по которой нужно найти вид двумерного распределения (X,Y), а затем вид функции регрессии. Это может привести к значительным ошибкам, т.к. одну и ту же совокупность точек (xi,yi) на плоскости можно одинаково успешно описать с помощью различных функций.
Для характеристики формы связи при изучении корреляционной зависимости пользуются понятием кривой регрессии. Кривой регрессии Y по X (или Y по X) называется условное среднее значение случайной переменной Y (Х), рассматриваемой как функция от x (у). Эта функция обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза.
17. Спецификация модели – подробное описание поведения объекта на математическом языке
В эконометрике широко используются методы статистики. Ставя цель дать количественное описание взаимосвязей между экономическими переменными, эконометрика прежде всего связана с методами регрессии и корреляции.
В зависимости от количества факторов, включенных в уравнение регрессии, принято различать простую (парную) и множественную регрессию.
Простая регрессия представляет собой регрессию между двумя переменными – y и x, т.е. модель вида
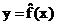 , где y – зависимая переменная (результативный признак)
, где y – зависимая переменная (результативный признак)
x – независимая, или объясняющая, переменная (признак-фактор).
Множественная регрессия соответственно представляет собой регрессию результативного признака с двумя и большим числом факторов, т.е. модель вида
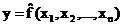
Любое эконометрическое исследование начинается со спецификации модели, т.е. с формулировки вида модели, исходя из соответствующей теории связи между переменными. Иными словами, исследование начинается с теории, устанавливающей связь между явлениями.
Прежде всего, из круга факторов, влияющих на результативный признак, необходимо выделить наиболее существенно влияющие факторы. Парная регрессия достаточна, если имеется доминирующий фактор, который используется в качестве объясняющей переменной. Предположим, что выдвигается гипотеза о том, что величина спроса y на товар A находится в обратной зависимости от цены x, т.е. 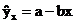 . В этом случае необходимо знать, какие остальные факторы предполагаются неизменными, возможно, в дальнейшем их придется учесть в модели и от простой регрессии перейти к множественной.
. В этом случае необходимо знать, какие остальные факторы предполагаются неизменными, возможно, в дальнейшем их придется учесть в модели и от простой регрессии перейти к множественной.
Уравнение простой регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем в целом по совокупности наблюдений. В уравнении регрессии корреляционная по сути связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией. Практически в каждом отдельном случае величина y складывается из двух слагаемых:
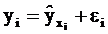 , где yi – фактическое значение результативного признака
, где yi – фактическое значение результативного признака
yxi – теоретическое значение результативного признака, найденной исходя из соответствующей математической функции связи y и x, т.е. из уравнения регрессии
ei – случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии
Случайная величина e также называется возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенности измерения. Ее присутствие в модели порождено тремя источниками:
- выборочный характер исходных данных
- особенности измерения переменных.
От правильно выбранной спецификации модели зависит величина случайных ошибок: они тем меньше, чем в большей мере теоретическое значение результативного признака 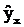 подходят к фактическим данным y.
подходят к фактическим данным y.
К ошибкам спецификации будут относиться не только неправильный выбор той или иной математической функции для , но и недоучет в уравнении регрессии какого-либо существенного фактора, т.е. использование парной регрессии вместо множественной.
Наряду с ошибками спецификации могут иметь место ошибки выборки, поскольку исследователь чаще всего имеет дело с выборочными данными при установлении закономерной связи между признаками. Ошибки выборки могут иметь место в силу неоднородности данных в исходной статистической совокупности, что, как правило, бывает при изучении экономических процессов. Если совокупность неоднородна, то уравнение регрессии не имеет практического смысла. Для получения хорошего результата обычно исключают из совокупности единицы с аномальными значениями исследуемых признаков. И в этом случае результаты регрессии представляют собой выборочные характеристики.
Использование временной информации также представляет собой выборку из всего множества хронологических дат. Изменив временной интервал, можно получить другие результаты регрессии.
Наибольшую опасность в практическом использовании методов регрессии представляют ошибки измерения. Если ошибки спецификации можно уменьшит, изменяя форму модели, а ошибки выборки – увеличивая объем исходных данных, то ошибки измерения практически сводят на нет все усилия по количественной оценке связи между признаками. Особенно велика роль ошибок измерения при исследовании на макроуровне.
Предполагая, что ошибки измерения сведены к минимуму, основное внимание в эконометрических исследованиях уделяется ошибкам спецификации модели.
В парной регрессии выбор вида математической функции может быть осуществлен тремя методами:
- графическим
- аналитическим, т.е. исходя из теории изучаемой взаимосвязи
- экспериментальным
При изучении зависимости между двумя признаками графический метод подбора уравнения регрессии достаточно нагляден. Он основан на поле корреляции.
Основные типы кривых, используемых при количественной оценке:
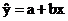
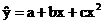
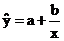
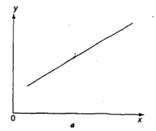
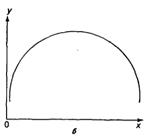
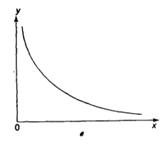
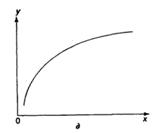
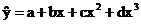
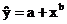
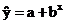
Также используется:
- 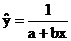
- 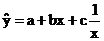
- 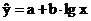
- 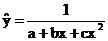
Значительный интерес представляет аналитический метод выбора типа уравнения регрессии. Он основан на изучении материальной природы связи исследуемых признаков.
Пусть, например, изучается потребность предприятия в электроэнергии у в зависимости от объема выпускаемой продукции x.
Все потребление электроэнергии y можно подразделить на 2 части:
- не связанное с производством продукции (a)
- непосредственно связанное с объемом выпускаемой продукции, пропорционально возрастающее с увеличением объемы выпуска (bx)
Тогда зависимость потребления электроэнергии от объема продукции можно выразить уравнением регрессии вида
Если затем разделить обе части уравнения на величину объемы выпуска продукции x, то получим выражение зависимости удельного расхода электроэнергии на единицу продукции 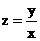 от объема выпущенной продукции x в виде уравнения равносторонней гиперболы
от объема выпущенной продукции x в виде уравнения равносторонней гиперболы 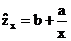
При обработке информации на компьютере выбор уравнении регрессии обычно осуществляется экспериментальным методом, т.е. путем сравнения величины остаточной дисперсии Dост рассчитанной при разных моделях.
Если уравнение регрессии проходит через все точки корреляционного поля, что возможно только при функциональной связи, когда все точки лежат на линии регрессии 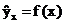 , то фактические значения результативного признака совпадают с теоретическими
, то фактические значения результативного признака совпадают с теоретическими 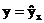 , т.е. они полностью обусловлены влиянием фактора x. В этом случае остаточная дисперсия Dост=0. В практических исследованиях, как правило, имеет место некоторое рассеяние точек относительно линии регрессии. Оно обусловлено влиянием прочих не учитываемых в уравнении регрессии факторов. Иными словами, имеют место отклонения фактических данных от теоретических
, т.е. они полностью обусловлены влиянием фактора x. В этом случае остаточная дисперсия Dост=0. В практических исследованиях, как правило, имеет место некоторое рассеяние точек относительно линии регрессии. Оно обусловлено влиянием прочих не учитываемых в уравнении регрессии факторов. Иными словами, имеют место отклонения фактических данных от теоретических 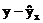 . Величина этих отклонений и лежит в основе расчета остаточной дисперсии
. Величина этих отклонений и лежит в основе расчета остаточной дисперсии 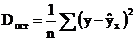
Чем меньше величина остаточной дисперсии, тем в меньшей мере наблюдается влияние прочих не учитываемых в уравнении регрессии факторов, лучше уравнении регрессии подходит к исходным данным. При обработке статистических данных на компьютере перебираются разные математические функции в автоматическом режиме и из них выбирается та, для которой остаточная дисперсия является наименьшей.
Если остаточная дисперсия оказывается примерно одинаковой для нескольких функций, то на практике предпочтение отдается более простым видам функций, ибо они в большей степени поддаются интерпретации и требуют меньшего объема наблюдений. Результаты многих исследований подтверждают, что число наблюдении должно в 6-7 раз превышать число рассчитываемых параметров при переменной x.
18. Регрессия (лат. regressio - обратное движение, переход от более сложных форм развития к менее сложным) - одно из основных понятий в теории вероятности и математической статистике, выражающее зависимость среднего значения случайной величины от значений другой случайной величины или нескольких случайных величин. Это понятие введено Фрэнсисом Гальтоном в 1886. [9]
Теоретическая линия регрессии - это та линия, вокруг которой группируются точки корреляционного поля и которая указывает основное направление, основную тенденцию связи. [2, с.256]
Теоретическая линия регрессии должна отображать изменение средних величин результативного признака «y» по мере изменения величин факторного признака «x» при условии полного взаимопогашения всех прочих – случайных по отношению к фактору «x» - причин. Следовательно, эта линия должна быть проведена так, чтобы сумма отклонений точек поля корреляции от соответствующих точек теоретической линии регрессии равнялась нулю, а сумма квадратов этих отклонений была ба минимальной величиной.
y=f(x) - уравнение регрессии - это формула статистической связи между переменными.
Прямая линия на плоскости (в пространстве двух измерений) задается уравнением y=a+b*х. Более подробно: переменная y может быть выражена через константу (a) и угловой коэффициент (b), умноженный на переменную x. Константу иногда называют также свободным членом, а угловой коэффициент - регрессионным или B-коэффициентом. [8]
Важным этапом регрессионного анализа является определение типа функции, с помощью которой характеризуется зависимость между признаками. Главным основанием должен служить содержательный анализ природы изучаемой зависимости, ее механизма. Вместе с тем теоретически обосновать форму связи каждого из факторов с результативным показателем можно далеко не всегда, поскольку исследуемые социально-экономические явления очень сложны и факторы, формирующие их уровень, тесно переплетаются и взаимодействуют друг с другом. Поэтому на основе теоретического анализа нередко могут быть сделаны самые общие выводы относительно направления связи, возможности его изменения в исследуемой совокупности, правомерности использования линейной зависимости, возможного наличия экстремальных значений и т.п. Необходимым дополнением такого рода предположений должен быть анализ конкретных фактических данных.
Приблизительно представление о линии связи можно получить на основе эмпирической линии регрессии. Эмпирическая линия регрессии обычно является ломанной линией, имеет более или менее значительный излом. Объясняется это тем, что влияние прочих неучтенных факторов, оказывающих воздействие на вариацию результативного признака, в средних погашается неполностью, в силу недостаточно большого количества наблюдений, поэтому эмпирической линией связи для выбора и обоснования типа теоретической кривой можно воспользоваться при условии, что число наблюдений будет достаточно велико. [2, с.257]
Одним из элементов конкретных исследований является сопоставление различных уравнений зависимости, основанное на использовании критериев качества аппроксимации эмпирических данных конкурирующими вариантами моделей Наиболее часто для характеристики связей экономических показателей используют следующие типы функций:
1. Линейная: 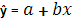
2. Гиперболическая: 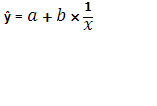
3. Показательная:
4. Параболическая: 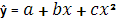
5. Степенная: 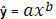
6. Логарифмическая: 
7. Логистическая: 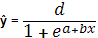 [2, c.258]
[2, c.258]
Модель с одной объясняющей и одной объясняемой переменными – модель парной регрессии. Если объясняющих (факторных) переменных используется две или более, то говорят об использовании модели множественной регрессии. При этом, в качестве вариантов могут быть выбраны линейная, экспоненциальная, гиперболическая, показательная и другие виды функций, связывающие эти переменные.
Для нахождения параметров а и b уравнения регрессии используют метод наименьших квадратов. При применении метода наименьших квадратов для нахождения такой функции, которая наилучшим образом соответствует эмпирическим данным, считается, что сумка квадратов отклонений эмпирических точек от теоретической линии регрессии должна быть величиной минимальной.
Критерий метода наименьших квадратов можно записать таким образом:
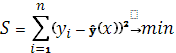
или
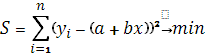
Следовательно, применение метода наименьших квадратов для определения параметров a и b прямой, наиболее соответствующей эмпирическим данным, сводится к задаче на экстремум. [2, c.258]
Относительно оценок можно сделать следующие выводы:
1. Оценки метода наименьших квадратов являются функциями выборки, что позволяет их легко рассчитывать.
2. Оценки метода наименьших квадратов являются точечными оценками теоретических коэффициентов регрессии.
3. Эмпирическая прямая регрессии обязательно проходит через точку x, y.
4. Эмпирическое уравнение регрессии построено таким образом, что сумма отклонений 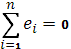 .
.
Графическое изображение эмпирической и теоретической линии связи представлено на рисунке 1.
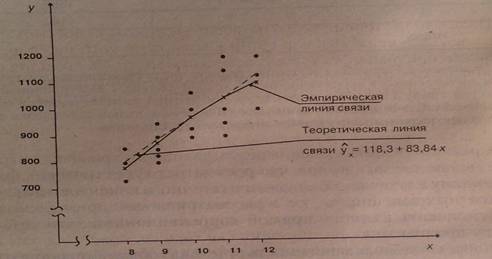
рис. 1.
Параметр b в уравнении – это коэффициент регрессии. При наличии прямой корреляционной зависимости коэффициент регрессии имеет положительное значение, а в случае обратной зависимости коэффициент регрессии – отрицательный. Коэффициент регрессии показывает на сколько в среднем изменяется величина результативного признака «y» при изменении факторного признака «x» на единицу. Геометрически коэффициент регрессии представляет собой наклон прямой линии, изображающей уравнение корреляционной зависимости, относительно оси «x» (для уравнения ).
Раздел многомерного статистического анализа, посвященный восстановлению зависимостей, называется регрессионным анализом. Термин «линейный регрессионный анализ» используют, когда рассматриваемая функция линейно зависит от оцениваемых параметров (от независимых переменных зависимость может быть произвольной). Теория оценивания
неизвестных параметров хорошо развита именно в случае линейного регрессионного анализа. Если же линейности нет и нельзя перейти к линейной задаче, то, как правило, хороших свойств от оценок ожидать не приходится. Продемонстрируем подходы в случае зависимостей различного вида. Если зависимость имеет вид многочлена (полинома). Если расчёт корреляции характеризует силу связи между двумя переменными, то регрессионный анализ служит для определения вида этой связи и дает возможность для прогнозирования значения одной (зависимой) переменной отталкиваясь от значения другой (независимой) переменной. Для проведения линейного регрессионного анализа зависимая переменная должна иметь интервальную (или порядковую) шкалу. В то же время, бинарная логистическая регрессия выявляет зависимость дихотомической переменной от некой другой переменной, относящейся к любой шкале. Те же условия применения справедливы и для пробит-анализа. Если зависимая переменная является категориальной, но имеет более двух категорий, то здесь подходящим методом будет мультиномиальная логистическая регрессия можно анализировать и нелинейные связи между переменными, которые относятся к интервальной шкале. Для этого предназначен метод нелинейной регрессии. [10]
19. Суть метода наименьших квадратов (МНК).
Задача заключается в нахождении коэффициентов линейной зависимости, при которых функция двух переменных а и b 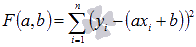 принимает наименьшее значение. То есть, при данных а и b сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов.
принимает наименьшее значение. То есть, при данных а и b сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов.
Таким образом, решение примера сводится к нахождению экстремума функции двух переменных.
20. Для определения неизвестных параметров уравнения регрессии используют нормальную систему уравнения:
21. 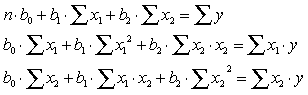
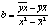
Параметр b называется коэффициентом регрессии. Его величина показывает
среднее изменение результата с изменением фактора на одну единицу. Оценку
коэффициента регрессии можно получить не обращаясь к методу наименьших
квадратов. Альтернативную оценку параметра b можно найти исходя из
содержания данного коэффициента: изменение результата 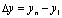
сопоставляют с изменением фактора 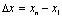
Общая сумма квадратов отклонений индивидуальных значений результативного
признака у от среднего значения 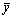
вызвана влиянием множества причин. Условно разделим всю совокупность причин на
две группы: изучаемый фактор х и прочие факторы.
Если фактор не оказывает влияния на результат, то линия регрессии на графике
параллельна оси ох и 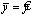
.Тогда вся дисперсия результативного признака обусловлена воздействием прочих
факторов и общая сумма квадратов отклонений совпадет с остаточной. Если же
прочие факторы не влияют на результат, то у связан с х
функционально и остаточная сумма квадратов равна нулю. В этом случае сумма
квадратов отклонений, объясненная регрессией, совпадает с общей суммой
квадратов.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет
место их разброс как обусловленный влиянием фактора х, т. е. регрессией у
по х, так и вызванный действием прочих причин (необъясненная вариация).
Пригодность линии регрессии для прогноза зависит от того, какая часть общей
вариации признака у приходится на объясненную вариацию
Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет
больше остаточной суммы квадратов, то уравнение регрессии статистически значимо
и фактор х оказывает существенное воздействие на результат у
Любая сумма квадратов отклонений связана с числом степеней свободы, т.
е. с числом свободы независимого варьирования признака. Число степеней свободы
связано с числом единиц совокупности n ис числом определяемых по ней констант.
Применительно к исследуемой проблеме число степеней свободы должно показать,
сколько независимых отклонений из п возможных требуется для
образования данной суммы квадратов.
Свободный член (сдвиг) b0, равный 1,61, формально надлежит понимать следующим образом: объем продажи молока котом Матроскиным, когда среди покупателей отсутствуют бабушки с внучками, и нет компаньона Шарика (занят фотоохотой), составляет 1,61 литров в день. Однако мы полагаем, что в указанной совокупности исходных данных нет подобных примеров (всегда среди покупателей окажутся бабушки с внучками, а Шарик помогает ежедневно). Поэтому сдвиг b0 следует обсуждать как вспомогательную величину, необходимую для получения оптимальных прогнозов, и не истолковывать ее столь буквально.? Коэффициенты регрессии b1 и b2 следует рассматривать как степень влияния каждой из переменных (присутствие бабушек с внучками и вклад коммерческого таланта Шарика) на размер продажи, если все другие независимые переменные остаются неизменными. Так, коэффициент b1, равный 0,06, указывает, что (при прочих равных условиях) повышение доли бабушек с внучками на 1 % приводит к возрастанию продажи молока на 0,06 литров в день. Анализируя коэффициент b2, можно заметить, что увеличение относительного участия Шарика на 1 % приводит также к повышению продажи, этот прирост составляет почти такую же величину - 0,07 л/день.
Еще раз заметим, что все названные коэффициенты регрессии отражают влияние на исследуемый параметр у только какой-то одной переменной х при непременном условии, что все другие переменные (факторы) не меняются. Например, применительно к коэффициенту b2 это нужно понимать так: указанное влияние коммерческой помощи Шарика проявляется при условии, когда сохраняется среди покупателей неизменной доля старушек с внучками.
22. В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз уi при xp = xi, т. е. путем подстановки в уравнение регрессии 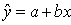 соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки и соответственно интервальной оценкой прогнозного значения (у*).
соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки и соответственно интервальной оценкой прогнозного значения (у*).
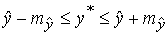
Подставим в уравнение регрессии выражение параметра
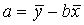
Тогда уравнение регрессии примет вид:
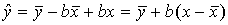
Отсюда вытекает что стандартная ошибка 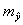 зависит от ошибки Н среднего и ошибки коэффициента регрессии b.
зависит от ошибки Н среднего и ошибки коэффициента регрессии b.
После преобразований получим следующее выражение для расчета стандартной ошибки предсказываемого по линии регрессии значения:
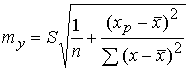
Данная формула стандартной ошибки предсказываемого среднего значения у при заданном значении х характеризует ошибку положения линии регрессии. Как видно из формулы, величина стандартной ошибки достигает минимума при 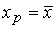 и возрастает по мере того, как удаляется от среднего в любом направлении.
и возрастает по мере того, как удаляется от среднего в любом направлении.
Иными словами, можно ожидать наилучшие результаты прогноза, если x находится в центре области наблюдения. Если же значение x находится за пределами наблюдаемых значений, то результаты прогноза ухудшаются.
На графике доверительные границы для ух представляют собой гиперболы, расположенные по обе стороны от линии регрессии.
Рис. 8.1 показывает, как изменяются пределы в зависимости от изменения xk: две гиперболы по обе стороны от линии регрессии определяют 95% -ные доверительные интервалы для среднего значения у при заданном значении х.
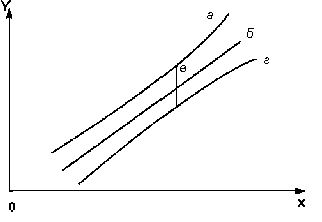
Рис.8.1. Доверительный интервал линии регрессии:
а – верхняя доверительная граница;
б – линия регрессии;
в – доверительный интервал;
г – нижняя доверительная граница.
Однако фактические значения у варьируют около среднего значения 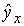 . Индивидуальные значения у могут отклоняться о на величину случайной ошибки е, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2. Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку, но и случайную ошибку S.
. Индивидуальные значения у могут отклоняться о на величину случайной ошибки е, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2. Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку, но и случайную ошибку S.
Ширина интервала зависит от количества наблюдений и величины дисперсии V(x).
юбое эконометрическое исследование начинается со спецификации модели, т.е. с формулировки вида модели, исходя из соответствующей теории связи между переменными. Иными словами, исследование начинается с теории, устанавливающей связь между явлениями.
Прежде всего, из круга факторов, влияющих на результативный признак, необходимо выделить наиболее существенно влияющие факторы. Парная регрессия достаточна, если имеется доминирующий фактор, который используется в качестве объясняющей переменной. Предположим, что выдвигается гипотеза о том, что величина спроса y на товар A находится в обратной зависимости от цены x, т.е. . В этом случае необходимо знать, какие остальные факторы предполагаются неизменными, возможно, в дальнейшем их придется учесть в модели и от простой регрессии перейти к множественной.
Уравнение простой регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем в целом по совокупности наблюдений. В уравнении регрессии корреляционная по сути связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией. Практически в каждом отдельном случае величина y складывается из двух слагаемых:
, где yi – фактическое значение результативного признака
yxi – теоретическое значение результативного признака, найденной исходя из соответствующей математической функции связи y и x, т.е. из уравнения регрессии
ei – случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии
Случайная величина e также называется возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенности измерения. Ее присутствие в модели порождено тремя источниками:
- выборочный характер исходных данных
- особенности измерения переменных.
23.
От правильно выбранной спецификации модели зависит величина случайных ошибок: они тем меньше, чем в большей мере теоретическое значение результативного признака подходят к фактическим данным y.
К ошибкам спецификации будут относиться не только неправильный выбор той или иной математической функции для , но и недоучет в уравнении регрессии какого-либо существенного фактора, т.е. использование парной регрессии вместо множественной.
Наряду с ошибками спецификации могут иметь место ошибки выборки, поскольку исследователь чаще всего имеет дело с выборочными данными при установлении закономерной связи между признаками. Ошибки выборки могут иметь место в силу неоднородности данных в исходной статистической совокупности, что, как правило, бывает при изучении экономических процессов. Если совокупность неоднородна, то уравнение регрессии не имеет практического смысла. Для получения хорошего результата обычно исключают из совокупности единицы с аномальными значениями исследуемых признаков. И в этом случае результаты регрессии представляют собой выборочные характеристики.
Использование временной информации также представляет собой выборку из всего множества хронологических дат. Изменив временной интервал, можно получить другие результаты регрессии.
Наибольшую опасность в практическом использовании методов регрессии представляют ошибки измерения. Если ошибки спецификации можно уменьшит, изменяя форму модели, а ошибки выборки – увеличивая объем исходных данных, то ошибки измерения практически сводят на нет все усилия по количественной оценке связи между признаками. Особенно велика роль ошибок измерения при исследовании на макроуровне.
Предполагая, что ошибки измерения сведены к минимуму, основное внимание в эконометрических исследованиях уделяется ошибкам спецификации модели.
В парной регрессии выбор вида математической функции может быть осуществлен тремя методами:
- графическим
- аналитическим, т.е. исходя из теории изучаемой взаимосвязи
- экспериментальным
При изучении зависимости между двумя признаками графический метод подбора уравнения регрессии достаточно нагляден. Он основан на поле корреляции. Значительный интерес представляет аналитический метод выбора типа уравнения регрессии. Он основан на изучении материальной природы связи исследуемых признаков.
Пусть, например, изучается потребность предприятия в электроэнергии у в зависимости от объема выпускаемой продукции x.
Все потребление электроэнергии y можно подразделить на 2 части:
- не связанное с производством продукции (a)
- непосредственно связанное с объемом выпускаемой продукции, пропорционально возрастающее с увеличением объемы выпуска (bx)
Тогда зависимость потребления электроэнергии от объема продукции можно выразить уравнением регрессии вида
Если затем разделить обе части уравнения на величину объемы выпуска продукции x, то получим выражение зависимости удельного расхода электроэнергии на единицу продукции от объема выпущенной продукции x в виде уравнения равносторонней гиперболы
При обработке информации на компьютере выбор уравнении регрессии обычно осуществляется экспериментальным методом, т.е. путем сравнения величины остаточной дисперсии Dост рассчитанной при разных моделях.
Если уравнен

