2015-05-10
2015-05-10 502
502Задана выборка, которая характеризует уровни потребления продуктов в некоторых странах. Выполните классификацию. Определите к какой группе относится Беларусь.
| страна | мясо | масло | сахар | пиво | фрукты | хлеб |
| Австралия | 2.6 | 8.2 | ||||
| Австрия | 5.3 | |||||
| Азербайджан | 4.1 | 13.4 | 7.9 | |||
| Армения | 3.7 | 4.3 | 6.5 | |||
| Беларусь | 3.6 | 5.4 | ||||
| Бельгия | 6.9 | |||||
| Болгария | 9.5 | |||||
| Великобритания | 3.5 | 8.8 | ||||
| Венгрия | 1.7 | 10.9 | ||||
| Германия | 6.8 | 8.1 | ||||
| Грузия | 3.8 | 9.8 | ||||
| Греция | 8.8 | |||||
| Дания | 10.3 | |||||
| Ирландия | 3.3 | 9.5 | ||||
| Испания | 0.4 | 8.9 | ||||
| Италия | 2.2 | 9.6 | ||||
| Казахстан | 4.2 | 19.2 | 7.2 | |||
| Канада | 3.1 | 7.4 | ||||
| Киргизия | 4.1 | 6.7 | ||||
| Россия | 3.9 |
Выполните решения задач 4-6
Занятие 3 Дискриминантный анализ
Кластерный анализ предназначен для того, чтобы сгруппировать элементы в однородные группы (кластеры). Эта однородность определяется на основании признаков (факторов), которые включаются в качестве параметров кластерного анализа. Число групп заранее неизвестно. Нет результативного признака или зависимой переменной. Кластерный анализ часто используется для апостериорной сегментации рынка.
Дискриминантный анализ действует несколько иначе. Рассматривается некоторая "зависимая" переменная, определяющая наше мнение (мнение эксперта) относительно предстоящей группировки. Далее определяются линейные классификационные модели, которые позволяет "предсказать" поведение новых элементов в терминах зависимой переменной на основании измерения ряда независимых переменных (факторов, показателей), которыми они характеризуются.
Например, есть три уровня лояльности потребителя к определенной марке товара и есть измерения ряда показателей его стиля жизни. Строим линейные модели, в которых подстановка значений из стилевых переменных сможет дать ответ на вопрос о лояльности потребителя к данному товару. Эта модель более информативна, так как дает "силу влияния". Дискриминантный анализ используется в априорной сегментации рынка.
Рассмотрим процедуру решения практической задачи методом дискриминантного анализа в системе STATISTICA. Разберем принцип проведения дискриминантного анализа (точнее, формирование обучающих выборок) на основе данных представленных ниже.
Имеются данные по 20 сельскохозяйственным предприятиям, которые были выбраны и отнесены к соответствующим группам экспертным способом.
Показатели-аргументы, участвующие в классификации, следующие:
X 1 – прибыль (тыс. р.);
X 2 – валовая продукция на 1 работника, занятого в сельском хозяйстве (тыс. р.);
X 3 – валовая продукция на 1 га сельхозугодий (тыс. р.);
X 4 – производство молока на 1 га сельхозугодий (кг);
X 5 – производство мяса на 1 га сельхозугодий (кг);
X 6 – выручка от реализации продукции на 1 работника (тыс. р.);
X 7 – выручка на 1 га сельхозугодий(тыс. р.)
| X 1 | X 2 | X 3 | X 4 | X 5 | X 6 | X 7 | CLASS1 | |
| -107,000 | 5868,000 | 531,000 | 450,000 | 63,000 | 22,300 | 1608,000 | ||
| -903,000 | 6330,000 | 636,000 | 401,000 | 69,000 | 17,600 | 1768,000 | ||
| -18,000 | 6793,000 | 620,000 | 487,000 | 104,000 | 19,400 | 1775,000 | ||
| 1,300 | 4731,000 | 447,000 | 405,000 | 64,000 | 10,400 | 979,000 | ||
| 403,100 | 2969,000 | 382,000 | 274,000 | 29,000 | 5,700 | 728,000 | ||
| -205,000 | 4924,000 | 284,000 | 292,000 | 35,000 | 17,500 | 1010,000 | ||
| -256,000 | 7622,000 | 342,000 | 223,000 | 26,000 | 14,100 | 634,000 | ||
| -2142,00 | 4318,000 | 257,000 | 151,000 | 33,000 | 16,500 | 985,000 | ||
| -1394,00 | 3140,000 | 218,000 | 241,000 | 47,000 | 8,500 | 592,000 | ||
| -1571,00 | 4617,000 | 171,000 | 137,000 | 13,000 | 13,100 | 484,000 | ||
| -728,300 | 5448,000 | 348,000 | 215,000 | 28,000 | 5,700 | 367,000 | ||
| -1796,00 | 2902,000 | 161,000 | 182,000 | 22,000 | 11,400 | 631,000 | ||
| -1955,20 | 3634,000 | 334,000 | 361,000 | 59,000 | 10,100 | 925,000 | ||
| -1294,00 | 3499,000 | 204,000 | 129,000 | 27,000 | 6,800 | 398,000 | ||
| -1500,00 | 6368,000 | 288,000 | 169,000 | 27,000 | 13,300 | 601,000 | ||
| -1879,00 | 3058,000 | 169,000 | 86,000 | 23,000 | 5,600 | 307,000 | ||
| -197,000 | 5110,000 | 82,000 | 57,000 | 11,000 | 1,100 | 174,000 | ||
| -2310,70 | 4166,000 | 207,000 | 183,000 | 32,000 | 9,800 | 487,000 | ||
| -1437,00 | 5168,000 | 151,000 | 96,000 | 8,000 | 10,700 | 359,000 | ||
| -482,000 | 2061,000 | 78,000 | 47,000 | 4,000 | 2,900 | 110,300 |
Скопируйте через буфер обмена данные в систему STATISTICA., и отформатируйте таблицу, добавьте заголовки переменным, удалите лишние регистры и переменные.
Из переключателя модулей STATISTICA откройте модуль Discriminant Analysis (Дискриминантный Анализ).Укажите переменные
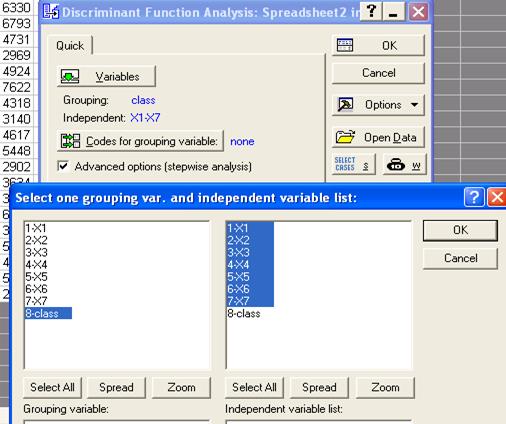
Установите флажок Stepwise Analysis, нажмите ОК
Перейдете в стартовое меню.
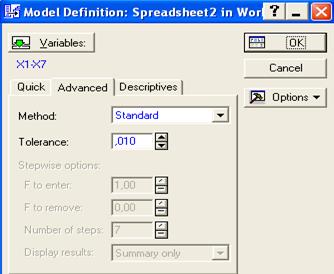
В диалоговом окне Method предложен выбор методавыборазначимых переменных. Method может быть задан Standfrt (Стандартный), Forward stepwise (Пошаговый с включением) и Backward stepwise (Пошаговый с исключением). Descriptive (Описательные статистики)выдает данные описательных статистик переменных. Выберем в качестве метода (Method) – Standard и нажмем OK

Перейдете в стартовое меню дискриминантного анализа.
. В ходе вычислений системой получены результаты, которые представлены в окне Discriminant Function Analisis Results (Результаты анализа дискриминантных функций) После выбора метода модели и задания или просмотра необходимых параметров, нажав OK в диалоговом окне Model Difinition (Определение модели)получим результаты дискриминантных функций.
Информационная часть диалогового окна Discriminant Function Analisis Results (Результаты Анализа Дискриминантных Функций) сообщает, что:
Number of variables in the model (число переменных в модели) =7;
Wilks lambda (значение лямбды Уилкса) = 0,0099910;
Approx. F (28, 33) (приближенное значение F – статистики, связанной с лямбда Уилкса) = 3,130316;
P – уровень значимости F – критерия для значения 3,130316.
В качестве проверки корректности обучающих выборок посмотрим результаты классификационной матрицы, нажав кнопку Classification matrix предварительно выбрав Same for all groups в правой части окна Discriminant Function Analisis Results.
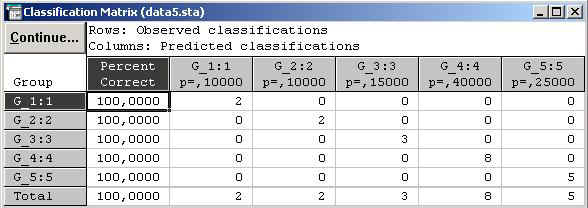
Из классификационной матрицы можно сделать вывод, что объекты были правильно отнесены экспертным способом к выделенным группам. Но если есть предприятия, неправильно отнесенные к соответствующим группам, можно посмотреть Classification of cases (Классификация случаев)
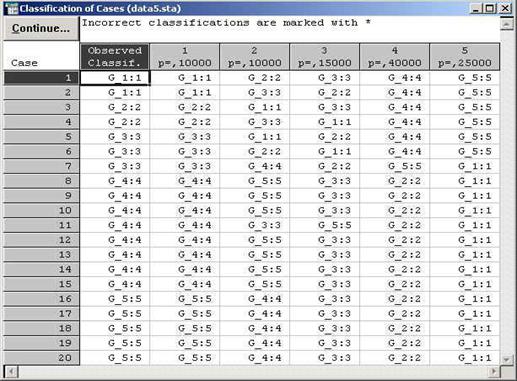
В таблице классификации случаев, некорректно отнесенные предприятия помечаются звездочкой (*). Таким образом, задача получения корректных обучающих выборок состоит в том, чтобы исключить из обучающих выборок те объекты, которые по своим показателям не соответствуют большинству предприятий, образующих однородную группу.
Для этого с помощью метрики Махаланобиса определятся расстояние от всех n объектов до центра тяжести каждой группы (вектор средних), определяемых по обучающей выборке. Отнесение экспертом i -го объекта в j -ю группу считается ошибочным, если расстояние Махаланобиса от объекта до центра его группы значительно выше, чем от него до центра других групп, а апостериорная вероятность попадания в свою группу ниже критического значения. В этом случае объект считается некорректно отнесенным и должен быть исключен из выборки.
Процедура исключения объекта из обучающих выборок состоит в том, что в таблице исходных данных у объекта, который должен быть исключен из выборки (он помечен "*"), убирается номер принадлежности к этой группе, после чего процесс тестирования повторяется. По предположению, сначала убирается тот объект, который наиболее не подходит к определенной группе, т.е. у которого наибольшее расстояние Махаланобиса и наименьшая апостериорная вероятность.
При удалении очередного объекта из группы нужно помнить, что при этом смещается центр тяжести группы (вектор средних), так как он определяется по оставшимся наблюдениям. После удаления очередного предприятия из списка обучающих выборок не исключено, что появятся новые некорректно отнесенные предприятия, которые до удаления были учтены как правильно отнесенные. Поэтому данную процедуру нужно проводить, удаляя на каждом шаге лишь по одному объекту и возвращая его обратно в обучающие выборки. Если при удаления этого объекта произошли слишком сильные изменения (большинство предприятий, которые были отнесены как правильные, помечаются как некорректно отнесенные предприятия).
Процедура исключения наблюдений продолжается до тех пор, пока общий коэффициент корректности в классификационной матрице достигнет 100%, т.е. все наблюдения обучающих выборок будут правильно отнесены к соответствующим группам.
Результаты полученных обучающих выборок, представлены в окне Discriminant Function Analisis Results (Результаты Анализа Дискриминантных Функций). В результате проведенного анализа общий коэффициент корректности обучающих выборок должен быть равен 100%.
Классификация объектов. На основе полученных обучающих выборок можно проводить повторную классификацию тех объектов, которые не попали в обучающие выборки, и любых других объектов, подлежащих группировке. Для решения данной задачи, существуют два варианта: первый – провести классификацию на основе дискриминантных функций, второй – на основе классификационных функций.
В первом случае необходимо, не закрывая диалога диалогового окна Discriminant Function Analisis Results,добавить в таблицу исходных скорректированных данных новые случаи. Для того чтобы понять, к какому классу относится этот объект, нажмите кнопку Posterior probabilities (Апостериорные вероятности). После этого вы увидите таблицу с апостериорными вероятностями. К тем группам (классам), которые будут иметь максимальные вероятности, можно отнести новые случаи.
Во втором варианте необходимо в окне диалогового окна Discriminant Function Analisis Results нажать кнопку Classification functions. Появится окно, из которого можно выписать классификационные функции для каждого класса Например, для первых классов функции имеют вид:
D 1= –37.5227+0.0016 X 1–0.0014 X 2+0.0980 X 3-0.0024 X 4+ 0.2109 X 5+
+2.4656 X 6–0.0288 X 7;
D 2= –20.4338+0.0009 X 1-0.0004 X 2+0.0631 X 3–0.0083 X 4+ 0.2369 X 5+
+1.5020 X 6–0.0188 X 7.
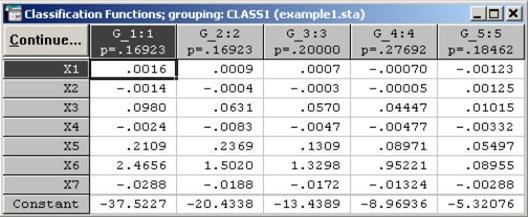
С помощью этих функций можно будет в дальнейшем классифицировать новые случаи. Новые случаи будут относиться к тому классу, для которого классифицированное значение будет максимальное.
Самостоятельно проведите дискриминантный анализ выборки на стр.31
Занятие 4. Факторный анализ в системе Statistica.
Основная задача факторного анализа определить скрытые факторы, которые существенно влияют на статистическую картину исследуемого явления. Количество скрытых факторов меньше количества критериев используемых для исследований выборок, но они достаточно ярко отражают все исследуемое явление.
Элементы ситуационной выборки –суть n мерные вектора, могут образовывать различные линейные комбинации вида
С1Х1+С2Х2+….+СnХn, где Сi некоторая числовые константы.
Назовем любую такую комбинацию критериев фактором выборки. Среди всех факторов важнейшими являются факторы, которые не корелируют между собой. Их называют главными(принципиальными) компонентами выборки. Для вычисления главных компонент необходимо найти такое линейное преобразование выборки, которое приводит матрицу R к диагональному виду.
Это линейное преобразование составляется из собственных векторов матрицы R.
Для вычисления собственных векторов необходимо сначала вычислить собственные значения матрицы R. Множество собственных значений R, образует спектр матрицы, вектор λ: [λ1 λ2 λ3…… λn ], а затем для каждого λi вычислить собственный вектор
βj: [ β1j β2j β3j ….. βnj ] на практике, обычно не вычисляют все собственные вектора матрицы R. Обычно ограничиваются одним или двумя векторами соответствующие наибольшим собственным значениям λi спектра матрицы. Эти одно или 2 значения покрывают большую часть общей вариации выборки. Их называют главными компонентами выборки. Умножая матрицу Х справа на транспонированные вектора главных компонент получают преобразованную выборку элементы которой не коррелируют друг с другом. Таким образом, все объекты выборки представлены в виде одной или двух главных компонент, которые слабо взаимодействуют друг с другом. Сами объекты в структуре главных компонент сильно связаны их элементами. Дальнейшие исследования можно проводить с главными компонентами, сокращая размерность исследований. Главные компоненты рекомендуется использовать для оценок вместо матрицы Х. Современные статистические системы позволяют легко вычислять главные компоненты, не прибегая к сложным вычислениям линейной алгебры.