2015-05-10
2015-05-10 595
595Согласно методу пользователь заранее задает число n кластеров, на которые нужно разбить наблюдения и первые n наблюдений становятся центрами классификации. Для ех последующих наблюдений рассчитываются расстояния до центров классификации и каждое наблюдение относится к тому классу расстояние, до которого меньше. После этого рассчитывается новый центр классификации и т.д.
В окне кластерного анализа выберем K- means Clustering/
Пользователь, согласно методу, должен сам задать число классов
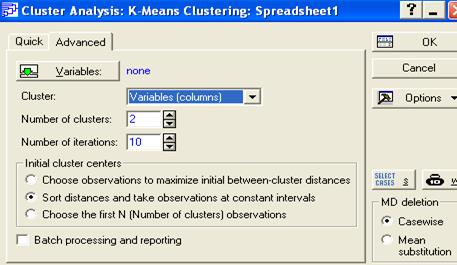
Зададим Number 2 кластера и число итераций.
Определим переменные, также как и в древовидной классификации.
Укажем тип классификации: по признакам Cases (Rоws) или по объектам Variable(columns).
Раздел MD deletion устанавливает режим работы с пропущенными данными.
Caserwise (пропустить), Mean substitution (заменить средними)
Установив данные щелкнем ОК
Следующее окно определяет протокол и параметры кластеризации
Окно состоит из двух частей: в верхней части, находится протокол исходных данных для анализа, в нижней протокол результатов.
Число переменных, число наблюдений, метод, тип матрицы расстояний, правило объединение кластеров.
В нижней части окна клавиши для протоколирования результатов.
Quick краткий, Advanced –полный.
Quick отображает протоколы: Summery средние в классах и евклидово расстояние, анализ дисперсий и график средних
В «шапке указывается, каким методом производилось объединение и по какой формуле рассчитывалось расстояние
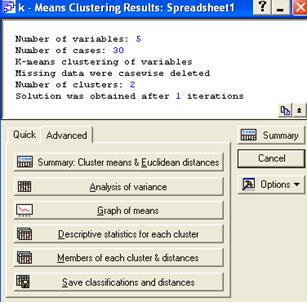
Расстояния между двумя классами

Распределение средних значений в классах
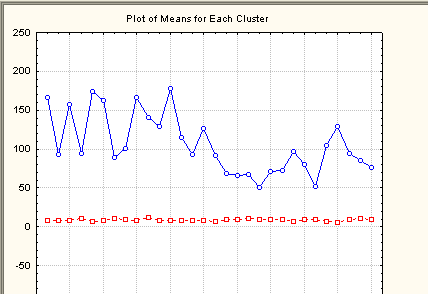
Число переменных и переменные в классах
Описательные статистики и т.д.