 2014-02-02
2014-02-02 2269
2269Групповое кодирование представляет собой обобщение метода подавления нулей. Групповое кодирование применяется для сжатия повторяющихся данных любого типа. На рисунке иллюстрируется применение данного метода к символьным данным. Здесь используются следующие обозначения:
· Sc — специальный символ, указывающий на то, что за ним следуют сжатые
данные;
· X — любой повторяющийся символ;
· Сс — счетчик символов, то есть количество повторений сжатого символа.
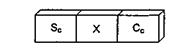
Примеры сжатия при групповом кодировании

Как и в методе подавления нулей, передатчик ищет последовательности повторяющихся символов. В данном случае он заменяет их трехсимвольным кодом. Код состоит из специального индикатора сжатия, за которым следуют сам повторяющийся символ и число его повторений. Таким образом, данный метод позволяет сократить место, занимаемое любой последовательностью из четырех и более одинаковых символов.
Эффективность метода группового кодирования зависит от того, насколько часто в исходных данных встречаются последовательности повторяющихся символов, и от средней длины таких серий. Стандартной мерой эффективности сжатия является коэффициент сжатия, представляющий собой отношение длины несжатых данных к длине сжатых данных (включая символы кодирования).
Групповое кодирование было одним из первых методов сжатия факсимильных сообщений, но теперь оно более не используется для этой цели. Однако этот метод следует изучить, так как он применяется в более сложных методах сжатия изображений. При использовании метода группового кодирования для изображений вместо отсканированной и оцифрованной линии передаются длины серий белых и черных элементов изображения. На рис. 20.2 показан пример применения метода группового кодирования к простому изображению размером 10x10 точек. Это может быть факсимильное изображение или отсканированное растровое компьютерное изображение. Изображение формата 10 х 10 легко преобразуется в 100-битовый код. В данном примере каждый пиксел представляется одним битом, обозначающим белый или черный цвет. Код длин серий состоит из длин чередующихся черных и белых последовательностей. Поскольку при таком кодировании изображения черный и белый цвета всегда чередуются, нет необходимости в использовании специального символа, указывающего цвет серии. Таким образом, кодированный поток данных представляет собой строку чисел, обозначающих длины чередующихся серий черных и белых точек. Обратите внимание на то, что в данном простом примере кодированные данные занимают больше места, чем исходные. Однако в случае применения данного метода к типичной странице текста этот метод будет сжимать данные. Тем не менее, это далеко не самый эффективный способ сжатия изображений.









