2014-02-02
2014-02-02 1617
1617Факсимильное сжатие
Методы сжатия данных очень важны для широкого применения цифровых факсимильных аппаратов. Для примера рассмотрим типичную страницу, отсканированную с разрешением в 200 пелов (белых или черных точек) на дюйм (что является приемлемой, но не высокой степенью разрешения). В результате такая страница содержит 3 740 000 бит (8,5 дюймов х 11 дюймов х 40 000 пелов на квадратный дюйм). При базовой скорости службы ISDN в 64 Кбит/с передача такой страницы займет около одной минуты. Обычно пользователи ожидают от систем работы со скоростью, близкой к скорости копирования, то есть несколько секунд на страницу. Для удовлетворения данного требования, если не прибегать к увеличению скорости передачи данных в линии, необходимо использовать метод сжатия данных.
Сектор ITU-T стандартизировал два метода сжатия данных без потерь для факсимильной связи: модифицированный код Хаффмана и модифицированный код READ (Relative Element Address Designate — относительное назначение адресов элементов). Модифицированный код Хаффмана используется по умолчанию в факсимильной аппаратуре группы З, в которой модифицированный код READ может применяться факультативно. В аппаратуре группы 4 применяется модифицированный код READ. Кратко эти два стандарта (группы 3 и 4) характеризуются следующим образом:
· Группа 3. Первый цифровой факсимильный стандарт. Эта система обеспечивает только кодирование черных и белых значений с плотностью сканирования в 200 точек на дюйм по горизонтали и от 100 до 200 по вертикали. В аппаратуре группы 3 используются цифровая схема кодирования, а также средства уменьшения избыточной информации в сигнале документа перед модуляцией. Предполагается, что передача сигнала осуществляется через модем по аналоговой телефонной линии. Передача данных ускоряется в три и более раз по сравнению с группой 2.
· Группа 4. Также представляет собой черно-белый цифровой факсимильный стандарт. Эта группа предназначена для использования в цифровых сетях со скоростями до 64 Кбит/с при условии безошибочного приема. Стандартизированы разрешения от 200 до 400 точек на дюйм. Как и в группе 3, для снижения количества передаваемых битов применяются методы сжатия. В аппаратуре группы 4 время передачи одной страницы сокращено до нескольких секунд по сравнению с несколькими минутами в предыдущих стандартах.
В типичном документе черные и белые области имеют тенденцию к объединению. Если рассматривать документ как последовательность линий и обратить внимание на расположение участков белого и черного в линии, можно обнаружить длинные серии белых и черных точек. Благодаря этому свойству можно предположить, что сжатие на основе метода группового кодирования даст хороший результат. Состоящие из двух значений входные данные преобразуются в длины серий, которые затем кодируются для передачи. Кроме того, поскольку в общем случае длинные серии черных или белых точек менее вероятны, чем короткие, можно воспользоваться преимуществом кодирования последовательностей переменной длины. Для кодирования факсимильных документов может применяться код Хаффмана, описанный ранее. Этот метод можно применить к изображению построчно, кодируя последовательности черных и белых точек. Например, предположим, что при сканировании отдельной строки получается следующая последовательность черных и белых точек: W7, В7, W4, В8, W4, В7, W10 (здесь W означает белый, а В — черный). Если рассматривать каждый из этих элементов как символ алфавита источника, тогда для кодирования этих данных может быть использован метод кодирования Хаффмана. Однако поскольку стандарт ITU-T требует по меньшей мере 1728 точек на линию, количество различных кодов, а следовательно, и средняя длина кода будет очень большой. Альтернативой является модифицированный метод кодирования Хаффмана. В этом методе длина серии N рассматривается как сумма двух слагаемых:
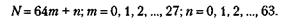
То есть длина каждой серии черных или белых точек считается величиной, кратной 64 с остатком.
Теперь каждая длина серии может быть представлена двумя значениями, одним для т и другим для n, и эти значения могут кодироваться при помощи метода Хаффмана. Например, строка из 200 черных точек подряд может быть выражена как 64*3 + 8. Для этого сектором ITU-T были определены восемь образцов документов и рассчитаны вероятности нахождения в документах серий различных длин. Поскольку для серий из черных и белых точек эти вероятности различаются, были сосчитаны два множества вероятностей. Длина серии делится на 64, после чего частное и остаток от деления кодируются двумя кодовыми словами. Если длина серии меньше 64 (частное от деления равно нулю), то такая длина серии кодируется только кодовым словом остатка. Серии длиной более 64 точек кодируются двумя кодами: кодом остатка (n) и кодом кратности (т). Имеется еще несколько деталей, касающихся этого кода. Каждая строка заканчивается уникальным кодовым словом EOL (End Of Line — конец строки). Это кодовое слово, никогда не встречающееся в строках данных, обеспечивает восстановление синхронизации в случае ошибок. Внутри строки должны чередоваться кодовые слова для белых и черных серий. Обратите внимание на то, что для белых и черных серий используются различные кодовые слова. Это обеспечивает дополнительную защиту от ошибок. Наконец, по соглашению каждая строка начинается с белой серии. Если первая точка в линии черная, то используется белая серия нулевой длины.