 2014-02-03
2014-02-03 2662
2662Для пояснения идеи метода отбраковки будем использовать тот же пример, что и при рассмотрении метода неравномерной рулетки. Для того чтобы обеспечит согласование ссылок в формулах, повторим таблицу исходных данных из предыдущего параграфа (рис. 4.8).
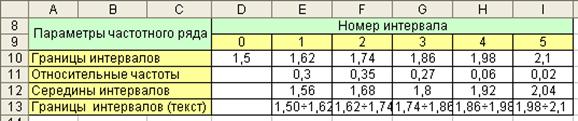
Рис. 4.8. Исходные данные гипотетического примера
Первый шаг. Для моделирования данных потребуется два случайных признака (рис. 4.9). Таблица данных содержит 150 строк.
Второй шаг. Впишем гистограмму моделируемых данных в прямоугольник (рис. 4.10). По оси X расположим моделируемый признак. Из таблицы исходных данных следует, что диапазон значений моделируемого признака (a=1,5;b=2,1). Эти параметры определяют одну сторону прямоугольника. По оси Y будем откладывать частоты по интервалам. Максимальная частота определит другую сторону прямоугольника (c=0,35).
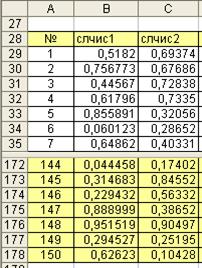
Рис. 4.9. Таблица данных (две последовательности случайных чисел)
Преобразуем две последовательности случайных в две новых последовательности чисел X и Y так, чтобы точки, определяемые новыми признаками попадали в прямоугольник, описывающий гистограмму (рис. 4.11).
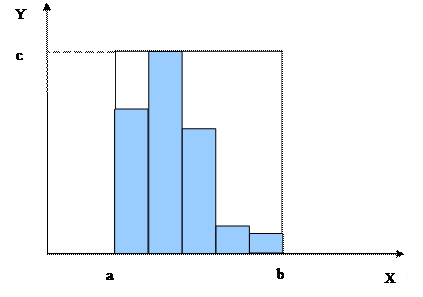
Рис.4.10. Прямоугольник, описывающий гистограмму моделируемой случайной величины
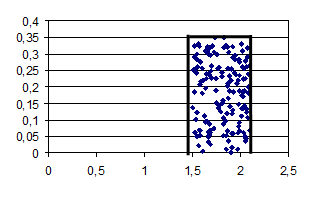
Рис. 4.11. Диаграмма рассеивания случайных признаков X и Y
Преобразование признаков производим по известным формулам:
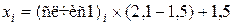 (4.1)
(4.1)
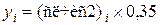 (4.2)
(4.2)
Преобразованные данные разместим в столбцах X и Y таблицы данных (рис. 4.12).
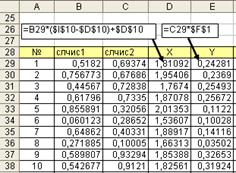
Рис. 4.12. Расчет значений в столбцах X и Y
Третий шаг. Рассмотрим точки, построенные по столбцам X и Y на фоне гистограммы моделируемого признака(4.13).
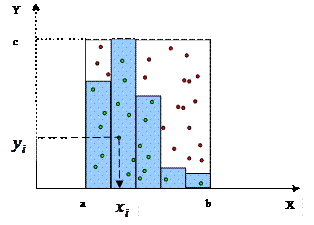
Рис. 4.13. Диаграмма рассеивания случайных признаков X и Y на фоне гистограммы моделируемого признака
Выполним операцию отбраковки, которая состоит в том, что точки лежащие вне поля гистограммы, отбрасываются и в выборку включается координаты X точек, попадающие в поле гистограммы. Сформируем новый признак Z, который будет содержать для принятых точек значения моделируемой выборки, а для отброшенных точек значение -1. Расчетные формулы приведены на рис. 4.14.
Четвертый шаг. На этом шаге определяются номера интервалов для точек, включенных в модельный ряд. Результаты расчетов разместим в столбце R. Эти данные необходимы нам для расчета частотного ряда по модельным данным. Для отбракованных точек значение определим как -1. В принципе, отбракованные точки можно отбросить из таблицы данных с помощью автофильтра, а затем произвести перенумерацию строк таблицы данных. Заметим, что результирующая модельная выборка будет содержать меньшее количество точек чем исходные последовательности случайных чисел. В нашем случае из 150 точек отобрано всего 79 точек. То есть мы заранее не можем точно знать, сколько точек получим в моделируемом ряду.
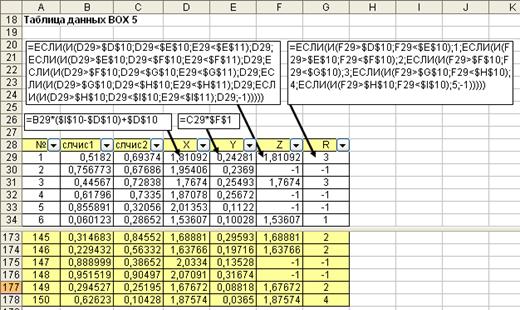
Рис. 4.14. Расчет столбцов Z и R таблицы данных
По модельным данным рассчитаем частотный ряд (рис. 4.15), построим гистограмму (4.16) и сравним с гистограммой заданной в исходных данных задачи. Полученные результаты показывают сходство с моделируемым частотным рядом.
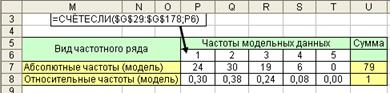
Рис. 4.15. Частотный ряд модельных данных
Полученный метод применим не только к исходным данным заданным гистограммой, но и к любой эмпирической функции заданной аналитической формулой (рис. 1.17).
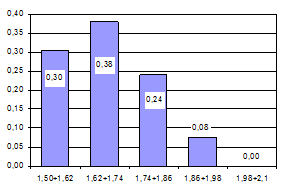
Рис. 4.16. Гистограмма модельных данных
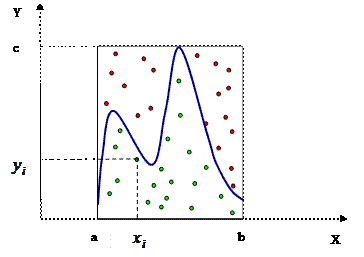
Рис. 4.17. Моделирование непрерывной функции плотности распределения








