 2014-02-12
2014-02-12 1898
1898Аналогично топологии N+ 1, топология NxN рассчитана на создание кластеров из 2, 3 и 4 узлов, но в отличие от первой обладает большей гибкостью и масштабируемостью.
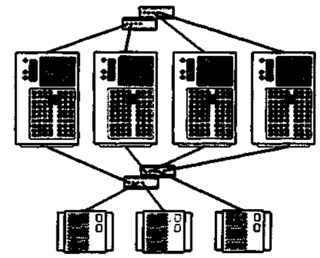
Только в этой топологии все узлы кластера имеют доступ ко всем дисковым массивам, которые, в свою очередь, строятся по схеме RAID 1 (с дублированием). Масштабируемость проявляется в простоте добавления к кластеру дополнительных узлов и дисковых массивов без изменения соединений в существующей системе.
Топология позволяет организовать каскадную систему отказоустойчивости, при которой обработка переносится с неисправного узла на резервный, а в случае его выхода из строя — на следующий резервный узел и т. д. Кластеры с топологией N x N обеспечивают поддержку приложения Oracle Parallel Server, требующего соединения всех узлов со всеми системами хранения информации. В целом топология характеризуется лучшей отказоустойчивостью и гибкостью по сравнению с другими решениями.
Топология с полностью раздельным доступом
В топологии с полностью раздельным доступом каждый дисковый массив соединяется только с одним узлом кластера.
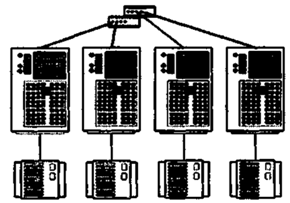
Топология рекомендуется только для тех приложений, для которых характерна архитектура полностью раздельного доступа, например для уже упоминавшейся СУБД Informix XPS.
Кластер Beowulf
Первым в мире кластером, по-видимому, является кластер, созданный под руководством Томаса Стерлинга и Дона Бекера в научно-космическом центре NASA – Goddard Space Flight Center – летом 1994 года. Названный в честь героя скандинавской саги, обладавшего, по преданию, силой тридцати человек, кластер состоял из 16 компьютеров на базе процессоров 486DX4 с тактовой частотой 100 MHz. Каждый узел имел 16 Mb оперативной памяти. Связь узлов обеспечивалась тремя параллельно работавшими 10 Mbit/s сетевыми адаптерами. Кластер функционировал под управлением операционной системы Linux, использовал GNU-компилятор и поддерживал параллельные программы на основе MPI. Процессоры узлов кластера были слишком быстрыми по сравнению с пропускной способностью обычной сети Ethernet, поэтому для балансировки системы Дон Бекер переписал драйверы Ethernet под Linux для создания дублированных каналов и распределения сетевого трафика.
В настоящее время под кластером типа Beowulf понимается система, которая состоит из одного серверного узла и одного или более клиентских узлов, соединенных при помощи Ethernet или некоторой другой сети. Это система, построенная из готовых серийно выпускающихся промышленных компонентов, на которых может работать ОС Linux, стандартных адаптеров Ethernet и коммутаторов. Она не содержит специфических аппаратных компонентов и легко воспроизводима. Серверный узел управляет всем кластером и является файл-сервером для клиентских узлов. Он также является консолью кластера и шлюзом во внешнюю сеть. Большие системы Beowulf могут иметь более одного серверного узла, а также, возможно, специализированные узлы, например консоли или станции мониторинга. В большинстве случаев клиентские узлы в Beowulf пассивны. Они конфигурируются и управляются серверными узлами и выполняют только то, что предписано серверным узлом.
Кластер AC3 Velocity Cluster
Кластер AC3 Velocity Cluster, установленный в Корнельском университете (США) стал результатом совместной деятельности университета и консорциума AC3 (Advanced Cluster Computing Consortium), образованного компаниями Dell, Intel, Microsoft, Giganet и еще 15 производителями ПО с целью интеграции различных технологий для создания кластерных архитектур для учебных и государственных учреждений.
Состав кластера:
· 64 четырехпроцессорных сервера Dell PowerEdge 6350 на базе Intel Pentium III Xeon 500 MHz, 4 GB RAM, 54 GB HDD, 100 Mbit Ethernet card;
· 1 восьмипроцессорный сервер Dell PowerEdge 6350 на базе Intel Pentium III Xeon 550 MHz, 8 GB RAM, 36 GB HDD, 100 Mbit Ethernet card.
Четырехпроцессорные серверы смонтированы по восемь штук на стойку и работают под управлением ОС Microsoft Windows NT 4.0 Server Enterprise Edition. Между серверами установлено соединение на скорости 100 Мбайт/c через Cluster Switch компании Giganet.
Задания в кластере управляются с помощью Cluster ConNTroller, созданного в Корнельском университете. Пиковая производительность AC3 Velocity составляет 122 GFlops при стоимости в 4 – 5 раз меньше, чем у суперкомпьютеров с аналогичными показателями.
На момент ввода в строй (лето 2000 года) кластер с показателем производительности на тесте LINPACK в 47 GFlops занимал 381-ю строку списка Top 500.
Кластер NCSA NT Supercluster
В 2000 году в Национальном центре суперкомпьютерных технологий (NCSA – National Center for Supercomputing Applications) на основе рабочих станций Hewlett-Packard Kayak XU PC workstation был собран еще один кластер, для которого в качестве операционной системы была выбрана ОС Microsoft Windows. Недолго думая, разработчики окрестили его NT Supercluster.
На момент ввода в строй кластер с показателем производительности на тесте LINPACK в 62 GFlops и пиковой производительностью в 140 GFlops занимал 207-ю строку списка Top 500.
Кластер построен из 38 двупроцессорных серверов на базе Intel Pentium III Xeon 550 MHz, 1 Gb RAM, 7.5 Gb HDD, 100 Mbit Ethernet card.
Связь между узлами основана на сети Myrinet.
Программное обеспечение кластера:
· операционная система – Microsoft Windows NT 4.0;
· компиляторы – Fortran77, C/C++;
· уровень передачи сообщений основан на HPVM.
Кластер Thunder
Аппаратная конфигурация кластера Thunder:
· 1024 сервера, по 4 процессора Intel Itanium 1.4 GHz в каждом;
· 8 Gb оперативной памяти на узел;
· общая емкость дисковой системы 150 Tb.
· операционная система CHAOS 2.0;
· среда параллельного программирования MPICH2;
· отладчик параллельных программ TotalView;
· Intel и GNU Fortran, C/C++ компиляторы.
На момент установки – лето 2004 года – кластер Thunder занимал 2-ю строку с пиковой производительностью 22938 GFlops и максимально показанной на тесте LINPACK 19940 Gflops.
Системы с массовым параллелизмом (MPP-системы)
Основным признаком, по которому вычислительную систему относят к архитектуре с массовой параллельной обработкой (МРР, Massively Parallel Processing), служит количество процессоровn. Строгой границы не существует, но обычно при n >=128 считается, что это уже МРР, а приn<=32 — еще нет. Обобщенная структура МРР-системы показана ниже.
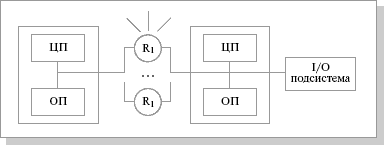
Схематический вид архитектуры MPP-системы
MPP – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры (роутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры. Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
Используются два варианта работы операционной системы (ОС) на машинах MPP-архитектуры. В одном полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно.
Главные особенности, по которым вычислительную систему причисляют к классу МРР, можно сформулировать следующим образом:
· стандартные микропроцессоры;
· физически распределенная память;
· сеть соединений с высокой пропускной способностью и малыми задержками;
· хорошая масштабируемость (до тысяч процессоров);
· асинхронная MIMD-система с пересылкой сообщений;
· программа представляет собой множество процессов, имеющих отдельные адресные пространства.
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (TOP 500).
Недостатки:
· отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
· каждый процессор может использовать только ограниченный объем локального банка памяти;
· вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec.
Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров.
При работе с MPP-системами используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (MPI, PVM, BSPlib).
Основные причины появления систем с массовой параллельной обработкой — это, во-первых, необходимость построения ВС с гигантской производительностью и, во-вторых, стремление раздвинуть границы производства ВС в большом диапазоне, как производительности, так и стоимости. Для МРР-системы, в которой количество процессоров может меняться в широких пределах, всегда реально подобрать конфигурацию с заранее заданной вычислительной мощностью и финансовыми вложениями.
Если говорить о МРР как о представителе класса MIMD с распределенной памятью и отвлечься от организации ввода/вывода, то эта архитектура является естественным расширением кластерной на большое число узлов. Отсюда для МРР-систем характерны все преимущества и недостатки кластеров, причем в связи с повышенным числом процессорных узлов как плюсы, так и минусы становятся гораздо весомее.
Характерная черта МРР-систем – наличие единственного управляющего устройства (процессора), распределяющего задания между множеством подчиненных ему устройств, чаще всего одинаковых (взаимозаменяемых), принадлежащих одному или нескольким классам. Схема взаимодействия в общих чертах довольно проста:
· центральное управляющее устройство формирует очередь заданий, каждому из которых назначается некоторый уровень приоритета;
· по мере освобождения подчиненных устройств им передаются задания из очереди;
· подчиненные устройства оповещают центральный процессор о ходе выполнения задания, в частности о завершении выполнения или о потребности в дополнительных ресурсах;
· у центрального устройства имеются средства для контроля работы подчиненных процессоров, в том числе для обнаружения нештатных ситуаций, прерывания выполнения задания в случае появления более приоритетной задачи и т. п.
В некотором приближении имеет смысл считать, что на центральном процессоре выполняется ядро операционной системы (планировщик заданий), а на подчиненных ему — приложения. Подчиненность между процессорами может быть реализована как на аппаратном, так и на программном уровне.
Вовсе не обязательно, чтобы МРР-система имела распределенную оперативную память, когда каждый процессорный узел владеет собственной локальной памятью. Так, например, системы SPP1000/XA и SPP1200/XA являют собой пример ВС с массовым параллелизмом, память которых физически распределена между узлами, но логически она общая для всей вычислительной системы. Тем не менее большинство МРР-систем имеют как логически, так и физически распределенную память.
Проблемы MPP-систем:
· Приращение производительности с ростом числа процессоров обычно вообще довольно быстро убывает (по закону Амдала).
· Достаточно трудно найти задачи, которые сумели бы эффективно загрузить множество процессорных узлов. Проблема переносимости программ между системами с различной архитектурой.
· Эффективность распараллеливания во многих случаях сильно зависит от деталей архитектуры МРР-системы, например топологии соединения процессорных узлов.
Самой эффективной была бы топология, в которой любой узел мог бы напрямую связаться с любым другим узлом, но в ВС на основе МРР это технически трудно реализуемо. Как правило, процессорные узлы в современных МРР-компьютерах образуют или двухмерную решетку (например, в SNI/Pyramid RM1000) или гиперкуб (как в суперкомпьютерах nCube). Поскольку для синхронизации параллельно выполняющихся процессов необходим обмен сообщениями, которые должны доходить из любого узла системы в любой другой узел, важной характеристикой является диаметр системы D. В случае двухмерной решетки D - sqrt(n), в случае гиперкуба D - ln(n). Таким образом, при увеличении числа узлов более выгодна архитектура гиперкуба. Время передачи информации от узла к узлу зависит от стартовой задержки и скорости передачи. В любом случае, за время передачи процессорные узлы успевают выполнить много команд, и это соотношение быстродействия процессорных узлов и передающей системы, вероятно, будет сохраняться — прогресс в производительности процессоров гораздо весомее, чем в пропускной способности каналов связи. Поэтому инфраструктура каналов связи в МРР-системах является объектом наиболее пристального внимания разработчиков. Слабым местом МРР было и есть центральное управляющее устройство (ЦУУ) - при выходе его из строя вся система оказывается неработоспособной. Повышение надежности ЦУУ лежит на путях упрощения аппаратуры ЦУУ и/или ее дублирования. Несмотря на все сложности, сфера применения ВС с массовым параллелизмом постоянно расширяется. Различные системы этого класса эксплуатируются во многих ведущих суперкомпьютерных центрах мира. Следует особенно отметить компьютеры Cray T3D и Cray T3E, которые иллюстрируют тот факт, что мировой лидер производства векторных суперЭВМ, компания Cray Research, уже не ори-ентируется исключительно на векторные системы. Наконец, нельзя не вспомнить, что суперкомпьютерный проект министерства энергетики США основан на МРР-системе на базе Pentium.
CRAY T3D
 Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами.
Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами.
CRAY T3D подключается к хост-компьютеру (главному или ведущему), роль которого, в частности, может исполнять CRAY Y-MP C90. Вся предварительная обработка и подготовка программ, выполняемых на CRAY T3D, проходит на хосте (например, компиляция). Связь хост-машины и T3D идет через высокоскоростной канал передачи данных с производительностью 200 Mбайт/с.
Массивно-параллельный компьютер CRAY T3D работает на тактовой частоте 150MHz и имеет в своем составе три основных компонента: сеть межпроцессорного взаимодействия (или по-другому коммуникационную сеть), вычислительные узлы и узлы ввода/вывода.

