 2015-04-12
2015-04-12 513
513Основные понятия математической статистики
Математическая статистика занимается установлением закономерностей массовых случайных явления, на основе обработки статистических данных, полученных в результате наблюдений.
Основные задачи математической статистики:
- определение способов сбора и группировки статистических данных;
- разработка методов анализа полученных данных
Наиболее часто оцениваются
- вероятности события;
- неизвестная функция распределения;
- параметры известного (заданного) распределения,.;
- возможность реализации (выполнения) гипотез (предположений).
Для решения этих задач необходимо выбрать из большой совокупности однородных объектов ограниченное количество объектов, по результатам изучения которых можно сделать прогноз относительно исследуемого признака этих объектов.
Генеральная совокупность – все множество имеющихся объектов.
Выборка – набор объектов, случайно отобранных из генеральной совокупности.
Объем генеральной совокупности N и объем выборки n – число объектов в рассматриваемой совокупности.
Виды выборки:
повторная – каждый отобранный объект перед выбором следующего возвращается в генеральную совокупность;
бесповторная – отобранный объект в генеральную совокупность не возвращается.
репрезентативная (представительная) выборка - выборка, обладающая всеми свойствами генеральной совокупности с точки зрения задачи исследования.
Первичная обработка результатов
Пусть случайная величина Х принимает в выборке значение
х1 п1 раз, х2 – п2 раз, …, хк – пк раз, причем 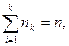 где п – объем выборки.
где п – объем выборки.
Называют
х1, х2,…, хк - варианты;
п1, п2,…, пк – частоты;
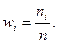 - относительные частоты
- относительные частоты
Статистический ряд:
| xi | x 1 | x 2 | … | xk |
| ni | n 1 | n 2 | … | nk |
| wi | w 1 | w 2 | … | wk |
Пример.
При проведении 20 серий из 10 бросков игральной кости число выпадений шести очков оказалось равным 1,1,4,0,1,2,1,2,2,0,5,3,3,1,0,2,2,3,4,1.Составим вариационный ряд: 0,1,2,3,4,5. Статистический ряд для абсолютных и относительных частот имеет вид:
| xi | ||||||
| ni | ||||||
| wi | 0,15 | 0,3 | 0,25 | 0,15 | 0,1 | 0,05 |
В случае исследования непрерывной случайной величины целесообразно использовать группированную выборку. Для ее получения интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько равных частичных интервалов длиной h, а затем находят для каждого частичного интервала ni – сумму частот вариант, попавших в i -й интервал.
Вид группированного статистического ряда:
| Номера интервалов | … | k | ||
| Границы интервалов | (a, a + h) | (a + h, a + 2 h) | … | (b – h, b) |
| Сумма частот вариант, попав- ших в интервал | n 1 | n 2 | … | nk |
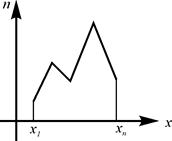 Полигон частот - ломаная, отрезки которой соединяют точки с координатами (x 1, n 1), (x 2, n 2),…, (xk, nk), где xi откладываются на оси абсцисс, а ni – на оси ординат. Если на оси ординат откладывать не абсолютные (ni), а относительные (wi) частоты, то получим полигон относительных частот.
Полигон частот - ломаная, отрезки которой соединяют точки с координатами (x 1, n 1), (x 2, n 2),…, (xk, nk), где xi откладываются на оси абсцисс, а ni – на оси ординат. Если на оси ординат откладывать не абсолютные (ni), а относительные (wi) частоты, то получим полигон относительных частот.
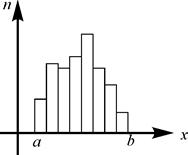 Для непрерывного признака графической иллюстрацией служит гистограмма, то есть ступенчатая фигура, состоящая из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высотами – отрезки длиной ni /h (гистограмма частот) или wi /h (гистограмма относительных частот). В первом случае площадь гистограммы равна объему выборки, во втором – единице
Для непрерывного признака графической иллюстрацией служит гистограмма, то есть ступенчатая фигура, состоящая из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высотами – отрезки длиной ni /h (гистограмма частот) или wi /h (гистограмма относительных частот). В первом случае площадь гистограммы равна объему выборки, во втором – единице
По аналогии с функцией распределения случайной величины можно задать некоторую функцию, относительную частоту события X < x.
Выборочной (эмпирической) функцией распределения называют функцию F* (x), определяющую для каждого значения х относительную частоту события X < x. Таким образом,
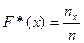 ,
,
где пх – число вариант, меньших х, п – объем выборки.
Из определения эмпирической функции распределения видно, что ее свойства совпадают со свойствами F (x), а именно:
1) 0 ≤ F* (x) ≤ 1.
2) F* (x) – неубывающая функция.
3) Если х 1 – наименьшая варианта, то F* (x) = 0 при х ≤ х 1; если хк – наибольшая варианта, то F* (x) = 1 при х > хк.








