2015-05-22
2015-05-22 473
473Первый метод ранжирования основан на использовании упорядочивания по значимости атрибутов, проведенного с помощью экспертов. Возможный способ проведения такой экспертизы будет описан ниже.
Предположим, что такая экспертиза проведена, и порядок значимости атрибутов определен. Без ограничения общности можно считать, что порядок значимости совпадает с исходной последовательностью номеров атрибутов m € М. Этого всегда можно добиться соответствующей перенумерацией атрибутов. Последнее предположение означает, что из двух объектов недвижимости лучшей считается тот объект, информационный вектор которой содержит компонент с наименьшим номером, являющимся больше, чем соответствующий компонент информационного вектора другого объекта недвижимости.
Далее процедура ранжирования информационных векторов xi = (xi1,...,xi|M|) i € Î сводится к последовательности следующих шагов.
Рассмотрим вектора xi, i € Î по первой, самой важной компоненте. Если в ряду рассмотренных первых компонентов xi1, i € Î нет одинаковых значений, то на этом процедура ранжирования информационных векторов и заканчивается. Информационные вектора ранжируются в порядке убывания значений первых компонентов, т.е. на первом месте стоит объект недвижимости, которому соответствует информационный вектор с максимальной первой компонентой, на втором месте — вектор со вторым численным значением первой компоненты и т.д., вплоть до последнего вектора из множества Î.
Рассмотрим теперь более общий и более реальный случай, когда в рассматриваемом ряду первых компонентов информационных векторов встречаются одинаковые значения. Тогда процедура ранжирования проводится с привлечением значений других атрибутов и сводится к следующей последовательности действий.
В зависимости от значений рассмотренного ряда первых компонентов информационных векторов в каждом шаге применяется один из двух алгоритмов:
1. Если | R1 | значений рассмотренного ряда первых компонентов хi1, i € R1 € Î различны, a | Q1 | значений этих же компонентов одинаковы:
xi = q1, i € Q1 € Î и
r1 > q1 > g1,
где 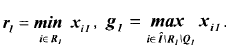
Тогда первые | R1 |, упорядоченные по первой компоненте вектора, являются ранжированными. Другие | Q1 | векторов упорядочиваются по второй компоненте (по второму по важности показателю).
2. Если | Q1 | значений рассмотренного ряда первых компонентов одинаковы:
xi1 = q1, i € Q1 € Î и
q1 > g1,
где 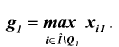
Тогда | Q1 | векторов упорядочиваются по второй компоненте. Если среди | Q1 | значений вторых компонентов нет одинаковых, то и эти | Q1 | вектора упорядочим в порядке убывания значений вторых компонентов. Если же среди | Q1 | значений вторых компонентов также встречаются одинаковые, то упорядочим их по третьей компоненте и т.д.
Затем, после упорядочивания | R1 | + | Q1 | векторов по первому алгоритму или | Q1 | векторов по второму алгоритму, упорядочивание остальных информационных векторов проводим по той же схеме. Если среди оставшихся векторов первые компоненты различные, то процедура ранжирования считается законченной — эти информационные вектора ранжируются в порядке убывания значений первых компонентов. В противном случае поступаем выше описанным способом: среди оставшегося множества информационных векторов выделяем следующие | R2 | — различных первых компонентов и | Q2 | — одинаковых или только | Q2 | — одинаковых первых компонентов и повторяем всю процедуру ранжирования для этих множеств.
Описанному выше алгоритму ранжирования информационных векторов эквивалентна следующая пошаговая процедура.
Шаг 0. Положим S = Î, L = Θ.
Шаг 1. Положим m = 1, К = S.
Шаг 2. Определяем номера информационных векторов, составляющие множество J с максимальной n -й компонентой:
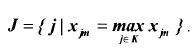
Шаг 3. Если | J | = 1 или m = | М |, то переходим к шагу 5.
Шаг 4. В противном случае, положим n = n + 1, К = J и переходим к шагу 2, т.е. теперь будем рассматривать следующий по важности показатель.
Шаг 5. Положим S = S \ J, L = L U J.
Шаг 6. Если S = Θ, то переходим к шагу 7, в противном случае, переходим к шагу 1.
Шаг 7. Это конец процедуры ранжирования (весь список векторов исчерпан).
Ранжирование информационных векторов определяется множеством (списком) L.