 2015-06-05
2015-06-05 1514
1514В самом несбалансированном варианте каждое разделение даёт два подмассива размерами 1 и 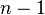 , то есть при каждом рекурсивном вызове больший массив будет на 1 короче, чем в предыдущий раз. Такое может произойти, если в качестве опорного на каждом этапе будет выбран элемент либо наименьший, либо наибольший из всех обрабатываемых. При простейшем выборе опорного элемента — первого или последнего в массиве, — такой эффект даст уже отсортированный (в прямом или обратном порядке) массив, для среднего или любого другого фиксированного элемента «массив худшего случая» также может быть специально подобран. В этом случае потребуется операций разделения, а общее время работы составит
, то есть при каждом рекурсивном вызове больший массив будет на 1 короче, чем в предыдущий раз. Такое может произойти, если в качестве опорного на каждом этапе будет выбран элемент либо наименьший, либо наибольший из всех обрабатываемых. При простейшем выборе опорного элемента — первого или последнего в массиве, — такой эффект даст уже отсортированный (в прямом или обратном порядке) массив, для среднего или любого другого фиксированного элемента «массив худшего случая» также может быть специально подобран. В этом случае потребуется операций разделения, а общее время работы составит 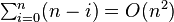 операций, то есть сортировка будет выполняться за квадратичное время. Но количество обменов и, соответственно, время работы — это не самый большой его недостаток. Хуже то, что в таком случае глубина рекурсии при выполнении алгоритма достигнет n, что будет означать n-кратное сохранение адреса возврата и локальных переменных процедуры разделения массивов. Для больших значений n худший случай может привести к исчерпанию памяти (переполнению стека) во время работы программы.
операций, то есть сортировка будет выполняться за квадратичное время. Но количество обменов и, соответственно, время работы — это не самый большой его недостаток. Хуже то, что в таком случае глубина рекурсии при выполнении алгоритма достигнет n, что будет означать n-кратное сохранение адреса возврата и локальных переменных процедуры разделения массивов. Для больших значений n худший случай может привести к исчерпанию памяти (переполнению стека) во время работы программы.
Достоинства и недостатки[править | править исходный текст]
Достоинства:
· Один из самых быстродействующих (на практике) из алгоритмов внутренней сортировки общего назначения.
· Прост в реализации.
· Требует лишь 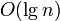 дополнительной памяти для своей работы. (Не улучшенный рекурсивный алгоритм в худшем случае
дополнительной памяти для своей работы. (Не улучшенный рекурсивный алгоритм в худшем случае 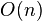 памяти)
памяти)
· Хорошо сочетается с механизмами кэширования и виртуальной памяти.
· Допускает естественное распараллеливание (сортировка выделенных подмассивов в параллельно выполняющихся подпроцессах).
· Допускает эффективную модификацию для сортировки по нескольким ключам (в частности — алгоритм Седжвика для сортировки строк): благодаря тому, что в процессе разделения автоматически выделяется отрезок элементов, равных опорному, этот отрезок можно сразу же сортировать по следующему ключу.
· Работает на связных списках и других структурах с последовательным доступом, допускающих эффективный проход как от начала к концу, так и от конца к началу.
Недостатки:
· Сильно деградирует по скорости (до 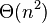 ) в худшем или близком к нему случае, что может случиться при неудачных входных данных.
) в худшем или близком к нему случае, что может случиться при неудачных входных данных.
· Прямая реализация в виде функции с двумя рекурсивными вызовами может привести к ошибке переполнения стека, так как в худшем случае ей может потребоваться сделать вложенных рекурсивных вызовов.
· Неустойчив.
Улучшения[править | править исходный текст]
Улучшения алгоритма направлены, в основном, на устранение или смягчение вышеупомянутых недостатков, вследствие чего все их можно разделить на две группы: придание алгоритму устойчивости и «защита от худшего случая» — устранение деградации производительности и переполнения стека вызовов из-за большой глубины рекурсии при неудачных входных данных.
Что касается первой проблемы, то она элементарно решается путём расширения ключа исходным индексом элемента в массиве. В случае равенства основных ключей сравнение производится по индексу, исключая, таким образом, возможность изменения взаимного положения равных элементов. Эта модификация не бесплатна — она требует дополнительно O(n) памяти и одного полного прохода по массиву для сохранения исходных индексов.
Вторая проблема, в свою очередь, решается по двум разным направлениям: снижение вероятности возникновения худшего случая путём специального выбора опорного элемента и применение различных технических приёмов, обеспечивающих устойчивую работу на неудачных входных данных. Для первого направления:
· Выбор среднего элемента. Устраняет деградацию для предварительно отсортированных данных, но оставляет возможность случайного появления или намеренного подбора «плохого» массива.
· Выбор медианы из трёх элементов: первого, среднего и последнего. Снижает вероятность возникновения худшего случая, по сравнению с выбором среднего элемента.
· Случайный выбор. Вероятность случайного возникновения худшего случая становится исчезающе малой, а намеренный подбор — практически неосуществимым. Ожидаемое время выполнения алгоритма сортировки составляет O(n lg n).
Недостаток всех усложнённых методов выбора опорного элемента — дополнительные накладные расходы; впрочем, они не так велики.
Во избежание отказа программы из-за большой глубины рекурсии могут применяться следующие методы:
· При достижении нежелательной глубины рекурсии переходить на сортировку другими методами, не требующими рекурсии. Примером такого подхода является алгоритм Introsort или некоторые реализации быстрой сортировки в библиотеке STL. Можно заметить, что алгоритм очень хорошо подходит для такого рода модификаций, так как на каждом этапе позволяет выделить непрерывный отрезок исходного массива, предназначенный для сортировки, и то, каким методом будет отсортирован этот отрезок, никак не влияет на обработку остальных частей массива.
· Модификация алгоритма, устраняющая одну ветвь рекурсии: вместо того, чтобы после разделения массива вызывать рекурсивно процедуру разделения для обоих найденных подмассивов, рекурсивный вызов делается только для меньшего подмассива, а больший обрабатывается в цикле в пределах этого же вызова процедуры. С точки зрения эффективности в среднем случае разницы практически нет: накладные расходы на дополнительный рекурсивный вызов и на организацию сравнения длин подмассивов и цикла — примерно одного порядка. Зато глубина рекурсии ни при каких обстоятельствах не превысит , а в худшем случае вырожденного разделения она вообще будет не более 2 — вся обработка пройдёт в цикле первого уровня рекурсии. Правда, применение этого метода не спасёт от катастрофического падения производительности, но переполнения стека не будет.
· Разбивать массив не на две, а на три части (см. Dual Pivot Quicksort).
Тема 8. Алгоритмы поиска и их классификация
Медленный алгоритм поиска. Быстрые алгоритмы поиска. Поиск в упорядоченном массиве. Алгоритм выборки. Библиотечные функции поиска.
Линейный, последовательный поиск — алгоритм нахождения заданного значения произвольной функции на некотором отрезке. Данный алгоритм является простейшим алгоритмом поиска и в отличие, например, от двоичного поиска, не накладывает никаких ограничений на функцию и имеет простейшую реализацию. Поиск значения функции осуществляется простым сравнением очередного рассматриваемого значения (как правило поиск происходит слева направо, то есть от меньших значений аргумента к большим) и, если значения совпадают (с той или иной точностью), то поиск считается завершённым.
Если отрезок имеет длину N, то найти решение с точностью до  можно за время
можно за время 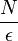 . Т.о. асимптотическая сложность алгоритма — . В связи с малой эффективностью по сравнению с другими алгоритмами линейный поиск обычно используют только если отрезок поиска содержит очень мало элементов, тем не менее линейный поиск не требует дополнительной памяти или обработки/анализа функции, так что может работать в потоковом режиме при непосредственном получении данных из любого источника. Так же, линейный поиск часто используется в виде линейных алгоритмов поиска максимума/минимума.
. Т.о. асимптотическая сложность алгоритма — . В связи с малой эффективностью по сравнению с другими алгоритмами линейный поиск обычно используют только если отрезок поиска содержит очень мало элементов, тем не менее линейный поиск не требует дополнительной памяти или обработки/анализа функции, так что может работать в потоковом режиме при непосредственном получении данных из любого источника. Так же, линейный поиск часто используется в виде линейных алгоритмов поиска максимума/минимума.
Двоичный (бинарный) поиск (также известен как метод деления пополам и дихотомия) — классический алгоритм поиска элемента в отсортированном массиве (векторе), использующий дробление массива на половины. Используется в информатике,вычислительной математике и математическом программировании.
Частным случаем двоичного поиска является метод бисекции, который применяется для поиска корней заданной непрерывной функции на заданном отрезке.
Дихотоми́я (греч. διχοτομία: δῐχῆ, «надвое» + τομή, «деление») — раздвоенность, последовательное деление на две части, не связанные между собой. Способ логического деления класса на подклассы, который состоит в том, что делимое понятие полностью делится на два взаимоисключающих понятия. Дихотомическое деление в математике,философии, логике и лингвистике является способом образования взаимоисключающих подразделов одного понятия или термина и служит для образования классификации элементов.
Объём понятия «человек» можно разделить на два взаимоисключающих класса: мужчины и не мужчины. Понятия «мужчины» и «не мужчины» являются противоречащими друг другу, поэтому их объёмы не пересекаются. От дихотомии следует отличать обычное деление, приводящее к тому же самому результату. Например, объём понятия «человек» можно разделить по признаку пола на мужчин и женщин. Но между понятиями мужчина и женщина нет логического противоречия, поэтому здесь нельзя говорить о дихотомическом делении.
Метод бисекции или метод деления отрезка пополам — простейший численный метод для решения нелинейных уравненийвида f (x)=0. Предполагается только непрерывность функции f (x). Поиск основывается на теореме о промежуточных значениях.
Метод золотого сечения — метод поиска экстремума действительной функции одной переменной на заданном отрезке. В основе метода лежит принцип деления отрезка в пропорциях золотого сечения. Является одним из простейших вычислительных методов решения задач оптимизации. Впервые представлен Джеком Кифером в 1953 году.
Поиск в неупорядоченных массивах
Поиск порядковых статистик
Бинарный поиск в упорядоченных массивах
Бинарный поиск по ответу
Поиск по групповому признаку








