 2015-06-05
2015-06-05 579
579Среднюю сложность при случайном распределении входных данных можно оценить лишь вероятностно.
Прежде всего необходимо заметить, что в действительности необязательно, чтобы опорный элемент всякий раз делил массив на две одинаковых части. Например, если на каждом этапе будет происходить разделение на массивы длиной 75 % и 25 % от исходного, глубина рекурсии будет равна 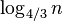 , а это по-прежнему даёт сложность
, а это по-прежнему даёт сложность 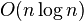 . Вообще, при любом фиксированном соотношении между левой и правой частями разделения сложность алгоритма будет той же, только с разными константами.
. Вообще, при любом фиксированном соотношении между левой и правой частями разделения сложность алгоритма будет той же, только с разными константами.
Будем считать «удачным» разделением такое, при котором опорный элемент окажется среди центральных 50 % элементов разделяемой части массива; ясно, вероятность удачи при случайном распределении элементов составляет 0,5. При удачном разделении размеры выделенных подмассивов составят не менее 25 % и не более 75 % от исходного. Поскольку каждый выделенный подмассив также будет иметь случайное распределение, все эти рассуждения применимы к любому этапу сортировки и любому исходному фрагменту массива.
Удачное разделение даёт глубину рекурсии не более . Поскольку вероятность удачи равна 0,5, для получения 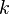 удачных разделений в среднем потребуется
удачных разделений в среднем потребуется 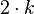 рекурсивных вызовов, чтобы опорный элемент k раз оказался среди центральных 50 % массива. Применяя эти соображения, можно заключить, что в среднем глубина рекурсии не превысит
рекурсивных вызовов, чтобы опорный элемент k раз оказался среди центральных 50 % массива. Применяя эти соображения, можно заключить, что в среднем глубина рекурсии не превысит 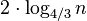 , что равно
, что равно 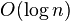 А поскольку на каждом уровне рекурсии по-прежнему выполняется не более
А поскольку на каждом уровне рекурсии по-прежнему выполняется не более 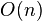 операций, средняя сложность составит .
операций, средняя сложность составит .








