 2015-06-05
2015-06-05 919
919Быстрая сортировка (англ. quicksort), часто называемая qsort по имени реализации в стандартной библиотеке языка Си — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром во время его работы в МГУ в 1960 году. Один из самых быстрых известных универсальных алгоритмов сортировки массивов (в среднем O(n log n) обменов при упорядочении n элементов); из-за наличия ряда недостатков на практике обычно используется с некоторыми доработками.
QuickSort является существенно улучшенным вариантом алгоритма сортировки с помощью прямого обмена (его варианты известны как «Пузырьковая сортировка» и «Шейкерная сортировка»), известного, в том числе, своей низкой эффективностью. Принципиальное отличие состоит в том, что в первую очередь производятся перестановки на наибольшем возможном расстоянии и после каждого прохода элементы делятся на две независимые группы. Любопытный факт: улучшение самого неэффективного прямого метода сортировки дало в результате один из наиболее эффективных улучшенных методов.
Общая идея алгоритма состоит в следующем:
· Выбрать из массива элемент, называемый опорным. Это может быть любой из элементов массива.
· Сравнить все остальные элементы с опорным и переставить их в массиве так, чтобы разбить массив на три непрерывных отрезка, следующие друг за другом — «меньшие опорного», «равные» и «большие».
· Для отрезков «меньших» и «больших» значений выполнить рекурсивно ту же последовательность операций, если длина отрезка больше единицы.
На практике массив обычно делят не на три, а на две части, например, «меньшие опорного» и «равные и большие». Такой подход в общем случае эффективнее, так как упрощает алгоритм разделения.
Хоар разработал этот метод применительно к машинному переводу; словарь хранился на магнитной ленте, и сортировка слов обрабатываемого текста позволяла получить их переводы за один прогон ленты, без перемотки её назад. Алгоритм был придуман Хоаром во время его пребывания в Советском Союзе, где он обучался в Московском университете компьютерному переводу и занимался разработкой русско-английского разговорника.
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
1. Выбираем в массиве некоторый элемент, который будем называть опорным элементом. С точки зрения корректности алгоритма выбор опорного элемента безразличен. С точки зрения повышения эффективности алгоритма выбираться должна медиана, но без дополнительных сведений о сортируемых данных её обычно невозможно получить. Известные стратегии: выбирать постоянно один и тот же элемент, например, средний или последний по положению; выбирать элемент со случайно выбранным индексом.
2. Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы со значением меньшим или равным опорному элементу, оказались слева от него, а все элементы, превышающие по значению опорный — справа от него. Обычный алгоритм операции:
1. Два индекса — l и r, приравниваются к минимальному и максимальному индексу разделяемого массива, соответственно.
2. Вычисляется индекс опорного элемента m.
3. Индекс l последовательно увеличивается до тех пор, пока l-й элемент не окажется больше либо равен опорному.
4. Индекс r последовательно уменьшается до тех пор, пока r-й элемент не окажется меньше либо равен опорному.
5. Если r = l — найдена середина массива — операция разделения закончена, оба индекса указывают на опорный элемент.
6. Если l < r — найденную пару элементов нужно обменять местами и продолжить операцию разделения с тех значений l и r, которые были достигнуты. Следует учесть, что если какая-либо граница (l или r) дошла до опорного элемента, то при обмене значение m изменяется на r-й или l-й элемент соответственно, изменяется именно индекс опорного элемента и алгоритм продолжает свое выполнение.
3. Рекурсивно упорядочиваем подмассивы, лежащие слева и справа от опорного элемента.
4. Базой рекурсии являются наборы, состоящие из одного или двух элементов. Первый возвращается в исходном виде, во втором, при необходимости, сортировка сводится к перестановке двух элементов. Все такие отрезки уже упорядочены в процессе разделения.
Поскольку в каждой итерации (на каждом следующем уровне рекурсии) длина обрабатываемого отрезка массива уменьшается, по меньшей мере, на единицу, терминальная ветвь рекурсии будет достигнута обязательно и обработка гарантированно завершится.
Ясно, что операция разделения массива на две части относительно опорного элемента занимает время 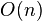 . Поскольку все операции разделения, проделываемые на одной глубине рекурсии, обрабатывают разные части исходного массива, размер которого постоянен, суммарно на каждом уровне рекурсии потребуется также операций. Следовательно, общая сложность алгоритма определяется лишь количеством разделений, то есть глубиной рекурсии. Глубина рекурсии, в свою очередь, зависит от сочетания входных данных и способа определения опорного элемента.
. Поскольку все операции разделения, проделываемые на одной глубине рекурсии, обрабатывают разные части исходного массива, размер которого постоянен, суммарно на каждом уровне рекурсии потребуется также операций. Следовательно, общая сложность алгоритма определяется лишь количеством разделений, то есть глубиной рекурсии. Глубина рекурсии, в свою очередь, зависит от сочетания входных данных и способа определения опорного элемента.








