2015-06-30
2015-06-30 507
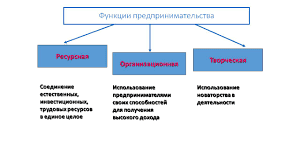
507При скалярной обработке данных (рис. 1) командное слово i считывается из памяти команд (MI) в регистр команд скалярного процессора. В адресном поле Аj командного слова содержится указание на данные j (адрес данных в памяти данных (MD)). Одновременно со считыванием данных j из MD, считываются данные k из регистра, заданного в поле R командного слова i. Над данными j и k в арифметико-логическом устройстве (АЛУ) выполняется операция, задаваемая полем «код операции» (КОП) командного слова. Результаты операции заносятся в регистр R.
Данные j на рис. 1 представляют собой единичные элементы обработки и размещены в памяти независимо друг от друга и поэтому называются скалярными. Команды, инициирующие операции над скалярными данными, называются скалярными командами. Процессор, выполняющий скалярные команды, называется скалярным процессором.

Рис. 1. Схема скалярной обработки
Основные принципы построения суперскалярных процессоров состоят в создании условий параллельного использования возможно большего числа функциональных узлов при сохранении традиционного способа написания последовательных программ. Причем распараллеливание команд программы осуществляется динамически в ходе непосредственного выполнения вычислений. Для того чтобы динамическое распараллеливание было эффективным, оно должно реализовываться за как можно меньший интервал времени, а, следовательно, аппаратными средствами и, возможно, в режиме совмещения с вычислениями. В число основных блоков суперскалярного процессора должны входить следующие: выборки команд и предсказания переходов, декодирования команд и анализа зависимостей между командами, переименования и диспетчеризации, файлы регистров и исполнительных устройств с плавающей и фиксированной точками, управления памятью, а также блок восстановления порядка выполненных команд. Таким образом, динамическое распараллеливание и параллельное исполнение команд поддерживаются следующими механизмами:
· многоуровневой (иерархической) памятью, включая несколько уровней кэш-памяти;
· раздельными кэш-памятями команд и данных;
· выборкой команд, обеспечивающей выборку на исполнение совокупности команд, принадлежащих «окну исполнения»;
· таблицей предсказания переходов;
· переименованием регистров;
· поддержкой внеочередного исполнения команд;
· преобразованием данных в форматах с фиксированной и плавающей запятой набором исполнительных функциональных устройств.
Основой динамического распараллеливания является преобразование статической структуры программы (последовательной программы так, как она была создана программистом) в динамическую структуру программы. Это осуществляется за счет того, что алгоритм функционирования суперскалярного процессора использует модель окна исполнения так, что при исполнении программы процессор как бы продвигает по статической структуре программы окно исполнения, длина которого задает количество команд программы, исследуемых на возможность одновременного исполнения. Команды, принадлежащие окну, могут исполняться параллельно, если между ними нет зависимости по управлению и по данным.
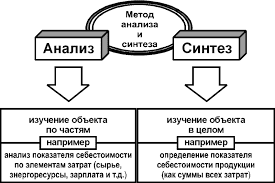
При выполнении расчетного задания используются следующие ограничения: из памяти команд одновременно выбирается сразу две команды (рис. 2) и внутри суперскалярного процессора с этой целью работает два конвейера команд.

Рис. 2. Схема суперскалярной обработки
Память данных остается общей для обоих конвейеров и доступ к ней является «узким местом» процессоров данного типа. Для снижения числа возникающих конфликтов при работе с исполнительными устройствами каждому конвейеру предоставляется своё независимое АЛУ, которое содержит сумматор, умножитель и делитель.
Рассмотрим пример выполнения оператора на суперскалярном процессоре в цикле, код которого на языке Фортран имеет следующий вид:
DO 10 I=1, N
10 S(i)= Z(i) / (X (i) – Q(i)) + P(i)*Y(i)/U(i) + (W(i)-V(i))*L(i).
Выполнение любой скалярной операции разбивается в конвейере команд на следующие стадии (см. рис. 3):
В – выборка команды из памяти команд MI;
D – дешифрация команды в устройстве управления CU;
A – преобразование виртуальных адресов в физические в устройстве подготовки физических адресов UA;
F – считывание данных из памяти данных MD (1 операнда); данная стадия может быть холостой, например, при исполнении команд обращения к памяти LD и STD;
E – исполнение операции, указанной в КОП.
Далее необходимо относительно равномерно распределить операции, исполняемые в цикле программы, по двум конвейерам команд (табл. 1).
Таблица 1
Распределение операций по конвейерам команд
| I конвейер (АЛУ 1) | II конвейер (АЛУ 2) | ||
| Номер операции | Операция | Номер операции | Операция |
| LD R1,Y | LD R3, X | ||
| MD R1,P | SD R3, Q | ||
| DD R1,U | LD R2, Z | ||
| LD R4,W | DD R2,R3 | ||
| SD R4,V | AD R2,R1 | ||
| MD R4,L | |||
| AD R2,R4 | |||
| STD S,R2 | |||
| BXLE |
Здесь: LD Rx, DATA – загрузка из MD данных DATA двойной длины в регистр Rx; AD Rx, DATA – сложение данных DATA двойной длины и содержимого регистра Rx с занесением результата операции в регистр Rx; SD Rx, DATA – вычитание данных DATA двойной длины из содержимого регистра Rx с занесением результата операции в регистр Rx; MD Rx, DATA – умножение данных DATA двойной длины на содержимое регистра Rx с занесением результата операции в регистр Rx; DD Rx, DATA – деление содержимого регистра Rx на данные DATA двойной длины с занесением результата операции в регистр Rx; STD S, Rx – занесение результата S из регистра Rx в память данных; BXLE – проверка условия окончания цикла (уменьшение счетчика циклов на 1 и проверка его содержимого на 0).
Во всех командах в качестве данных DATA может выступать также содержимое регистра Ry. Регистры Rx, Ry принадлежат общему файлу регистров (см. рис. 2).
Перед построением временной диаграммы занятости устройств и регистров суперскалярного процессора отметим следующее.
1. Выполнению N итераций цикла предшествует подготовительный этап (ПЭ), связанный с начальной установкой условий для управления циклом – числа итераций, значения индексов. Пусть длительность ПЭ равна двум машинным тактам (МТ).
2. После выполнения последней итерации цикла требуются завершающие действия по выходу из него, определяющие завершающий этап (ЗЭ). Пусть его длительность также равна 2 МТ.
3. В суперскалярный процессор введен узел предсказания переходов, благодаря которому каждую последующую итерацию можно будет начинать до завершения предыдущей (стадии B, D, A).
4. Будем считать, что стадии B, D, A, F требуют для своего исполнения 1 МТ, а длительность стадии E определяется типом операции: LD, STD, AD, SD – 1МТ, MD – 3 МТ, DD – 6 МТ.
5. Приоритет начала выполнения команд отдадим первому конвейеру.
Временная диаграмма занятости исполнительных устройств и регистров суперскалярного процессора изображена на рис. 3.
Здесь SUM, MUL, DIV соответственно сумматор, умножитель, делитель из состава АЛУ; R1-R4 – скалярные регистры, принадлежащие общему файлу регистров. Числа над стадиями команд означают номер операции из табл. 1, к которой они относятся.
При построении временной диаграммы следует уделять особое внимание тому, что все стадии выполнения всех операций (B, D, A, F, E) должны идти непосредственно друг за другом. Нельзя допускать такого, чтобы стадия E начиналась без прохождения стадии F (пусть даже холостой) или раньше нее. Связи между стадиями F и E для некоторых операций показаны стрелками на рис. 3. Необходимо также отслеживать, чтобы на начало стадии E все данные, необходимые для операции, уже были загружены в соответствующие регистры.
Рассчитаем время выполнения N итераций цикла на суперскалярном процессоре T с/скал.:
Tс/скал. = ТПЭ + TВ + N*Тц + ТЗЭ = 2 + 4 + N*18 + 2 = 8+18N (МТ).
Здесь: ТПЭ, ТЗЭ – время подготовительного и завершающего этапов соответственно; ТВ – время этапа втягивания в стационарный режим исполнения цикла; Тц – время выполнения всех операций одной итерации цикла в параллельном режиме на двух АЛУ.

Рис. 3. Временная диаграмма занятости исполнительных устройств и регистров суперскалярного процессора