 2015-07-14
2015-07-14 9212
9212А теперь рассмотрим, как с понятием вероятности связано вычисление информационных весов символов алфавита. Обсуждая алфавитный подход раньше, мы исходили из предположения равновероятности появление в любой позиции текста любого из символов используемого алфавита. На самом деле для естественных языков это не так. Легко доказать, что одни символы появляются в тексте чаще, а другие - реже. Частота появления символа – это отношение количества вхождений данного символа в текст к общему количеству символов в тексте. В таблице 1.1 приведены частотные характеристики букв латинского алфавита в английских текстах, а в таблице 1.2 – русских букв (кириллицы) в текстах на русском языке (символ «_» означает пробел). Эти данные получены путем усреднения результатов обработки большого числа текстов.
Таблица 1.1
| Буква | Частота | Буква | Частота | Буква | Частота | Буква | Частота |
| E | 0,130 | S | 0,061 | U | 0,024 | K | 0,004 |
| T | 0,105 | H | 0,052 | G | 0,020 | X | 0,0015 |
| A | 0,081 | D | 0,038 | Y | 0,019 | J | 0,0013 |
| O | 0,079 | L | 0,034 | P | 0,019 | Q | 0,0011 |
| N | 0,071 | F | 0,029 | W | 0,015 | Z | 0,0007 |
| R | 0,068 | C | 0,027 | B | 0,014 | ||
| I | 0,063 | M | 0,025 | V | 0,009 |
Таблица 1.2
| Буква | Частота | Буква | Частота | Буква | Частота | Буква | Частота |
| _ | 0,175 | Р | 0,040 | Я | 0,018 | Х | 0,009 |
| О | 0,090 | В | 0,038 | Ы | 0,016 | Ж | 0,007 |
| Е,Ё | 0,072 | Л | 0,035 | З | 0,016 | Ю | 0,006 |
| А | 0,062 | К | 0,028 | Ь,Ъ | 0,014 | Ш | 0,006 |
| И | 0,062 | М | 0,026 | Б | 0,014 | Ц | 0,003 |
| Т | 0,053 | Д | 0,025 | Г | 0,013 | Щ | 0,003 |
| Н | 0,053 | П | 0,023 | Ч | 0,013 | Э | 0,003 |
| С | 0,045 | У | 0,021 | Й | 0,012 | Ф | 0,002 |
Как видно из этих таблиц наиболее часто употребляемая буква в английском тексте – “E”, а наименее «популярная» – “Z”. Соответственно в русском тексте это буквы “О” и ”Ф”.
По аналогии с тем, что было рассмотрено выше, вам должно быть понятно, что частота встречаемости буквы – это вероятность ее появления в определенной позиции текста – Р. Отсюда следует, что информационный вес символа вычисляется по формуле:
i = log2(1/P).
По этой формуле для русской буквы “О” получаем: i=log2(1/0,09)=3,47 бит. А для буквы ‘Ф’: i=log2(1/0,002)=8,97 бит. Разница весьма существенная! Принцип прежний: чем меньше вероятность, тем больше информация.
Для оценки средней информативности символов алфавита c учетом разной вероятности их встречаемости используется формула Клода Шеннона
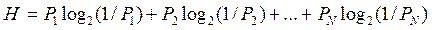
где 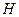 - средняя информативность, Pk - вероятность (частота) встречаемости k-го символа алфавита, N – мощность алфавита. В частном случае, когда
- средняя информативность, Pk - вероятность (частота) встречаемости k-го символа алфавита, N – мощность алфавита. В частном случае, когда
P1 = P2 = … =PN = 1/N
формула К.Шеннона переходит в формулу Р.Хартли (докажите это самостоятельно).
Воспользовавшись данными из таблиц 1.1 и 1.2, по формуле Шеннона можно определить среднюю информативность букв алфавита английского и русского языков. Результаты вычислений для английского языка дают величину 4,09 бит, а для русского – 4,36 бит. При допущении, что все буквы встречаются равновероятно, по формуле Р.Хартли получается для английского языка Hангл=log2(26)=4,70 бит, а для русского языка – Hрус=log2(32)=5 бит. Как видите, учет различия частоты встречаемости букв алфавита приводит к снижению их средней информативности.
Из полученных результатов следует, что и полный информационный объем текста будет разным, если для его вычисления использовать формулы Хартли и Шеннона. Например, текст на русском языке, состоящий из 1000 букв, по Хартли будет содержать 5´1000=5000 бита информации, а по Шеннону: 4,36´1000=4360 бит.
| Вероятность и информация | |
| Вероятность некоторого результата события измеряется частотой его повторений для большого числа событий (в пределе стремящимся к бесконечности) | |
| Содержательный подход | Алфавитный подход |
| P=k/n P – оценка вероятности определенного результата; n – количество повторений события (большое число); k – число повторений данного результата. | P=k/n P – частота повторяемости символа в тексте (оценка вероятности); n – размер текста в символах; k – количество вхождений данного символа в текст. |
| i = log2(1/P) i (бит) – количество информации в сообщении о результате события, вероятность которого равна P | i = log2(1/P) i (бит) – информационный вес символа, частота которого (вероятность) равна P |
Формула Шеннона: 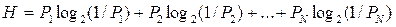 H – средняя информативность символа алфавита, Pi – вероятность символа номер i, N – размер алфавита. H – средняя информативность символа алфавита, Pi – вероятность символа номер i, N – размер алфавита. |








